

模式识别学习笔记-lecture2-统计判别2
正态分布模式的贝叶斯分类器
当已知或有理由设想类概率密度函数 P ( x ∣ ω i ) P(x|\omega_i) P(x∣ωi)是多变量的正态分布时,贝叶斯分类器可以导出一些简单的判别函数
M M M种模式类别的多变量正态类密度函数
具有
M
M
M种模式类别的多变量正态类密度函数为:
P
(
x
∣
ω
i
)
=
1
(
2
π
)
n
2
∣
C
i
∣
1
2
e
x
p
{
−
1
2
(
x
−
m
i
)
T
C
i
−
1
(
x
−
m
i
)
}
i
=
1
,
2
,
⋯
,
M
P(x|\omega_i)=\frac{1}{(2\pi)^{\frac{n}{2}}|C_i|^{\frac{1}{2}}}exp \left\{ -\frac{1}{2}(x - m_i)^TC_i^{-1}(x - m_i) \right\}\ i = 1,2,\cdots,M
P(x∣ωi)=(2π)2n∣Ci∣211exp{−21(x−mi)TCi−1(x−mi)} i=1,2,⋯,M
其中每一类模式的分布密度都完全被其均值向量m_i和协方差矩阵
C
i
C_i
Ci所规定,其定义为:
m
i
=
E
i
{
x
}
C
i
=
E
i
{
(
x
−
m
i
)
(
x
−
m
i
)
T
}
miCi=Ei{x}=Ei{(x−mi)(x−mi)T}
E
i
{
x
}
E_i\{x\}
Ei{x}表示对类别属于
ω
i
\omega_i
ωi的模型的数学期望。
在上述公式中,
n
n
n为模式向量的维数,
∣
C
i
∣
|C_i|
∣Ci∣为矩阵
C
i
C_i
Ci的行列式,协方差矩阵
C
i
C_i
Ci是对称的正定矩阵,其对角线上的元素
C
k
k
C_{kk}
Ckk是模式向量第
k
k
k个元素的方差,非对角线上的元素
C
j
k
C_{jk}
Cjk是
x
x
x的第
j
j
j个分量
x
j
x_j
xj和第
k
k
k个分量
x
k
x_k
xk的协方差。当
x
j
x_j
xj和
x
k
x_k
xk统计独立时,
C
j
k
=
0
C_{jk}=0
Cjk=0。当协方差矩阵的全部非对角线上的元素都为0时,多变量正态类密度函数可简化为
n
n
n个单变量正态类密度函数的乘积。
已知类别
ω
i
\omega_i
ωi的判别函数可写成如下形式:
d
i
(
x
)
=
P
(
x
∣
ω
i
)
P
(
ω
i
)
,
i
=
1
,
2
,
⋯
,
M
d_i(x)=P(x|\omega_i)P(\omega_i), \ i=1,2,\cdots,M
di(x)=P(x∣ωi)P(ωi), i=1,2,⋯,M
对于正态密度函数,可取自然对数的形式以方便计算(因为自然对数是单调递增的,取对数后不影响相应的分类性能),则有:
d
i
(
x
)
=
l
n
[
P
(
x
∣
ω
i
)
]
+
l
n
P
(
ω
i
)
,
i
=
1
,
2
,
⋯
,
M
d_i(x)=ln[P(x|\omega_i)] + lnP(\omega_i), \ i=1,2,\cdots,M
di(x)=ln[P(x∣ωi)]+lnP(ωi), i=1,2,⋯,M
代入正态类密度函数,有:
d
i
(
x
)
=
l
n
P
(
ω
i
)
−
n
2
l
n
(
2
π
)
−
1
2
l
n
∣
C
i
∣
−
1
2
(
x
−
m
i
)
T
C
i
−
1
(
x
−
m
i
)
,
i
=
1
,
2
,
⋯
,
M
