Python pandas和numpy的区别
https://m.py.cn/jishu/jichu/30289.html
数据结构上
1、numpy的核心数据结构是ndarray,支持任意维数的数组,但要求单个数组内所有数据是同质的,即类型必须相同;而pandas的核心数据结构是series和dataframe,仅支持一维和二维数据,但数据内部可以是异构数据,仅要求同列数据类型一致即可。
numpy的数据结构仅支持数字索引,而pandas数据结构则同时支持数字索引和标签索引。
2、numpy用于数值计算,pandas主要用于数据处理与分析。
numpy虽然也支持字符串等其他数据类型,但仍然主要是用于数值计算,尤其是内部集成了大量矩阵计算模块,例如基本的矩阵运算、线性代数、fft、生成随机数等,支持灵活的广播机制。
pandas主要用于数据处理与分析,支持包括数据读写、数值计算、数据处理、数据分析和数据可视化全套流程操作。
以上就是Python pandas和numpy的区别,希望对大家有所帮助。
https://blog.csdn.net/pfm685757/article/details/108699003
一、什么是Pandas?
Pandas被定义为一个开源库, 可在Python中提供高性能的数据处理。它建立在NumPy软件包的顶部, 这意味着操作Numpy需要Pandas。Pandas的名称源自”面板数据”一词, 这表示来自多维数据的计量经济学。它用于Python中的数据分析, 由Wes McKinney在2008年开发。
在Pandas之前, Python能够进行数据准备, 但是它仅提供了有限的数据分析支持。因此, Pandas崭露头角, 并增强了数据分析的功能。无论数据的来源如何, 它都可以执行处理和分析数据所需的五个重要步骤, 即加载, 操作, 准备, 建模和分析。
二、什么是NumPy?
NumPy主要用C语言编写, 它是Python的扩展模块。它被定义为Python软件包, 用于执行多维和一维数组元素的各种数值计算和处理。使用Numpy数组的计算比普通的Python数组快。
NumPy包是由Travis Oliphant在2005年创建的, 方法是将祖先模块Numeric的功能添加到另一个模块Numarray中。它还能够处理大量数据, 并通过矩阵乘法和数据重塑而方便。
Pandas和NumPy都可以被视为任何科学计算(包括机器学习)的必不可少的库, 因为它们具有直观的语法和高性能的矩阵计算功能。这两个库也最适合数据科学应用程序。
三、Pandas和NumPy之间的区别
下面列出了Pandas和NumPy之间的一些区别:
- Pandas模块主要处理表格数据, 而NumPy模块处理数字数据。
- Pandas提供了一些强大的工具集, 例如DataFrame和Series, 主要用于分析数据, 而NumPy模块提供了一个强大的对象, 称为Array。
- Instacart, SendGrid和Sighten是使用Pandas模块的一些著名公司, 而SweepSouth使用NumPy。
- Pandas涵盖了更广泛的应用程序, 因为它在73个公司堆栈和46个开发人员堆栈中被提及, 而在NumPy中, 提到了62个公司堆栈和32个开发人员堆栈。
- 对于50K或更少的行, NumPy的性能优于NumPy。
- 对于50万行或更多的行, Pandas的性能要优于NumPy。在50K到500K行之间, 性能取决于操作的类型。
- NumPy库提供用于多维数组的对象, 而Pandas能够提供称为DataFrame的内存中二维表对象。
- 与Pandas相比, NumPy消耗更少的内存。
- 与NumPy数组相比, Series对象的索引非常慢。
下表显示了Pandas和NumPy之间的比较表:
| 比较基础 | Pandas | NumPy |
|---|---|---|
| Works with | Pandas模块适用于表格数据。 | NumPy模块可用于数值数据。 |
| Powerful Tools | Pandas拥有强大的工具, 例如Series, DataFrame等。 | NumPy具有像Arrays这样的强大工具。 |
| 组织用途 | Pandas用于Instacart, SendGrid和Sighten等受欢迎的组织。 | NumPy用于像SweepSouth这样的流行组织。 |
| Performance | Pandas对于50万行或更多行具有更好的性能。 | NumPy对于5万行或更少的行具有更好的性能。 |
| 内存利用率 | 与NumPy相比, Pandas消耗大量内存。 | 与Pandas相比, NumPy消耗的内存更少。 |
| Industrial Coverage | 在73个公司堆栈和46个开发人员堆栈中提到了Pandas。 | 在62个公司堆栈和32个开发人员堆栈中都提到了NumPy。 |
| Objects | Pandas提供了称为DataFrame的2d表对象。 | NumPy提供了多维数组。 |
知乎:一只小猴 https://zhuanlan.zhihu.com/p/146754890
本文我们就来了解一下在数据处理时常用到的numpy和pandas到底是什么?该如何使用呢?
一、Numpy
numpy是以矩阵为基础的数学计算模块,提供高性能的矩阵运算,数组结构为ndarray。
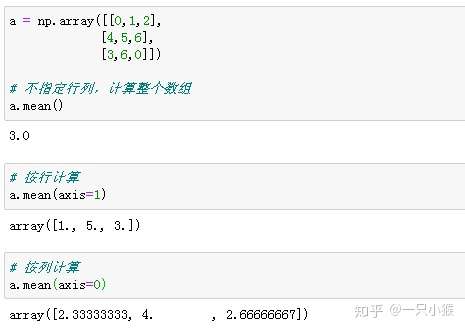
首先需要明确数组与列表的区别:数组是一种特殊变量,虽与列表相似,但列表可以存储任意类型的数据,数组只能存储一种类型的数据,同时,数组提供了许多方便统计计算的功能(如平均值mean、标准差std等)。
那么numpy有哪些功能呢?
首先在使用前要导入该模块(导入前要安装,方法自行搜索吧(*^-^*)),代码如下:
import numpy as np1. 通过原有列表转化为数组

