
深度学习与强化学习的两大联姻:DQN与DDPG的对比分析
深度学习与强化学习的两大联姻:DQN与DDPG的对比分析
作者:Xingzhe.AI
来自:行者AI
引言
Q学习(Q-Learning)算法是提出时间很早的一种异策略的时序差分学习方法;DQN则是利用神经网络对Q-Learning中的值函数进行近似,并针对实际问题作出改进的方法;而DDPG则可以视为DQN对连续型动作预测的一个扩展;本文将从定义对比分析DQN和DDPG,更好地理解二者的算法区别与联系。
本文首先通过简介DQN和DDPG涉及的常见概念,接着从DQN开始分析理解其算法流程,然后进一步地分析DDPG,最后总结二者的区别与联系。本文主要分为以下两个部分:
(1)相关概念简介
(2)DQN的算法分析
(3)DDPG的算法分析
1、相关概念简介
DQN和DDPG处理的问题不同,DQN用于处理离散动作问题,而DDPG则是在其基础上扩展用于处理连续动作问题;所以首先我们需要明白连续型动作和离散型动作的区别,以及二者在工程上是如何实现的。
1.1、离散动作
简单的理解,离散动作是可以被分类的动作,比如向上、向下、开火、停火等动作;在实际工程中,我们使用分类类型的激活函数去表示它们,比如softmax:

如上图所示,输入x经过任意神经网络后,最后一层网络层使用softmax激活函数,将网络输出分为n个动作类;这样就可以输出离散的动作了。
1.2、连续动作
离散动作是可被分类的动作,那么连续动作就是一个连续的值,比如距离、角度、力度等表示确切的值。连续动作不可分类,因此在实际工程中,我们使用返回值类型的激活函数去表示它们,比如tanh:

如上图所示,输入x经过任意神经网络后,最后一层网络层使用tanh激活函数,将网络输出为一个区间化的值value;这样就可以输出连续的动作了。
2、DQN
2.1、DQN面临的问题
DQN是利用神经网络对Q-Learning中的值函数进行近似,并针对实际问题作出改进的方法。但是我们并不能进行简单的替代,比如定义一个分类神经网络:
然后在定义一个类似Q-learning的loss函数,比如:\(Q(s, a) \leftarrow Q(s, a)+\alpha\left(r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right)\),然后再直接进行优化。这样的方式是行不通的。
在实际的工程中,DQN的实现会遇到许多困难,其中最显著的就是:
(1)样本利用率低;
(2)训练得到的value值不稳定;
其中问题(1)是序列决策的通病,由于序列决策具有严密的上下文联系,因此一段很长的样本只能算一个样本,从而导致了样本利用率低。
问题(2)是由于网络输出的Q值会参与动作action的选择,而选择的动作与环境交互后产生新的状态继续送入Q网络训练;这造成了网络参数的输出目标会继续参与网络参数的训练。这导致了Q网络输出不稳定。
2.2、解决方式
面对以上两个问题,DQN分别采用了以下两种方式解决:
(1)经验回放(Experience Replay),即构建一个经验池(Replay Buffer)来去除数据相关性;经验池是由智能体最近的经历组成的数据集。
(2)目标网络冻结(Freezing Target Networks),即在一个时间段内(或者说固定步数内)固定目标中的参数,来稳定学习目标。
整个DQN的功能结构可以用下图表示:
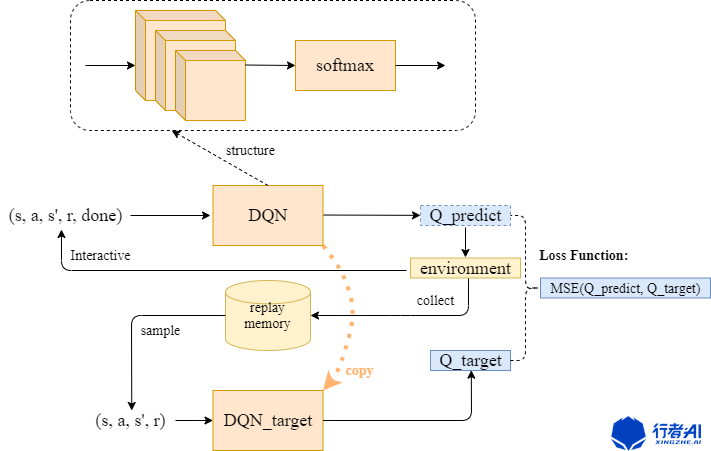
首先向Q网络中输入由动作、状态、奖励和结束标志组成的数据,网络输出一个预测值Q_predict,接着根据该值选择动作action传入环境中进行交互,然后得到新的状态值s',继续送入训练。
同时,每次与环境交互的结果也会存入固定长度的经验池中;每隔C步再从Q网络复制一个结构和参数相同的Target_Q网络,用来稳定输出目标,Target_Q网络从经验池中采样数据,输出一个稳定的目标值Q_target = \(r+\gamma Q_{target}\left(\boldsymbol{s}, \boldsymbol{s}^{\prime}, \boldsymbol{a}, \boldsymbol{r}\right)\),其中\(r\)为奖励函数值,\(\gamma\)是奖励的折扣率,\(Q_{target}\left(\boldsymbol{s}, \boldsymbol{s}^{\prime}, \boldsymbol{a}, \boldsymbol{r}\right)\)是Target_Q网络的输出值。
整个DQN的loss函数直接取两个预测值Q_predict和Q_target的均方误差。
详细的算法流程如下[1]:

