

大数据技术-Flink
概述
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态的计算
Unbounded streams(无界流)有一个起点,但没有定义的终点。它们不会终止,而且会源源不断的提供数据。无边界的流必须被连续地处理,即事件达到后必须被立即处理。等待所有输入数据到达是不可能的,因为输入是无界的,并且在任何时间点都不会完成。处理无边界的数据通常要求以特定顺序(例如,事件发生的顺序)接收事件,以便能够推断出结果的完整性。
Bounded streams(有界流)有一个定义的开始和结束。在执行任何计算之前,可以通过摄取(提取)所有数据来处理有界流。处理有界流不需要有序摄取,因为有界数据集总是可以排序的。有界流的处理也称为批处理。
Apache Flink擅长处理无界和有界数据集。对时间和状态的精确控制使Flink的运行时能够在无边界的流上运行任何类型的应用程序。有界流由专门为固定大小的数据集设计的算法和数据结构在内部处理,从而产生出色的性能。
架构
运行架构
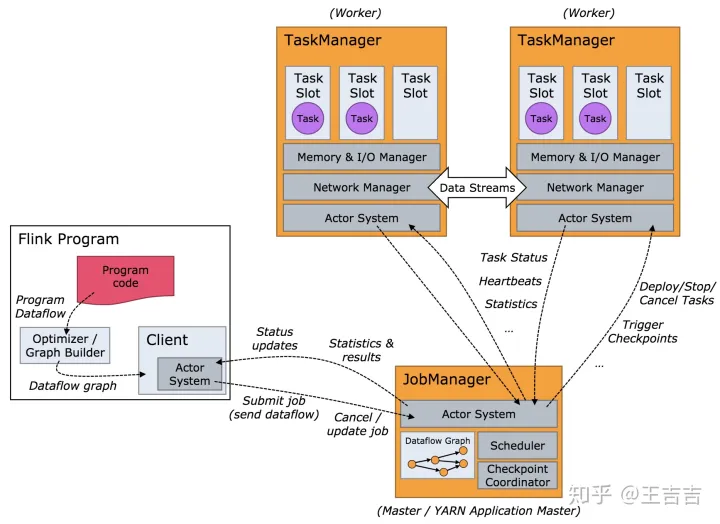
运行时有两个主要的进程:JobManager和TaskManager
ResourceManager:负责资源分配,管理任务slot, 这个是flink集群资源管理的单位。
Dispatcher:提供应用程序提交的REST接口,对每一个提交的作业启动JobMaster,并运行Flink WebUI提供作业执行的信息。
JobMaster:负责单个作业图(JobGraph)的执行。一个集群可以同时运行多个作业,每个作业都有自己的JobMaster。
TaskManager负责执行dataflow中的任务,缓存和交换数据流。一个作业执行时,至少要有一个TaskManager,TaskManager中资源调度的最小单位是slot。一个TaskManager中的slot数表示的是该TaskManager中可以并行执行任务的数量
Flink核心四大基石

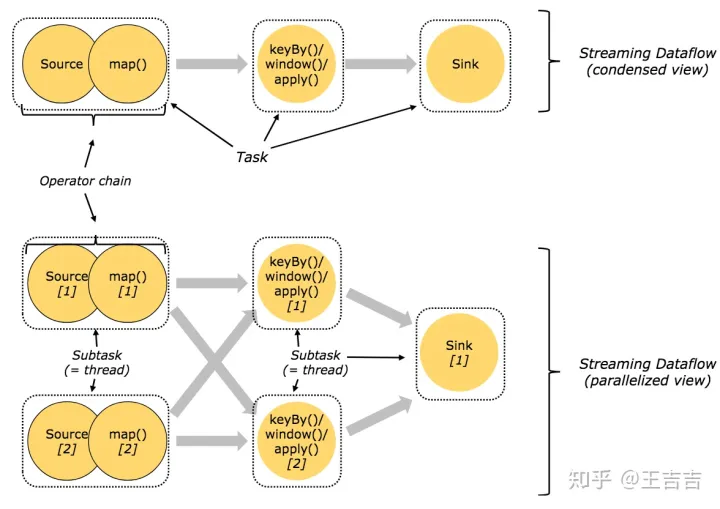
任务和算子链
Flink将不同算子的子任务(subtask)链接到一个任务里,每一个任务在一个线程中执行。这是一个非常有用的优化方式,它减小了进程间数据交换和缓存的开销,而且在减少延迟同时增加了吞吐量。这种链接关系是可配置的,下面是一个有5个子任务(subtask)的示例,有5个线程并行执行。
任务Slot和资源
每个worker(TaskManager)都是一个JVM进程,可以执行一个或多个子任务(subtask)。任务槽(task slot)就是为了控制一个worker能同时运行多少个任务的(至少一个)。
每个任务槽(task slot)代表TaskManager一个设定的资源子集。比如, 一个TaskManager有3个槽,会将其管理的1/3的内存分给每个槽位。将资源分成不同的槽位意味着一个子任务(subtask)不会跟其他作业的子任务竞争资源,而是会拥有一定量的保留资源。需要注意的是,这里不涉及CPU隔离,目前任务槽仅仅分割task管理的内存。
为了适配任务槽(task slot)的数量,用户可以定义子任务(subtask)是如何隔离的。如果每个TaskManager有一个槽,就意味着task组运行在不同的GJVM里。如果每个TaskManager有多个槽意味着多个字任务(subtask)共享同一个JVM。任务在同一个JVM运行可以共享TCP链接和心跳信息。它们可以共享数据集和数据结构,因此可以减少每个任务的开销。
checkpoint和savepoint
