burp suite之spider(爬虫)
spider (蜘蛛,这里的意思指爬行)
像蜘蛛一样在网站上爬行出网站的个个目录信息,并发送至Target。
1.Control(控制)
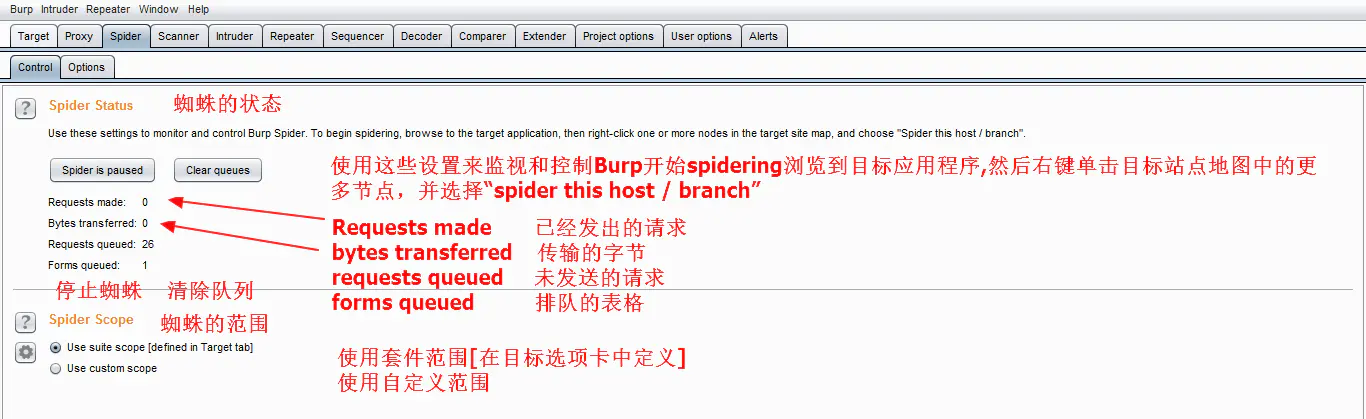
Spider is paused :停止蜘蛛爬行
Clear queues: 清除列队
2. Options(选项)
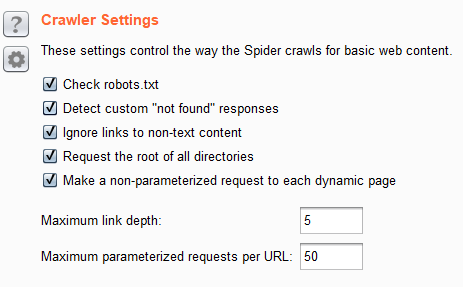
设置这些控制方式蜘蛛爬行基本web内容
1.检测是否存在robots.txt
2.检测自定义"未找到"响应(404)
3.胡罗非文本内容的链接
4.请求所有目录的根
Maximum link depth: 爬行多少级的网站目录

当你的网站包含不希望被搜索引擎收录的内容时,需要使用roobots.txt文件。如果你希望搜索引擎收录网站上的所有内容,请勿建立roboxt.txt
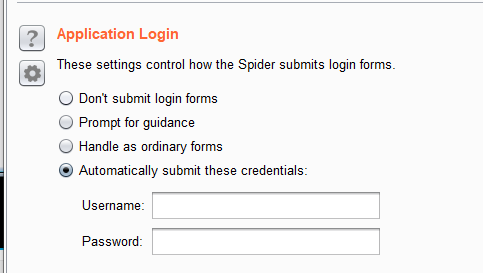
爬行时 遇到 表单,则可以在这里输入账号密码,登录成功继续爬行后台页面。

Number of threads :设置请求线程。控制并发请求数。一般小型网站为3 中型为10.
Number of retries on network failure: 如果出现连接错误或其他网络问题,Burp会尝试重新请求。
Pause before retry :当重试失败的请求,Burp会等待指定的时间(以毫秒为单位)以下,然后重试失败。如果服务器宕机,繁忙,或间歇性的问题发生,最好是等待很短的时间,然后重试。
Throttle between requests:在每次请求之前等待一个指定的延迟(以毫秒为单位)。此选项很有用,以避免超载应用程序,或者是更隐蔽。

自定义设置 请求头