3、DDPG
在已知了DQN算法的基础上,再来看DDPG就很简单了。本质上DDPG思路没变,但是应用变化了;DDPG相比于DQN主要是解决连续型动作的预测问题。通过上面的简介,我们可以知道,动作是连续还是离散,在实现上的区别仅在于最后激活函数的选择上。因此。DDPG在继承了DQN的算法上,作出了一些改进。
直接上算法结构:
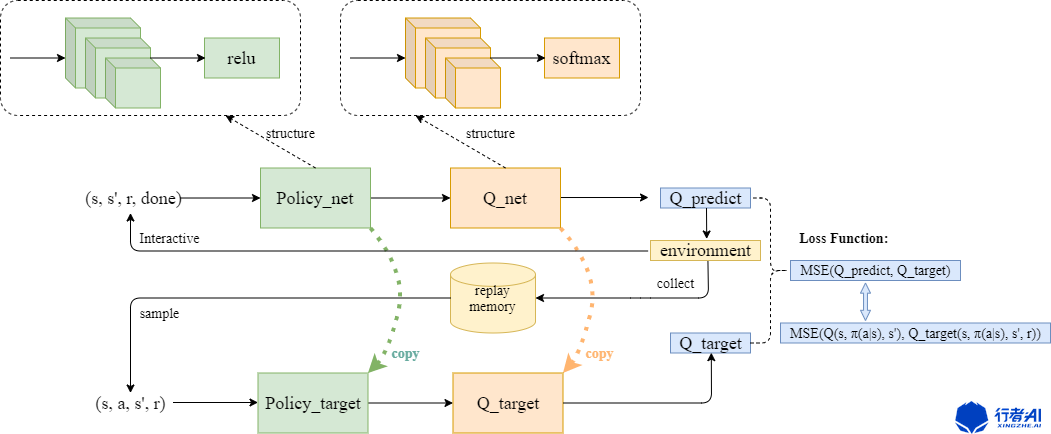
对比DQN的算法结构图,不难发现:DDPG在DQN的基础上增加了一个Policy网络及其Policy_target网络,用来输出一个连续值;这个连续值其实就是连续动作action。剩下的思路和DQN几乎一样。
不同之处在于,最后的loss函数虽然仍是求两个预测值Q_predict和Q_target的均方误差,但是由于Q_predict和Q_target的值是需要Policy网络及其Policy_target网络的输出分别求得的。所以需要在Q_predict和Q_target中内嵌入两个策略网络的loss函数,如上图所示。
对比DQN,将其算法稍作更改就可以得到一个较为详细的DDPG算法流程:

说完了DDPG相较于DQN的扩展,再说说继承。显然的,DDPG继承了经验回放(Experience Replay) 和 目标网络冻结(Freezing Target Networks) 两种方式用来解决相同的问题。
4、总结
本文以对比的视角分别分析了DQN和DDPG两种算法,可以看出:
(1)二者都采用了经验回放(Experience Replay) 和 目标网络冻结(Freezing Target Networks)两种方式去解决样本、目标值不稳定的问题。
(2)二者的算法结构十分相似,都是相同的流程,只是DDPG在DQN的基础上多了一些Policy系列网络的操作。
(3)二者的loss函数本质上是相同的,只是DDPG加入了Policy网络用来输出连续动作值,因此需要再向原MSE中嵌入Policy网络的loss函数。
综上,本文得出了DDPG实质上是DQN的一种在连续动作上的扩展算法这一结论。通过对比也可以看出,DDPG与DQN有着极高的算法相似性,并不只如DDPG论文中所说的脱胎于DPG算法。
本文关于DQN和DDPG两种算法的对比理解就到这里,下一篇中我们会从代码入手,对着两种算法进行实现,敬请期待!
5、参考
[1] 邱锡鹏《NNDL》
[2] Continuous control with deep reinforcement learning
[3] Playing Atari with Deep Reinforcement Learning

行者AI(成都潜在人工智能科技有限公司,xingzhe.ai)致力于使用人工智能和机器学习技术提高游戏和文娱行业的生产力,并持续改善行业的用户体验。我们有内容安全团队、游戏机器人团队、数据平台团队、智能音乐团队和自动化测试团队。 > >如果您对世界拥有强烈的好奇心,不畏惧挑战性问题;能够容忍摸索过程中的各种不确定性、并且坚持下去;能够寻找创新的方式来应对挑战,并同时拥有事无巨细的责任心以确保解决方案的有效执行。那么请将您的个人简历、相关的工作成果及您具体感兴趣的职位提交给我们。我们欢迎拥抱挑战、并具有创新思维的人才加入我们的团队。请联系:hr@xingzhe.ai > >如果您有任何关于内容安全、游戏机器人、数据平台、智能音乐和自动化测试方面的需求,我们也非常荣幸能为您服务。可以联系:contact@xingzhe.ai

 浙公网安备 33010602011771号
浙公网安备 33010602011771号