d_i(x) = lnP(\omega_i)-\frac{n}{2}ln(2\pi)-\frac{1}{2}ln|C_i|-\frac{1}{2}(x - m_i)^TC_i^{-1}(x - m_i),\ i=1,2,\cdots,M
di(x)=lnP(ωi)−2nln(2π)−21ln∣Ci∣−21(x−mi)TCi−1(x−mi), i=1,2,⋯,M
去掉和
i
i
i无关的项(并不影响分类结果),有:
d
i
(
x
)
=
l
n
P
(
ω
i
)
−
1
2
l
n
∣
C
i
∣
−
1
2
(
x
−
m
i
)
T
C
i
−
1
(
x
−
m
i
)
,
i
=
1
,
2
,
⋯
,
M
d_i(x)=lnP(\omega_i)-\frac{1}{2}ln|C_i|-\frac{1}{2}(x - m_i)^TC_i^{-1}(x - m_i),\ i=1,2,\cdots,M
di(x)=lnP(ωi)−21ln∣Ci∣−21(x−mi)TCi−1(x−mi), i=1,2,⋯,M
即为正态分布模式的贝叶斯判别函数,判别函数是一个超二次曲面
两类问题且其类模式都是正态分布的特殊情况
当
C
1
≠
C
2
C_1 \neq C_2
C1=C2时,两类模式的正态分布为:
P
(
x
∣
ω
1
)
P(x|\omega_1)
P(x∣ω1)表示为
N
(
m
1
,
C
1
)
N(m_1,C_1)
N(m1,C1),
P
(
x
∣
ω
2
)
P(x|\omega_2)
P(x∣ω2)表示为
N
(
m
2
,
C
2
)
N(m_2,C_2)
N(m2,C2),
ω
1
,
ω
2
\omega_1, \omega_2
ω1,ω2两类的判别函数对应为:
d
1
(
x
)
=
l
n
P
(
ω
1
)
−
1
2
l
n
∣
C
1
∣
−
1
2
(
x
−
m
1
)
T
C
1
−
1
(
x
−
m
1
)
d
2
(
x
)
=
l
n
P
(
ω
2
)
−
1
2
l
n
∣
C
2
∣
−
1
2
(
x
−
m
2
)
T
C
2
−
1
(
x
−
m
2
)
d
1
(
x
)
−
d
2
(
x
)
=
{
>
0
x
∈
ω
1
<
0
x
∈
ω
1
d_1(x) = lnP(\omega_1)-\frac{1}{2}ln|C_1|-\frac{1}{2}(x - m_1)^TC_1^{-1}(x - m_1) \\ d_2(x) = lnP(\omega_2)-\frac{1}{2}ln|C_2|-\frac{1}{2}(x - m_2)^TC_2^{-1}(x - m_2) \\ d_1(x)-d_2(x)=
d1(x)=lnP(ω1)−21ln∣C1∣−21(x−m1)TC1−1(x−m1)d2(x)=lnP(ω2)−21ln∣C2∣−21(x−m2)TC2−1(x−m2)d1(x)−d2(x)={>0<0x∈ω1x∈ω1
判别界面是
x
x
x的二次型方程,当
x
x
x是二维模式时,判别界面为二次曲线,如椭圆、圆、抛物线或双曲线等
当
C
1
=
C
2
=
C
C_1 = C_2 = C
C1=C2=C时,有:
d
i
(
x
)
=
l
n
P
(
ω
i
)
−
1
2
l
n
∣
C
∣
−
1
2
x
T
C
−
1
x
+
1
2
x
T
C
−
1
m
i
+
1
2
m
i
T
C
−
1
x
−
1
2
m
i
T
C
−
1
m
i
,
i
=
1
,
2
d_i(x)=lnP(\omega_i)-\frac{1}{2}ln|C|-\frac{1}{2}x^TC^{-1}x+\frac{1}{2}x^TC^{-1}m_i + \frac{1}{2}m_i^TC^{-1}x - \frac{1}{2}m_i^TC^{-1}m_i,\ i = 1,2