2. 直接生成数组
① 生成一维数组

上图中由于生成一维数组时,没有给参数10 定义数据类型,所以数组元素的类型默认为float64。那定义数据类型为整型时会是什么结果呢?
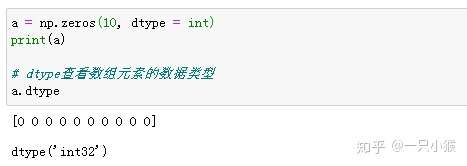
② 生成多维数组

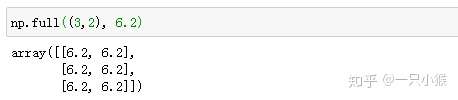
zeros返回来一个给定形状和类型的用0填充的数组,同理,ones返回来一个给定形状和类型的用1填充的数组。但更多情况下我们想指定某个值,这时用np.full(shape, val)生成全为val的值,如下:
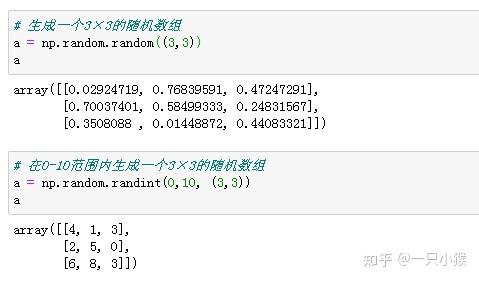
3. 随机数取值
我们知道random库中可以通过random.randint(5,10)来随机生成一个5-10的数,如下:

在numpy中也有一个类似的加强版的功能。
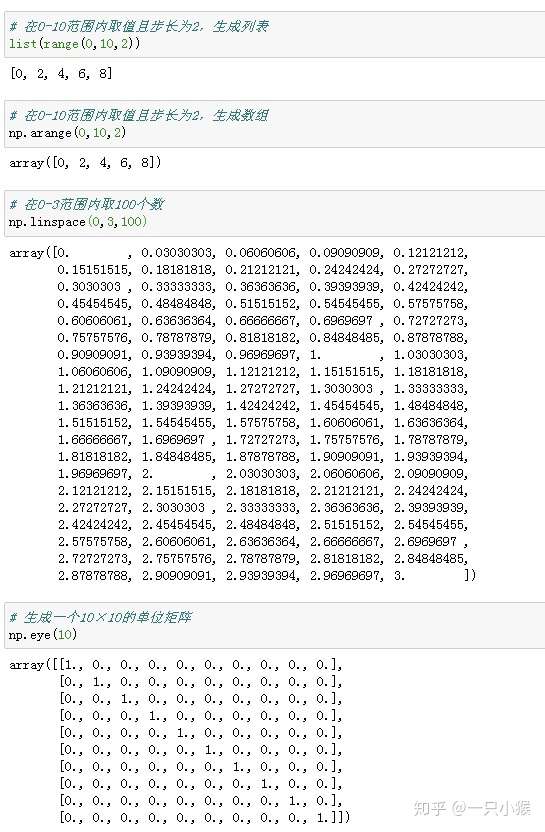
4. 范围取值
5. 访问数组中的元素


