

自然语言处理学习笔记-lecture07-句法分析01
句法分析(syntactic parsing)的任务就是识别句子的句法结构(syntactic structure)。包含短语结构分析 (Phrase parsing)和依存句法分析 (Dependency parsing)
短语结构分析
英语中的结构歧义随介词短语组合个数的增加而不断加深的,这个组合个数我们称之为开塔兰数(Catalan number,记作)。如果句子中存在这样 (为自然数)个介词短语, 可由下式获得:
基本方法和开源的句法分析器:
基于CFG规则的分析方法:
- 线图分析法 (chart parsing)
- CYK 算法
- Earley (厄尔利)算法
- LR算法/Tomita算法 ......
Top-down: Depth-first/Breadth-first
Bottom-up
基于 PCFG 的分析方法
线性分析图
包括三种策略:自底向上、从上到下、从上到下和从下到上结合
自底向上的 Chart 分析算法
给定一组CFG规则:,句子的词性序列,构造一个线图,一组节点和边的集合,之后建立一个二维表,记录每一条边的起始位置和终止位置,执行操作:查看任意相邻几条边上的词性串是否与某条重写规则的右部相同,如果相同,则增加一条新的边跨越原来相应的边,新增加边上的标记为这条重写规则的头(左部)。重复这个过程,直到没有新的边产生。
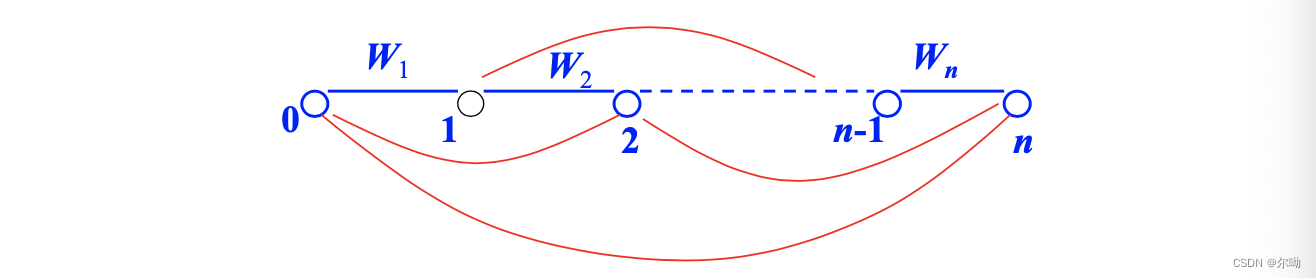
点规则:用于表示规则右部被归约(reduce)的程度。活性边(活动弧):规则右部未被完全匹配,非活性边(非活动弧, 或完成弧):规则右部已被完全匹配
例如给规则集:

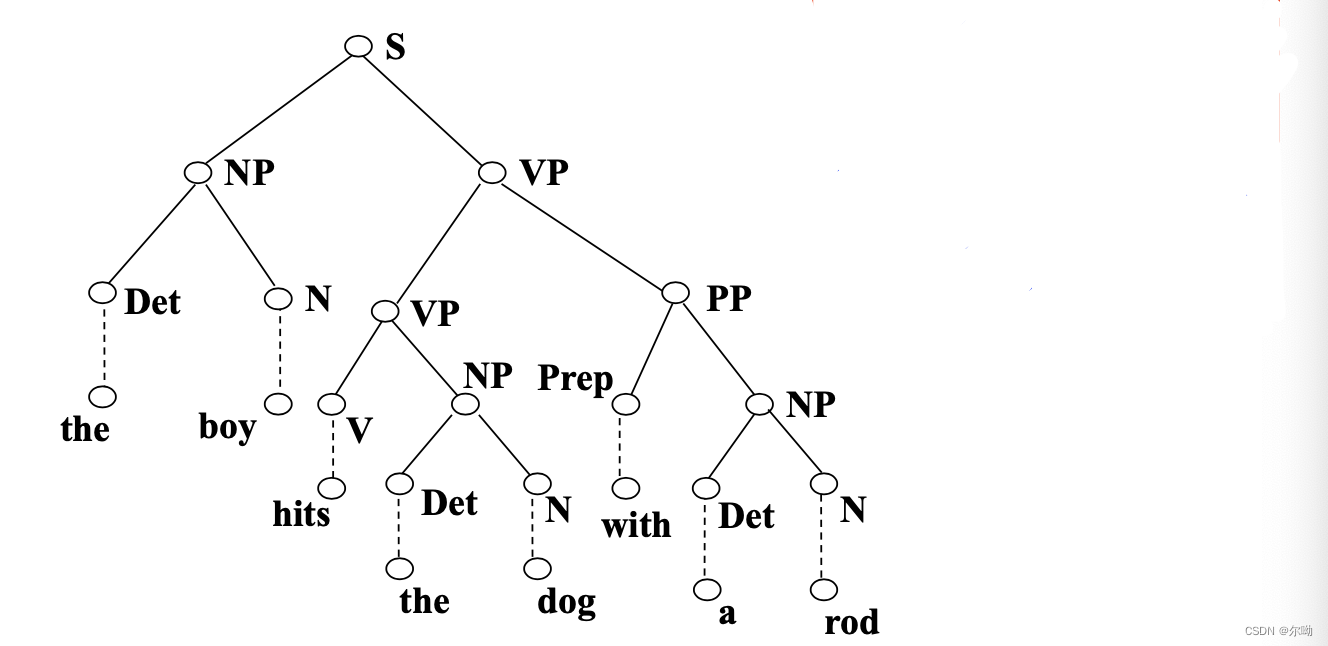
对应的分析结果:再分析之前完成了形态分析和词性标注