Flink Checkpoint 是一种容错恢复机制。这种机制保证了实时程序运行时,即使突然遇到异常也能够进行自我恢复。Checkpoint 对于用户层面,是透明的,用户会感觉程序一直在运行。Flink Checkpoint 是 Flink 自身的系统行为,用户无法对其进行交互,用户可以在程序启动之前,设置好实时程序 Checkpoint 相关参数,当程序启动之后,剩下的就全交给 Flink 自行管理。
Flink Savepoint 你可以把它当做在某个时间点程序状态全局镜像,以后程序在进行升级,或者修改并发度等情况,还能从保存的状态位继续启动恢复。Flink Savepoint 一般存储在 HDFS 上面,它需要用户主动进行触发。
Flink Checkpoint和Savepoint对比:
概念:Checkpoint 是 自动容错机制 ,Savepoint 程序全局状态镜像 。
目的: Checkpoint 是程序自动容错,快速恢复 。Savepoint是 程序修改后继续从状态恢复,程序升级等。
用户交互:Checkpoint 是 Flink 系统行为 。Savepoint是用户触发。
状态文件保留策略:Checkpoint默认程序删除,可以设置CheckpointConfig中的参数进行保留 。Savepoint会一直保存,除非用户删除 。
Flink Checkpoint 语义
Flink Checkpoint 支持两种语义:Exactly Once 和 At least Once,默认的 Checkpoint 模式是 Exactly Once. Exactly Once 和 At least Once 具体是针对 Flink 状态 而言。具体语义含义如下:
Exactly Once 含义是:保证每条数据对于 Flink 的状态结果只影响一次。打个比方,比如 WordCount程序,目前实时统计的 "hello" 这个单词数为5,同时这个结果在这次 Checkpoint 成功后,保存在了 HDFS。在下次 Checkpoint 之前, 又来2个 "hello" 单词,突然程序遇到外部异常容错自动回复,从最近的 Checkpoint 点开始恢复,那么会从单词数 5 这个状态开始恢复,Kafka 消费的数据点位还是状态 5 这个时候的点位开始计算,所以即使程序遇到外部异常自我恢复,也不会影响到 Flink 状态的结果。
At Least Once 含义是:每条数据对于 Flink 状态计算至少影响一次。比如在 WordCount 程序中,你统计到的某个单词的单词数可能会比真实的单词数要大,因为同一条消息,你可能将其计算多次。
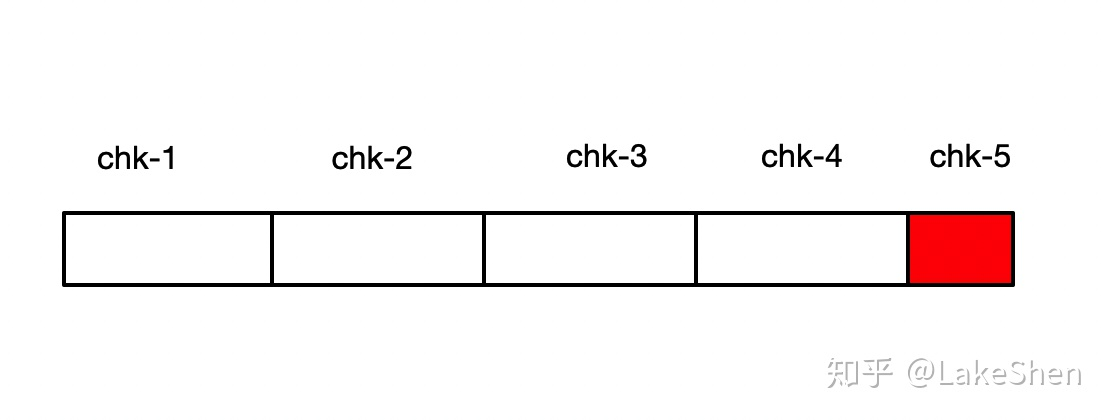
上图中表示,在进行 chk-5 Checkpoint 时,突然遇到程序异常,那么会从 chk-4 进行恢复,那么之前chk-5 处理的数据,会再次进行处理。
Exactly Once 和 At Least Once 具体在底层实现大致相同,具体差异表现在 Barrier 对齐方式处理:
如果是 Exactly Once 模式,某个算子的 Task 有多个输入通道时,当其中一个输入通道收到 Barrier 时,Flink Task 会阻塞处理该通道,其不会处理这些数据,但是会将这些数据存储到内部缓存中,一旦完成了所有输入通道的 Barrier 对齐,才会继续对这些数据进行消费处理。
对于 At least Once,同样针对某个算子的 Task 有多个输入通道的情况下,当某个输入通道接收到 Barrier 时,它不同于Exactly Once,At Least Once 会继续处理接受到的数据,即使没有完成所有输入通道 Barrier 对齐。所以使用At Least Once 不能保证数据对于状态计算只有一次影响。
本文来自博客园,作者:codeBetter1993,转载请注明原文链接:https://www.cnblogs.com/ermao1993/p/17216269.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)