6. 基本数学运算
numpy在做运算时,是对数组中每个元素都进行运算。

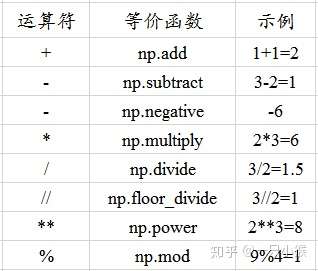
常用的运算符号及等价函数总结如下:
7. 数组变形

数组变形时,数组总大小保持不变,如上图中我们定义了一个两行五列的数组,总大小为2*5=10,经变形后得到一行十列的数组,总大小仍为10,但我们无法变成3*4或6*9等类型。
8. 数组拼接

9. 数组排序

二、Pandas
pandas是基于numpy数组构建的,但二者最大的不同是pandas是专门为处理表格和混杂数据设计的,比较契合统计分析中的表结构,而numpy更适合处理统一的数值数组数据。pandas数组结构有一维Series和二维DataFrame。
使用前同样需要先导入该模块,代码如下:
import pandas as pd1. Series
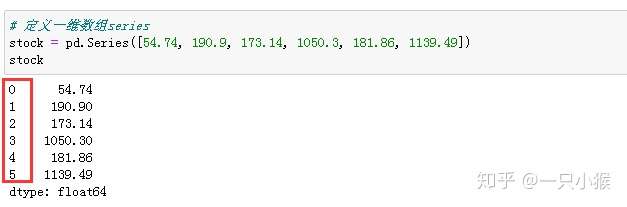
Series是一种类似于一维数组的对象,它由一组数据以及一组与之相关的数据标签(索引index)组成。

Series的字符串表现形式为:索引在左边,值在右边。如果不为数据指定索引,则会默认创建一个0到n-1的整数型索引。
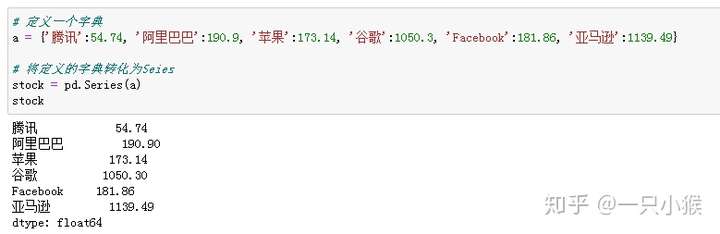
① 通过原有字典转化为数组
② 访问元素
与numpy相比,除了根据位置获取值外,还可以根据索引获取。
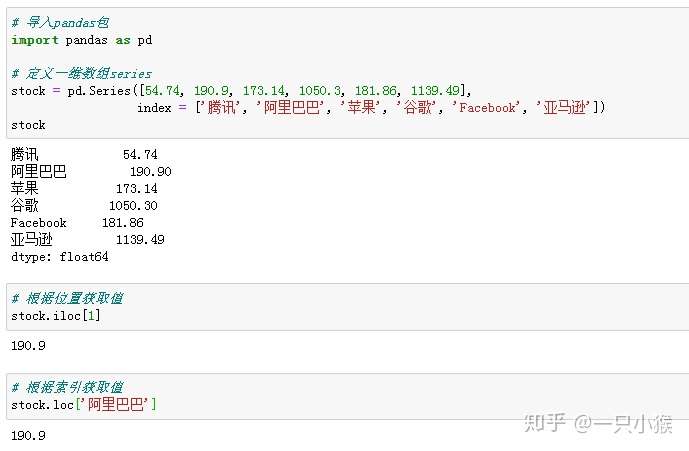
③ 向量化运算

上图运行结果可以看到出现了缺失值NaN(not a number),这是因为索引值b、c、d、e、f、g只出现在一个一维数组中。在数据分析过程中,我们通常不希望缺失值出现,那么如何解决呢?
一般常用的有两种方法:
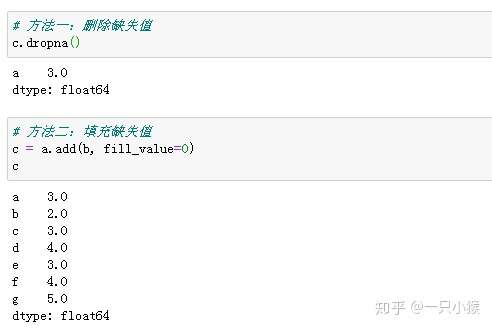
2. DataFrame
DataFrame是一个表格型的数据结构,其中的数据是以一个或多个二维块存放的,而不是列表、字典或别的一维数据结构。它含有一组有序的列,每列可以是不同的数据类型,它既有行索引,也有列索引。
① 将原有字典转化为DataFrame