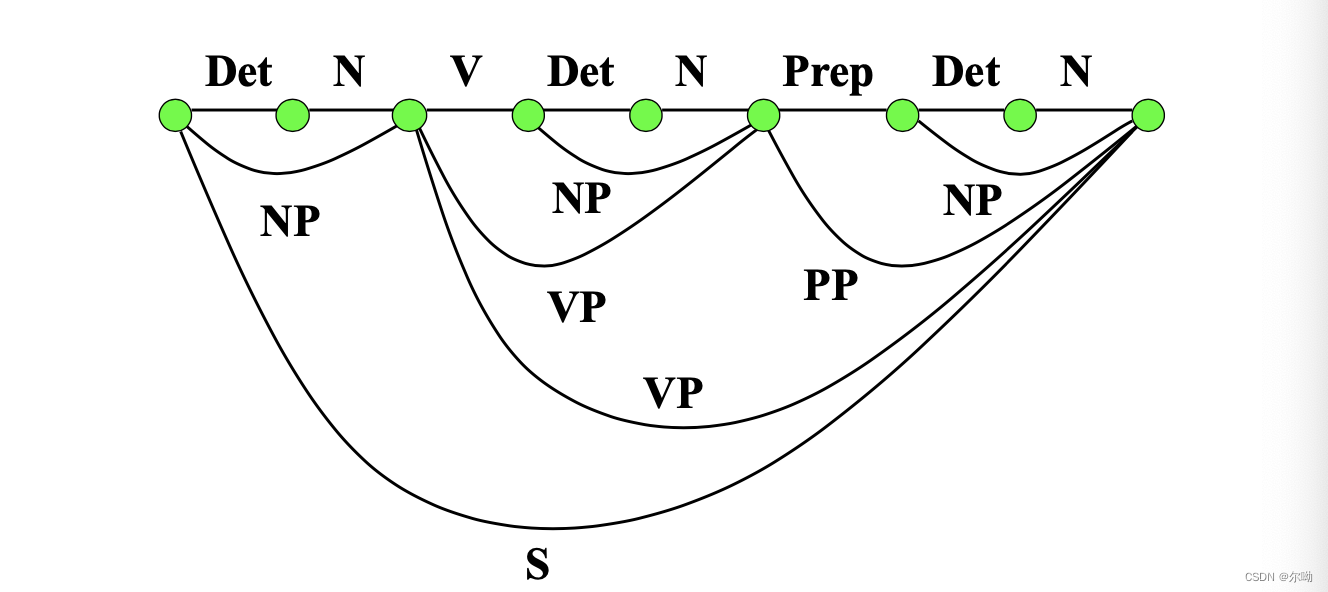
将上面的图的边变为节点,将节点变为边,得到一棵树:
- 线图(Chart):保存分析过程中已经建立的成分(包括终结符和非终结符)、位置(包括起点和终点)。通常以 的数组表示( 为句子包含的词数)。
- 代理表(待处理表)(Agenda):记录刚刚得到的一些重写规则所代表的成分,这些重写规则的右端符号串与输入词性串(或短语标志串)中的一段完全匹配, 通常以栈或线性队列表示。
- 活动边集(ActiveArc):记录那些右端符号串与输入串的某一段相匹配,但还未完全匹配的重写规则,通常以数组或列表存储。
算法描述:从输入串的起始位置到最后位置,循环执行如下步骤:
- 如果待处理表(Agenda)为空,则找到下一个位置上的词,将该词对应的(所有)词类 附以 作为元素放到待处理表中,即。其中, 分别是该词的起始位置和终止位置, 为该词的长度。最多执行的次数为:
- 从 Agenda 中取出一个元素,最多执行的次数为:
- 对于每条规则,将加入活动边集ActiveArc 中,然后调用扩展弧子程序,最多执行的次数为:
扩展弧子程序:
- 将 插入图表(Chart)的 位置中,最多执行的次数为:
- 对于活动边集(ActiveArc)中每个位置为 的点规则,如果该规则具有如下形式: , 如果, 则把 加入到 Chart 中,并给出一个完整的分析结果;否则,则将 加入到Agenda表中。最多执行的次数为:
- 对于每个位置为的点规则: ,则将加入到活动边集中,最多执行的次数为:
算法的时间复杂度分析