di(x)=lnP(ωi)−21ln∣C∣−21xTC−1x+21xTC−1mi+21miTC−1x−21miTC−1mi, i=1,2
因
C
C
C为对称矩阵,上式可简化为:
d
i
(
x
)
=
l
n
P
(
ω
i
)
−
1
2
l
n
∣
C
∣
−
1
2
x
T
C
−
1
x
+
m
i
T
C
−
1
x
−
1
2
m
i
T
C
−
1
m
i
,
i
=
1
,
2
d_i(x)=lnP(\omega_i)-\frac{1}{2}ln|C|-\frac{1}{2}x^TC^{-1}x + m_i^TC^{-1}x - \frac{1}{2}m_i^TC^{-1}m_i,\ i = 1,2
di(x)=lnP(ωi)−21ln∣C∣−21xTC−1x+miTC−1x−21miTC−1mi, i=1,2
由此可导出类别
ω
1
\omega_1
ω1和
ω
2
\omega_2
ω2间的判别界面为:
d
1
(
x
)
−
d
2
(
x
)
=
l
n
P
(
ω
1
)
−
l
n
P
(
ω
2
)
+
(
m
1
−
m
2
)
T
C
−
1
x
−
1
2
m
1
T
C
−
1
m
1
+
1
2
m
2
T
C
−
1
m
2
=
0
d_1(x)-d_2(x) = lnP(\omega_1)-lnP(\omega_2)+(m_1-m_2)^TC^{-1}x- \frac{1}{2}m_1^TC^{-1}m_1 + \frac{1}{2}m_2^TC^{-1}m_2 = 0
d1(x)−d2(x)=lnP(ω1)−lnP(ω2)+(m1−m2)TC−1x−21m1TC−1m1+21m2TC−1m2=0
判别界面是
x
x
x的线性函数,为一超平面,当
x
x
x是二维时,判别界面为一直线
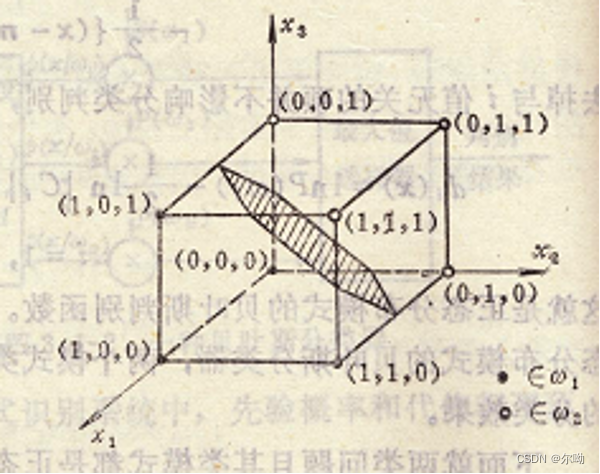
例题
P
(
ω
1
)
=
P
(
ω
2
)
=
1
2
P(\omega_1) = P(\omega_2) = \frac{1}{2}
P(ω1)=P(ω2)=21,求其判别界面
模式的均值向量
m
i
m_i
mi和协方差矩阵
C
i
C_i
Ci可用下式估计:
m
1
=
1
N
i
∑
j
=
1
N
i
x
i
j
i
=
1
,
2
C
i
=
1
N
i
∑
j
=
1
N
i
(
x
i
j
−
m
i
)
(
x
i
j
−
m
i
)
T
i
=
1
,
2
m1Ci=Ni1j=1∑Nixij i=1,2=Ni1j=1∑Ni(xij−mi)(xij−mi)T i=1,2
其中
N
i
N_i
Ni为类别
ω
i
\omega_i
ωi中模式的数目,
x
i
j
x_{ij}
xij代表在第
i
i
i个类别中的第
j
j
j个模式,由上式可求出:
m
1
=
1
4
(
3
1
1
)
T
m
2
=
1
4
(
1
3
3
)
T
C
1
=
C
2
=
C
=
1
16
(
3
1
1
1
3
−
1
1
−
1
3
)
,
C
−
1
=
4
(
2
−
1
−
1
−
1
2
1
−
1
1
2
)
m_1 = \frac{1}{4}(3\ 1\ 1)T \\ m_2 = \frac{1}{4}(1\ 3\ 3)^T \\ C_1 = C_2 = C = \frac{1}{16} \left( \right),\ C^{-1} = 4 \left( \right)
m1=41(3 1 1)Tm2=41(1 3 3)TC1=C2=C=161⎝
⎛31113−11−13⎠