② 访问元素
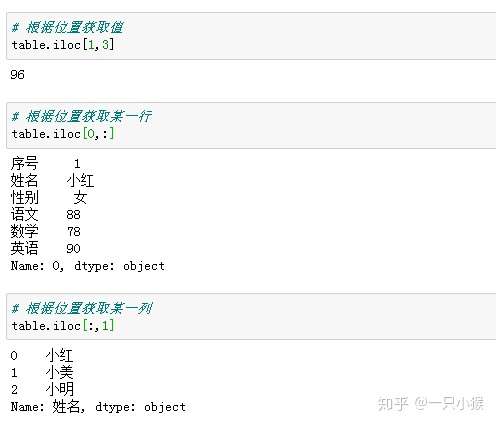
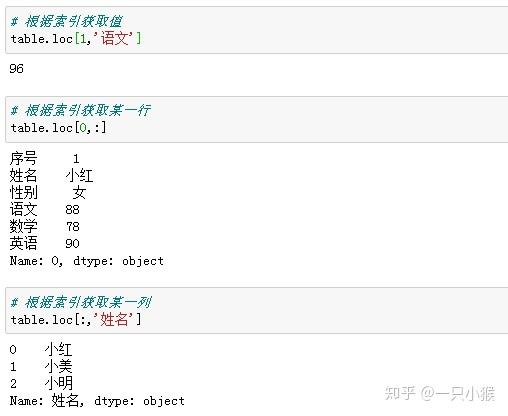
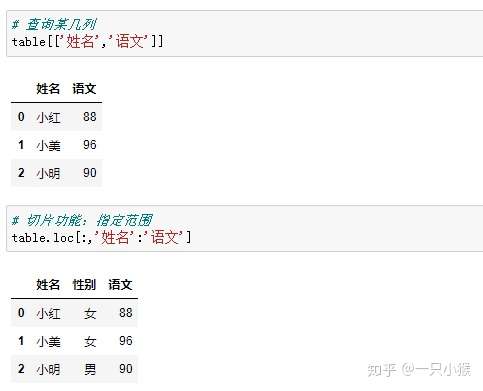
③ 条件筛选
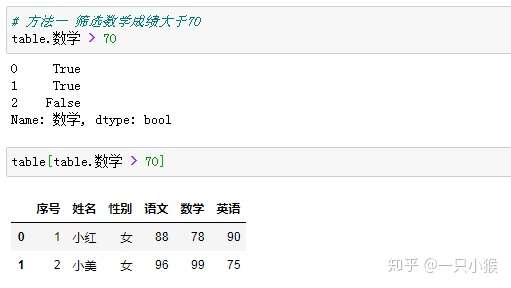
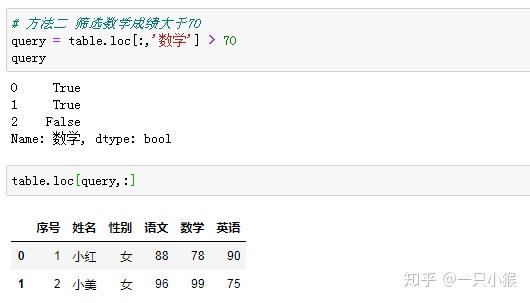
④ 排序
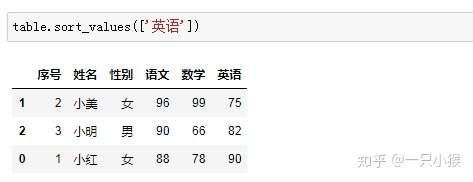
⑤ 应用函数
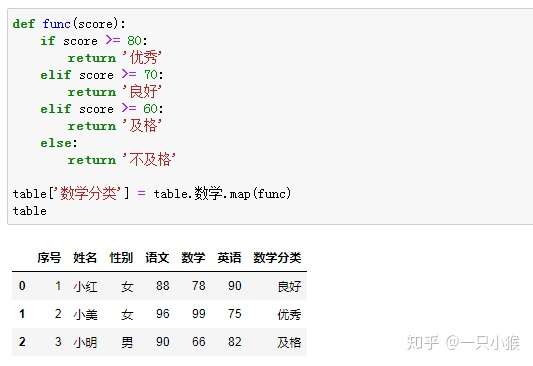

其他常用函数举例如下:
# 取前五行
table.head()
# 取后五行
table.tail()
# 查看行列数
table.shape()
# 查看每一列的统计信息
table.describe()
......以上就是numpy与pandas的基础内容,如有遗漏或错误,欢迎评论区指正~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号