设 为输入句子的长度, 为上下文无关文法中的非终结符的数目, 为点规则的状态数目(大于 规则的数目),显然 。因为 Agenda 表中的元素形式为 ,因此, Agenda 表中最大的元素个数为:。由于ActiveArc 中的元素形式为:,所以ActiveArc 表中最大的元素数目为:,Chart 表中的边的形式为:,因此,Chart 表中最大的元素数目为:。由于算法对于长度为 n 的输入句子要执行 n 次循环,因此,Chart 算法最大执行的操作次数为:
优点:算法简单
弱点:算法效率低,需要高质量的规则,分析结果与规则质量密切相关;难以区分歧义结构。
CYK分析算法
Coke-Younger-Kasami (CYK) 算法
- 对Chomsky 文法进行范式化:
- 自下而上的分析方法
- 构造的识别矩阵,为输入句子长度,假设输入句子为构成句子的单词
其中识别矩阵构成:方阵对角线以下全部为0,主对角线以上的元素由文法G的非终结符构成,主对角线上的元素由输入句子的终结符号(单词)构成,构造步骤如下:
- 首先构造主对角线,令 ,然后,从 到,在主对角线的位置上依次放入输入句子 的单词。
- 构造主对角线以上紧靠主对角线的元素,其中,对于输入句子,从开始分析
假设在文法G 的产生式集中有一条规则:则,以此类推,如果有则 - 按平行于主对角线的方向,一层一层的向上填写矩阵的各个元素,其中,如果存在一个正整数,在文法的规则集中有产生式,并且那么将写到矩阵位置上,判断句子由文法所产生的充要条件是
以“他/P 喜欢/V 读/V 书/N”为例:
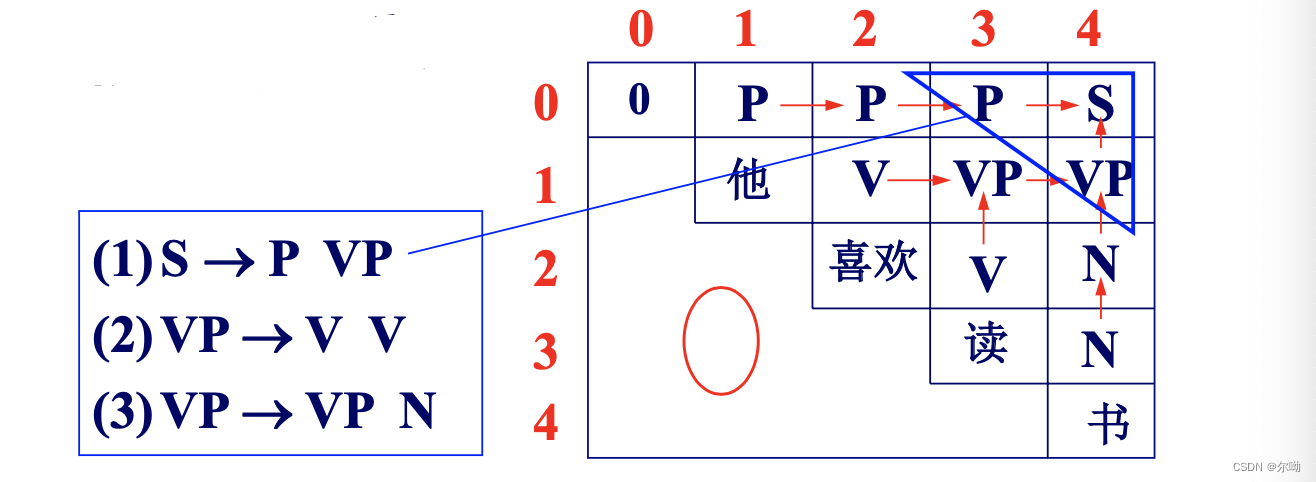
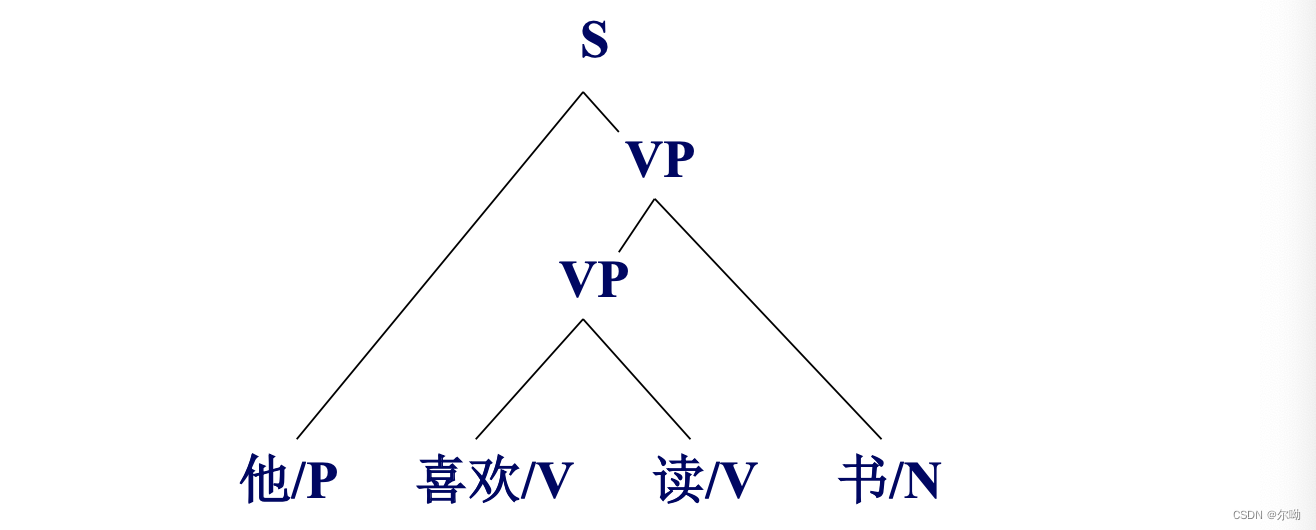
优点:简单易行
弱点:必须对文法进行范式化处理,无法区分歧义
概率上下文无关文法
形式:
约束:
计算分析树概率的基本假设
- 位置不变性:子树的概率与其管辖的词在整个句子中所处的位置无关,即对于任意的 一样
- 上下文无关性:子树的概率与子树管辖范围以外的词无关,即
- 祖先无关性:子树的概率与推导出该子树的祖先结点无关,即
句法分析树的概率计算方法示例:
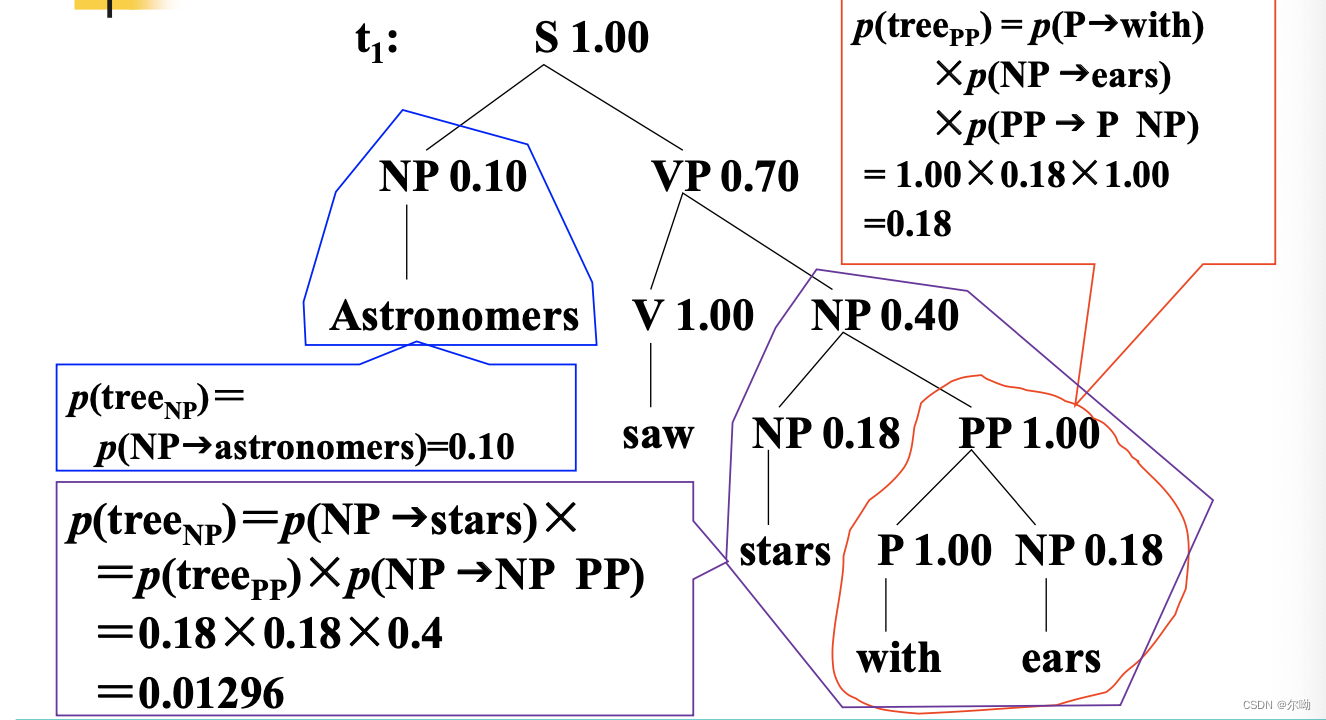
对于给定的句子 ,两棵句法分析树的概率不等,,因此,可以得出结论:分析结果正确的可能性大于。
PCFG的三个问题
- 给定句子和PCFG ,如何快速的计算
- 给定句子和PCFG ,如何快速地选择最佳句法结构树?
- 给定句子和PCFG ,如何调节的参数,使得最大
假设文法的规则只有两种形式:
可以通过范式化处理,使CFG 规则满足上述形式。这种假设的文法形式称为乔姆斯基范式(Chomsky normal form, CNF)。
内向算法或外向算法
解决第一个问题-快速地计算句子的句法树概率
内向算法
基本思想:利用动态规划算法计算由非终结符 A 推导出的某个字串片段的概率,语句的概率即为文法中推导出的字串的概率
计算的递推公式:
内向算法描述:
输入:文法,语句
输出:
- 初始化:
- 归纳计算:重复下列计算:外层循环为
- 终结:
外向算法
定义:外向变量是文法初始符号推导出语句的过程中,到达扩展符号串的概率
表示除了以为根节点的子树以外的概率,其递推公式:
相应的示意图:
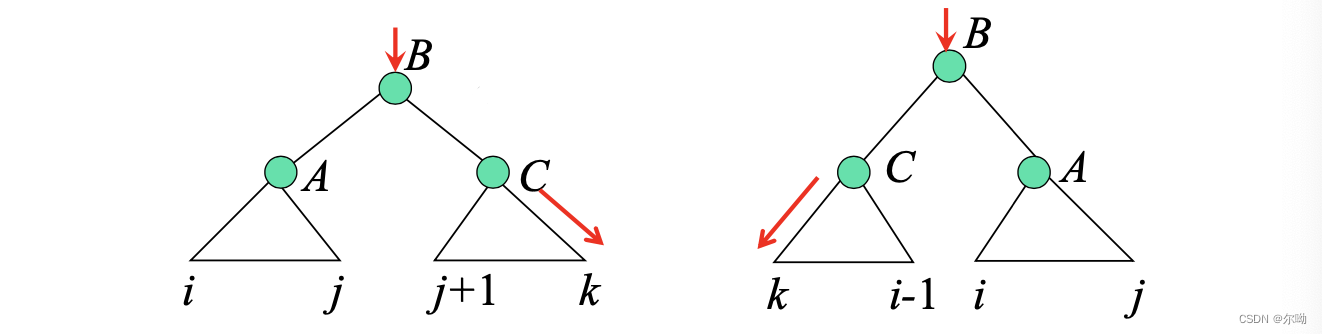
外向算法描述:
输入:PCFG ,语句
输出:
- 初始化:
- 归纳:从到,从到,重复计算:
- 终结:
Viterbi 算法
解决第二个问题-最佳分析结果搜索
Viterbi 变量是由非终结符 推导出语句中子字串的最大概率。变量用于记忆字串的Viterbi 语法分析结果。
Viterbi 算法描述:
输入:文法,语句
输出:
- 初始化:
- 归纳计算:重复下列计算:
- 终结:
内外向算法
解决第三个问题-参数估计
基本思路:如果有大量已标注语法结构的训练语料,则可直接通过计算每个语法规则的使用次数,用最大似然估计方法计算 PCFG 规则的概率参数,即:
多数情况下,没有可利用的标注语料,只好借助 EM (Expectation Maximization) 迭代算法估计PCFG的 概率参数。
初始时随机地给参数赋值,得到语法G0,依据 G0 和训练语料,得到语法规则使用次数的期望值,以期望次数运用于最大似然估计,得到语法参数新的估计值,由此得到新的语法 G1,由 G1 再次得到语法规则的使用次数的期望值,然后又可以重新估计语法参数。循环这个过程,语法参数将收敛于最大似然估计值。
例如给定CFG 和训练数据,语法规则使用次数的期望值为:
类似地,语法规则 的使用次数的期望值为:
G 的参数可由下面的公式重新估计:
其中要么是终结符号,要么是两个非终结符号串,即为乔姆斯基语法范式要求的两种形式。
内外向算法:
- 初始化:随机给,使加和为1,由此得到语法,令
- EM迭代:
E步:由根据上面的求期望值公式得到两个期望值
M步:由M步得到的期望值,重新估计,得到 - 循环:重复EM步骤,直到收敛。
PCFG的优点:可利用概率减少分析过程的搜索空间;可利用概率对概率较小的子树剪枝,加快分析效率;可以定量地比较两个语法的性能。
弱点:分析树的概率计算条件非常苛刻,甚至不够合理。
短语结构分析方法评估
内部评测 (intrinsic evaluation)-对评测方法本身的评测,用于指导句法分析系统及其语法的开发过程。主要指标有:
- 语法的覆盖性 (grammatical coverage)
- 平均分析基数 (average parse base)
- 结构一致性 (structural consistency)
- 排序的一致性 (best-first/ranked consistency)等
对比评测 (comparative evaluation ):用于对比不同系统之间的性能差别,主要评测指标和方法包括:
- 树相似性 (tree similarity)
- 模型的熵 (或困惑度) (entropy/perplexity)
- 语法评估兴趣小组 (grammar evaluation interest group, GIEG)的评测方案等
句法分析器性能评测:目前使用比较广泛的句法分析器评价指标是PARSEVAL测度,三个基本的评测指标:
- 精度(precision):句法分析结果中正确的短语个数所占的比例,即分析结果中与标准分析树(答案)中的短语相匹配的个数占分析结果中所有短语个数的比例
- 召回率(recall):句法分析结果中正确的短语个数占标准分析树中全部短语个数的比例
- F-measure
- 交叉括号数 (crossing brackets):一棵分析树中与其他分析树中边界相交叉的成分个数的平均值。
分析树中除了词性标注符号以外的其他非终结符节点通常采用如下标记格式:XP-(起始位置:终止位置)。其中,XP为短语名称;(起始位置:终止位置)为该节点的跨越范围,起始位置指该节点所包含的子节点的起始位置,终止位置为该节点所包含的子节点的终止位置。在计算PARSEVAL指标时,通常需要计算分析结果与标准分析树之间括号匹配的数目或括号交叉的数目。
例如标准答案:S-(0:11), NP-(0:2), VP-(2:9), VP-(3:9), NP- (4:6), PP-(6:9), NP-(7:9), *NP-(9:10)
系统结果:S-(0:11), NP-(0:2), VP-(2:10), VP-(3:10), NP- (4:10), NP-(4:6), PP-(6:10), NP-(7:10)
只有加粗的短语和标准一样,所以:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异