⎞, C−1=4⎝
⎛2−1−1−121−112⎠
⎞
设
P
(
ω
1
)
=
P
(
ω
2
)
=
1
2
P(\omega_1)=P(\omega_2)=\frac{1}{2}
P(ω1)=P(ω2)=21,因
C
1
=
C
2
C_1=C_2
C1=C2,则判别界面为:
d
1
(
x
)
−
d
2
(
x
)
=
(
m
1
−
m
2
)
T
C
−
1
x
−
1
2
m
1
T
C
−
1
m
1
+
1
2
m
2
T
C
−
1
m
2
=
8
x
1
−
8
x
2
−
8
x
3
+
4
=
0
d1(x)−d2(x)=(m1−m2)TC−1x−21m1TC−1m1+21m2TC−1m2=8x1−8x2−8x3+4=0
均值向量和协方差矩阵的参数估计
在贝叶斯分类器中,构造分类器需要知道类概率密度函数 P ( x ∣ ω i ) P(x|\omega_i) P(x∣ωi),如果按照先验知识已经知道其分布,则只需要知道分布的参数即可
将参数作为非随机变量
均值和协方差矩阵的估计量定义
设模式的类概率密度函数为
p
(
x
)
p(x)
p(x),则其均值向量定义为:
m
=
E
(
x
)
=
∫
x
x
P
(
x
)
d
x
m = E(x) = \int_xxP(x)dx
m=E(x)=∫xxP(x)dx
其中,
x
=
(
x
1
,
x
2
,
⋯
,
x
n
)
T
,
m
=
(
m
1
,
m
2
,
⋯
,
m
n
)
T
x = (x_1,x_2,\cdots,x_n)^T,m = (m_1,m_2,\cdots,m_n)^T
x=(x1,x2,⋯,xn)T,m=(m1,m2,⋯,mn)T。
若以样本的平均值作为均值向量的近似值,则均值估计量
m
^
\hat{m}
m^为:
m
^
=
1
N
∑
j
=
1
N
x
j
\hat{m} = \frac{1}{N}\sum_{j=1}^Nx_j
m^=N1j=1∑Nxj
其中
N
N
N为样本的数目。
协方差矩阵为:
C
=
(
c
11
c
12
⋯
c
1
n
c
21
c
22
⋯
c
2
n
⋮
⋮
⋱
⋮
c
n
1
c
n
2
⋯
c
n
n
)
C = \left( \right)
C=⎝
⎛c11c21⋮cn1c12c22⋮cn2⋯⋯⋱⋯c1nc2n⋮cnn⎠
⎞
其每个元素
c
l
k
c_{lk}
clk定义为:
c
l
k
=
E
{
(
x
l
−
m
l
)
(
x
k
−
m
k
)
}
=
∫
−
∞
∞
∫
−
∞
∞
(
x
l
−
m
l
)
(
x
k
−
m
k
)
P
(
x
l
,
x
k
)
d
x
l
d
x
k
clk=E{(xl−ml)(xk−mk)}=∫−∞∞∫−∞∞(xl−ml)(xk−mk)P(xl,xk)dxldxk
其中,
x
l
,
x
k
,
m
l
,
m
k
x_l,x_k,m_l,m_k
xl,xk,ml,mk分别是
x
,
m
x,m
x,m的第
l
,
k
l,k
l,k个分量。
协方差矩阵写成向量形式为:
C
=
E
{
(
x
−
m
)
(
x
−
m
)
T
}
=
E
{
x
x
T
}
−
m
m
T
C = E\{(x - m)(x - m)^T\} = E\{xx^T\}-mm^T
C=E{(x−m)(x−m)T}=E{xxT}−mmT
协方差矩阵的估计量(当
N
≫
1
N \gg 1
N≫1为:
C
^
≈
1
N
∑
k
=
1
N
(
x
k
−
m
^
)
(
x
k
−
m
^
)
T
\hat{C} \approx \frac{1}{N}\sum^N_{k=1}(x_k-\hat{m})(x_k-\hat{m})^T
