

模式识别学习笔记- lecture1-绪论
概述
模式:存在于世间和空间中可观察的物体,如果我们可以区别他们是否相同或是否相似,都可以称之为模式。
模式的直观特性:
- 可观察性
- 可区分性
- 相似性
模式识别:对周围物体的认识、人的识别、声音的辨别、气味的分辨
数据聚类
目标:用某种相似性度量的方法见原始数据组成有意义的和有用的各种数据集
是一种非监督学习的方法,解决方案是数据驱动的
统计分类
基于概率统计模型得到各类别的特征向量的分布,以取得分类的方法;
特征向量分布的获得是基于一个类别已知的训练样本集;
是一种监督分类的方法,分类器是概念驱动的;
结构模式识别
该方法通过考虑识别对象的各部分之间的联系来达到识别分类的目的;
识别采用结构匹配的形式,通过计算一个匹配程度值(matching score)来评估一个未知的对象或位未知对象某些部分与某种典型模式的关系如何;
当制定出来一组可以描述对象部分之间关系的规则后,可以应用一种特殊的结构模式识别方法-句法模式识别,来检查一个模式基元的序列是否遵守某种规则,即句法规则或语法;
神经网络
由一系列互相联系的、相同的单元(神经元)组成,相互间的联系可以在不同的神经元之间传递增强或抑制信号;
增强或抑制是通过调整神经元相互间联系的权重系数来实现;
神经网络可以实现监督和非监督学习条件下的分类;
监督学习
监督学习是从有标记的训练数据来推断或建立一个模型
无监督学习
无监督学习与监督学习的不同之处在于,没有任何训练样本,需要直接对数据进行建模,寻找数据的内在结构及规律,如类别和聚类;
半监督学习
利用少量的标注样本和大量的未标注样本进行训练和分类
增强学习
机器人选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号反馈回来,机器人根据强化信号和环境当前状态再选择下一个动作;
集成学习
ensemble learning指联合训练多个弱分类器并通过集成策略将弱分类器组合使用;
常见的集成策略有:boosting, bagging, random subspace, stacking;
常见的算法主要有:决策树、随机森林、adaboost, GBDT, DART等;
深度学习
源于人工神经网络的研究,通过层次化模型结构可从低层原始特征中逐渐抽象出高层次的语义特征;
元学习
meta learning学会学习,利用以往的知识经验来指导新任务的学习,具有学会学习的能力
多任务学习
联合训练多个学习任务
多标记学习
处理的数据集中的每个样本可同时存在多个类标
对抗学习
系统构成
模式识别系统
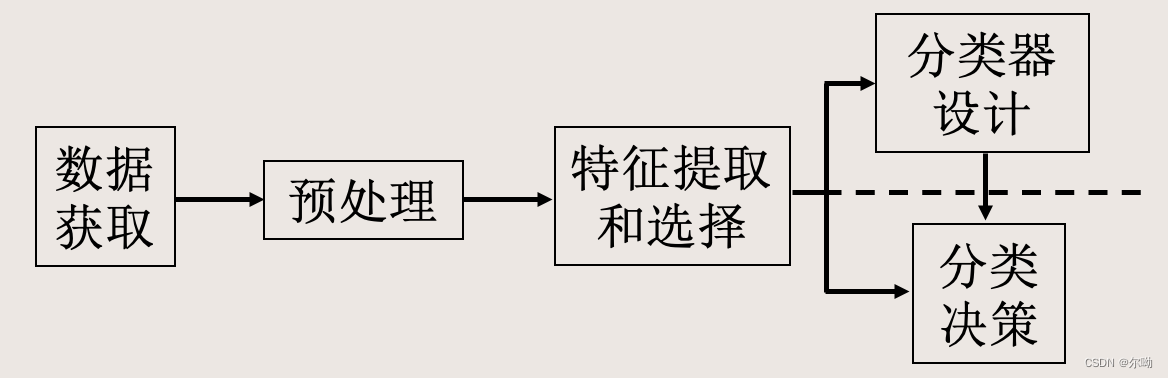
机器学习



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异