C^≈N1k=1∑N(xk−m^)(xk−m^)T
这里样本模式总体为
{
x
1
,
x
2
,
⋯
,
x
k
,
⋯
,
x
N
}
\{x_1,x_2,\cdots,x_k,\cdots,x_N\}
{x1,x2,⋯,xk,⋯,xN},为因为计算估计量时没有真实的均值向量
m
m
m可用,只能用均值向量的估计量来代替,会存在偏差。
均值和协方差矩阵估计量的迭代运算形式
假设已经计算了
N
N
N个样本的均值估计量,若再加上一个样本,其新的估计量
m
^
(
N
+
1
)
\hat{m}(N+1)
m^(N+1)为:
m
^
(
N
+
1
)
=
1
N
+
1
∑
j
=
1
N
+
1
x
j
=
1
N
+
1
[
∑
j
=
1
N
x
j
+
x
N
+
1
]
=
1
N
+
1
[
N
m
^
(
N
)
+
x
N
+
1
]
\hat{m}(N+1) = \frac{1}{N+1}\sum_{j=1}^{N+1}x_j = \frac{1}{N+1} \left[ \sum_{j=1}^Nx_j+x_{N+1} \right] = \frac{1}{N+1}\left[N\hat{m}(N) + x_{N+1}\right]
m^(N+1)=N+11j=1∑N+1xj=N+11[j=1∑Nxj+xN+1]=N+11[Nm^(N)+xN+1]
其中
m
^
(
N
)
\hat{m}(N)
m^(N)为从
N
N
N个样本计算得到的估计量,迭代的第一步应取
m
^
(
1
)
=
x
1
\hat{m}(1)=x_1
m^(1)=x1。
协方差矩阵的估计量的迭代运算与上述相似,取
C
^
(
N
)
\hat{C}(N)
C^(N)表示
N
N
N个样本时的估计量为:
C
^
(
N
)
=
1
N
∑
j
=
1
N
x
j
x
j
T
−
m
^
(
N
)
m
^
T
(
N
)
\hat{C}(N) = \frac{1}{N}\sum_{j=1}^Nx_jx_j^T - \hat{m}(N)\hat{m}^T(N)
C^(N)=N1j=1∑NxjxjT−m^(N)m^T(N)
加入一个样本,则:
C
^
(
N
+
1
)
=
1
N
+
1
∑
j
=
1
N
+
1
x
j
x
j
T
−
m
^
(
N
+
1
)
m
^
T
(
N
+
1
)
=
1
N
+
1
[
∑
j
=
1
N
x
j
x
j
T
+
x
N
+
1
x
N
+
1
T
]
−
m
^
(
N
+
1
)
m
^
T
(
N
+
1
)
=
1
N
+
1
[
N
C
^
(
N
)
+
N
m
^
(
N
)
m
^
T
(
N
)
+
x
N
+
1
x
N
+
1
T
]
−
1
(
N
+
1
)
2
[
N
m
^
(
N
)
+
x
N
+
1
]
[
N
m
^
(
N
)
+
x
N
+
1
]
T
C^(N+1)=N+11j=1∑N+1xjxjT−m^(N+1)m^T(N+1)=N+11[j=1∑NxjxjT+xN+1xN+1T]−m^(N+1)m^T(N+1)=N+11[NC^(N)+Nm^(N)m^T(N)+xN+1xN+1T]−(N+1)21[Nm^(N)+xN+1][Nm^(N)+xN+1]T
其中
C
^
(
1
)
=
x
1
x
1
T
−
m
^
(
1
)
m
^
T
(
1
)
=
0
\hat{C}(1) = x_1x_1^T - \hat{m}(1)\hat{m}^T(1)=0
C^(1)=x1x1T−m^(1)m^T(1)=0是零矩阵
将参数看做随机变量
设
{
x
1
,
x
2
,
⋯
,
x
N
}
\{x_1,x_2,\cdots,x_N\}
{x1,x2,⋯,xN}为
N
N
N个用于估计一未知参数
θ
\theta
θ的密度函数的样本,
x
i
x_i
xi被一个接一个的逐次给出,于是用贝叶斯定理,可以得到在给定了
x
1
,
x
2
,
⋯
,
x
N
x_1,x_2,\cdots,x_N
x1,x2,⋯,xN之后,
θ
\theta
θ的后延概率密度的迭代表示式为:
P
(
θ
∣
x
1
,
⋯
,
x
N
)
=
P
(
x
N
∣
θ
,
x
1
,
⋯
,
x
N
−
1
)
P
(
θ
∣
x
1
,
⋯
,
x
N
−
1
)
P
(
x
N
∣
x
1
,
⋯
,
x
N
−
1
)
P(\theta|x_1,\cdots,x_N)=\frac{P(x_N|\theta,x_1,\cdots,x_{N-1})P(\theta|x_1,\cdots,x_{N-1})}{P(x_N|x_1,\cdots,x_{N-1})}
P(θ∣x1,⋯,xN)=P(xN∣x1,⋯,xN−1)P(xN∣θ,x1,⋯,xN−1)P(θ∣x1,⋯,xN−1)
其中对于
P
(
θ
∣
x
1
,
⋯
,
x
N
)
P(\theta|x_1,\cdots,x_N)
P(θ∣x1,⋯,xN)而言,
P
(
θ
∣
x
1
,
⋯
,
x
N
−
1
)
P(\theta|x_1,\cdots,x_{N-1})
P(θ∣x1,⋯,xN−1)是它的先验概率,当加入了新的样本
x
N
x_N
xN后,得到修正之后的新的概率密度
P
(
θ
∣
x
1
,
⋯
,
x
N
)
P(\theta|x_1,\cdots,x_N)
P(θ∣x1,⋯,xN)。如此一步步向前推,则
P
(
θ
)
P(\theta)
P(θ)是最初的先验概率密度,当读入第一个样本
x
1
x_1
x1时,经过贝叶斯定理计算,可得到后验概率密度
P
(
θ
∣
x
1
)
P(\theta|x_1)
P(θ∣x1)。以此为新的一步,将
P
(
θ
∣
x
1
)
P(\theta|x_1)
P(θ∣x1)作为第二部计算的先验概率密度,读入样本
x
2
x_2
x2,又得到第二步的后验概率密度
P
(
θ
∣
x
1
,
x
2
)
P(\theta|x_1,x_2)
P(θ∣x1,x2),……,以此可以算出最终的后延概率密度
P
(
θ
∣
x
1
,
⋯
,
x
N
)
P(\theta|x_1,\cdots,x_N)
P(θ∣x1,⋯,xN),从而得到最终的结果。
这里需要知道最初始的概率密度
P
(
θ
)
P(\theta)
P(θ)和全概率
P
(
x
N
∣
x
1
,
⋯
,
x
N
−
1
)
P(x_N|x_1,\cdots,x_{N-1})
P(xN∣x1,⋯,xN−1),全概率可以通过下式算出:
P
(
x
N
∣
x
1
,
⋯
,
x
N
−
1
)
=
∫
x
P
(
x
N
∣
θ
,
x
1
,
⋯
,
x
N
−
1
)
P
(
θ
∣
x
1
,
⋯
,
x
N
−
1
)
d
θ
P(x_N|x_1,\cdots,x_{N-1}) = \int_xP(x_N|\theta,x_1,\cdots,x_{N-1})P(\theta|x_1,\cdots,x_{N-1})d\theta
P(xN∣x1,⋯,xN−1)=∫xP(xN∣θ,x1,⋯,xN−1)P(θ∣x1,⋯,xN−1)dθ
这一个值和未知量
θ
\theta
θ无关,可以认为是一个定值。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix