

大数据技术-hadoop
hadoop是什么
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。
主要解决,海量数据的存储和海量数据的分析计算问题。
广义上来说,Hadoop 通常是指一个更广泛的概念 —— Hadoop 生态圈。
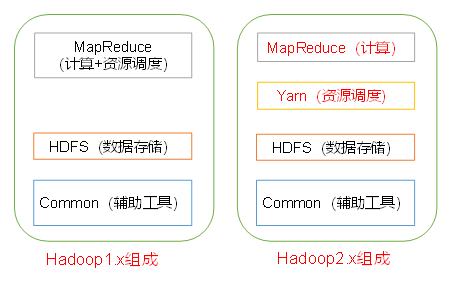
Hadoop 1.x 和 hadoop 2.x 的区别
在 Hadoop 1.x 时代,Hadoop 中的 MapReduce 同时处理业务逻辑运算和资源调度,耦合性较大。
在 Hadoop 2.x 时代,增加了 Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。
HDFS
① NameNode(nn): 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块所在的 DataNode 等。
② DataNode(dn): 在本地文件系统存储文件块数据,以及块数据校验和。
③ Secondary DataNode(2nn): 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。
HDFS读文件
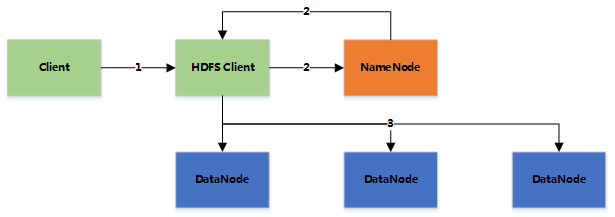
客户端向NameNode发送读取请求
NameNode返回文件的所有block和这些block所在的DataNodes(包括复制节点)
客户端直接从DataNode中读取数据,如果该DataNode读取失败(DataNode失效或校验码不对),则从复制节点中读取(如果读取的数据就在本机,则直接读取,否则通过网络读取)
Yarn
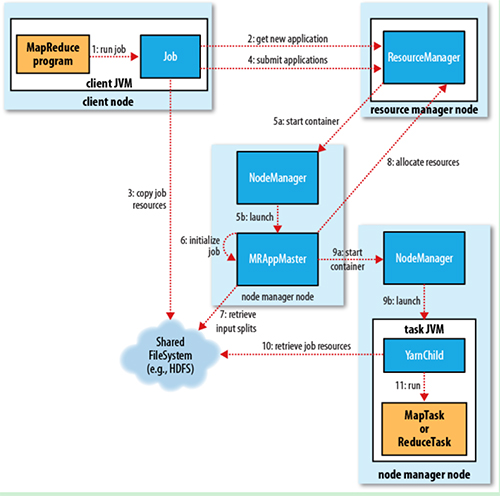
YARN就是将 JobTracker 的职责进行拆分,将资源管理和任务调度监控拆分成独立的进程:一个全局的资源管理和一个每个作业的管理(ApplicationMaster) ResourceManager 和 NodeManager 提供了计算资源的分配和管理,而 ApplicationMaster 则完成应用程序的运行
ResourceManager: 全局资源管理和任务调度,管控全局资源
NodeManager: 单个节点的资源管理和监控,上报心跳
ApplicationMaster: 单个作业的资源管理和任务监控,申请资源
Container: 资源申请的单位和任务运行的容器, 资源单位
MapReduce
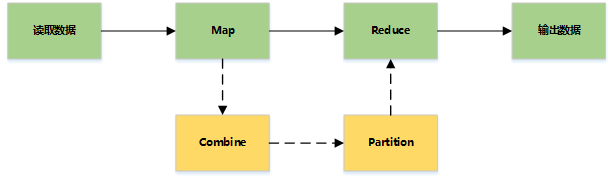
MapReduce 将计算过程分为两个阶段:Map 阶段和 Reduce 阶段。
简介
一种分布式的计算方式指定一个Map(映#x5C04;)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
模式
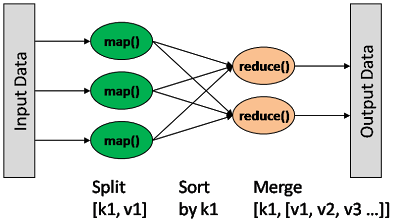
map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K2, V2) reduce: (K2, list(V2)) → list(K3, V3)
Map输出格式和Reduce输入格式一定是相同的
"Map(映射)" 和 "Reduce(归约)"
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合”,即对map阶段的结果进行全局汇总。
基本流程
MapReduce主要是先读取文件数据,然后进行Map处理,接着Reduce处理,最后把处理结果写到文件中
运行机制
MapTask工作机制
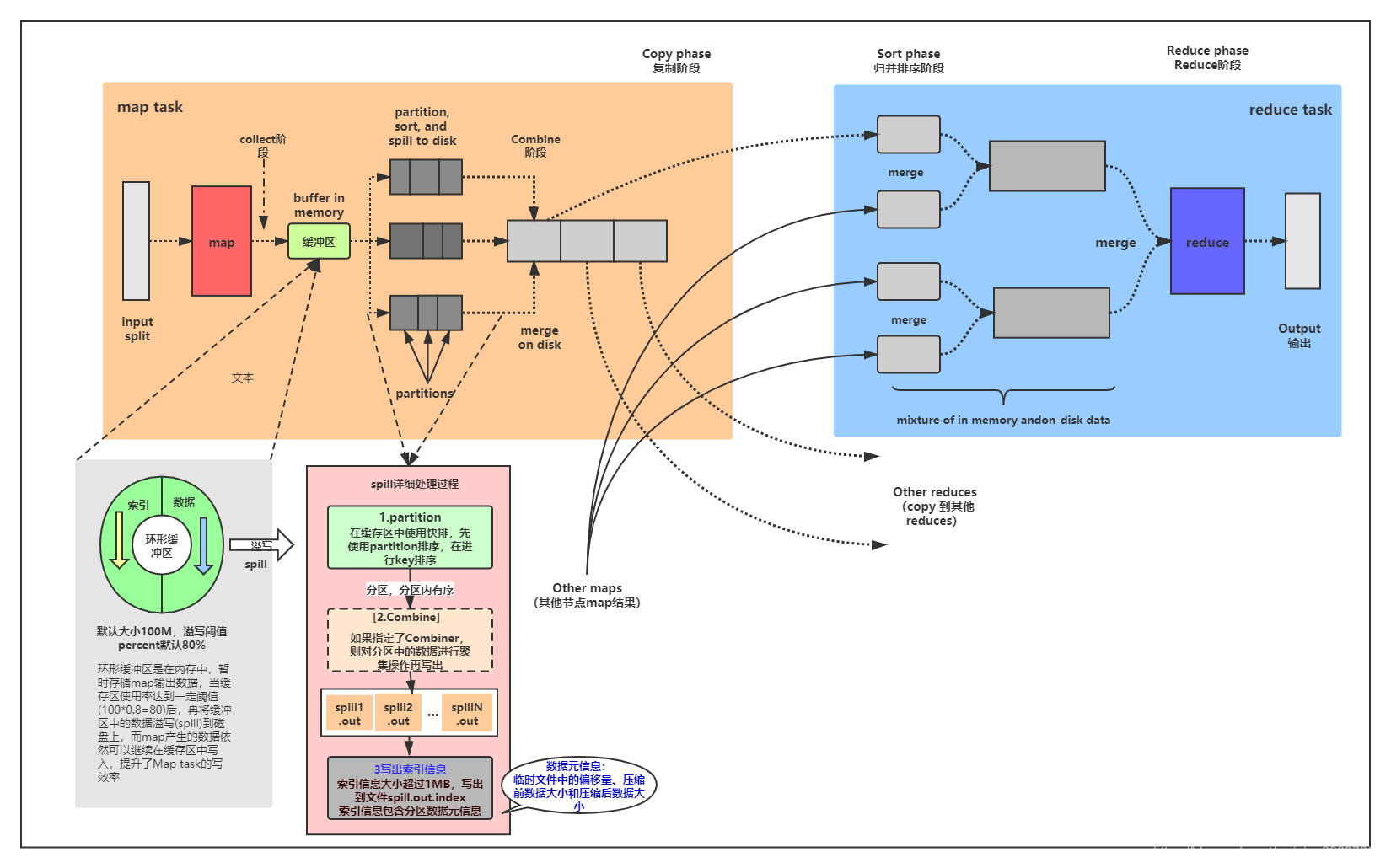
MapTask的整体计算如上图所示,共分为5个阶段:Read阶段,Map阶段,Collect收集阶段,Spill阶段,Combine阶段
详细说明如下:
Read阶段
MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
Map阶段
该阶段主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
Collect收集阶段
在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
当map函数处理完一对key/value产生新的key/value后,会调用collect()函数输出结果。在输出结果时,OutputCollecter对象会根据作业是否有Reduce Task进行不同的处理,如果没有Reduce Task阶段,则把结果直接输出到HDFS。如果后续有对应的Reduce Task,则开始组织封装结果
Spill阶段
即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
Combine阶段
当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
ReduceTask工作机制
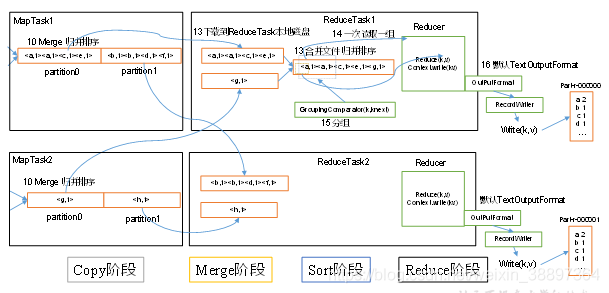
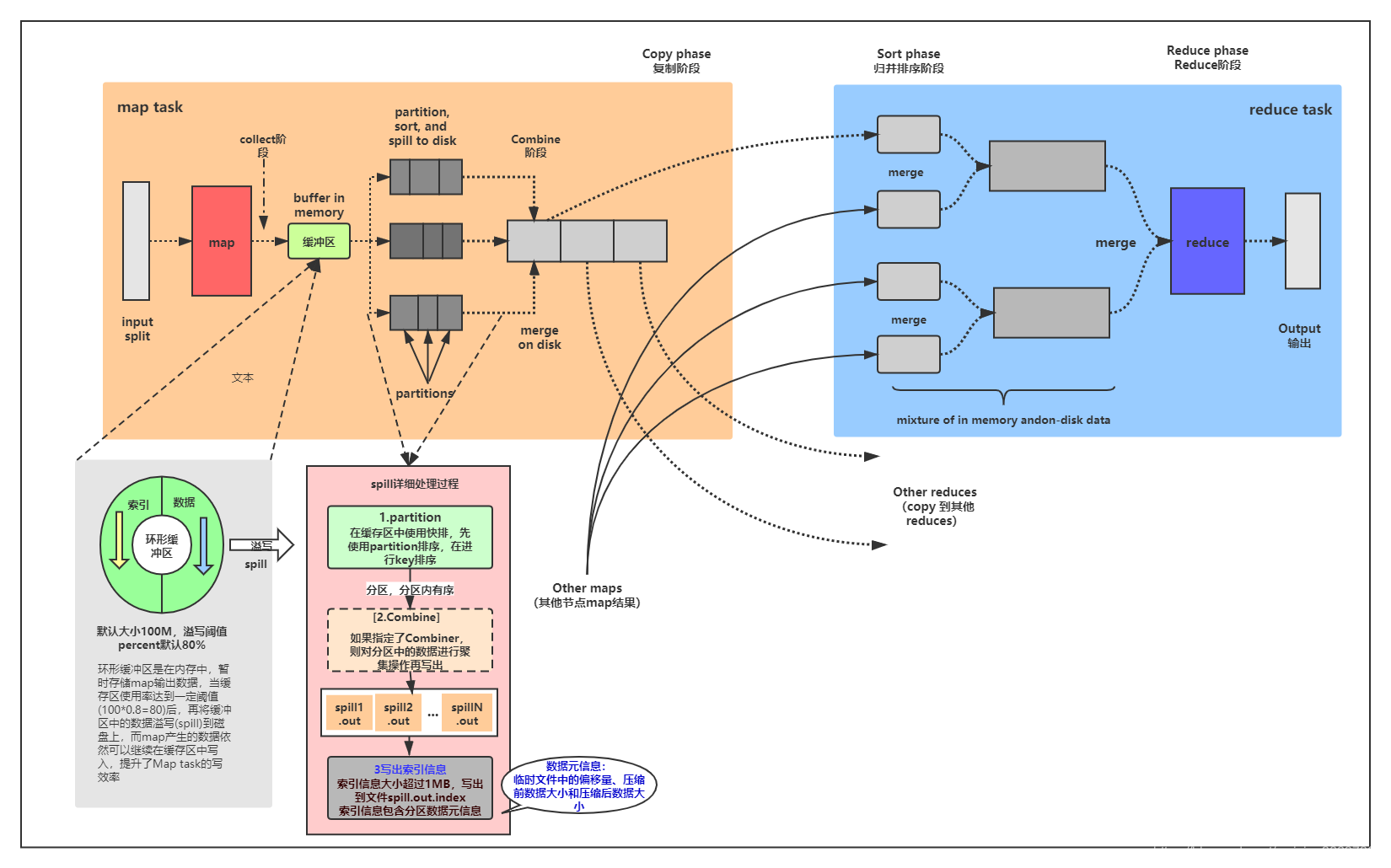
5个阶段:Copy阶段/Shuffle阶段,Merge阶段,Sort阶段,Reduce阶段,
(1)Copy阶段/Shuffle阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
总体上看,Shuffle&Merge阶段可进一步划分为三个子阶段。
(1)准备运行完成的Map Task列表:
GetMapEventsThread线程周期性通过RPC从TaskTracker获取已完成Map Task列表,并保存到映射表mapLocations(保存了TaskTracker Host与已完成任务列表的映射关系)中。为防止出现网络热点,Reduce Task通过对所有TaskTracker Host进行“混洗”操作以打乱数据拷贝顺序,并将调整后的Map Task输出数据位置保存到scheduledCopies列表中。
(2)远程拷贝数据
Reduce Task同时启动多个MapOutputCopier线程,这些线程从scheduledCopies列表中获取Map Task输出位置,并通过HTTP Get远程拷贝数据。对于获取的数据分片,如果大小超过一定阈值,则存放到磁盘上,否则直接放到内存中。
(3)合并内存文件和磁盘文件
为了防止内存或者磁盘上的文件数据过多,Reduce Task启动了LocalFSMerger和InMemFSMergeThread两个线程分别对内存和磁盘上的文件进行合并。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
前面提到,各个Map Task已经事先对自己的输出分片进行了局部排序,因此,Reduce Task只需进行一次归并排序即可保证数据整体有序。为了提高效率,Hadoop将Sort阶段和Reduce阶段并行化。在Sort阶段,Reduce Task为内存和磁盘中的文件建立了小顶堆,保存了指向该小顶堆根节点的迭代器,且该迭代器保证了以下两个约束条件:
1.磁盘上文件数目小于io.sort.factor(默认是10)。
2.当Reduce阶段开始时,内存中数据量小于最大可用内存(JVM Max HeapSize)的mapred.job.reduce.input.buffer.percent(默认是0)。
在Reduce阶段,Reduce Task不断地移动迭代器,以将key相同的数据顺次交给reduce()函数处理,期间移动迭代器的过程实际上就是不断调整小顶堆的过程,这样,Sort和Reduce可并行进行。
大数据技术生态体系
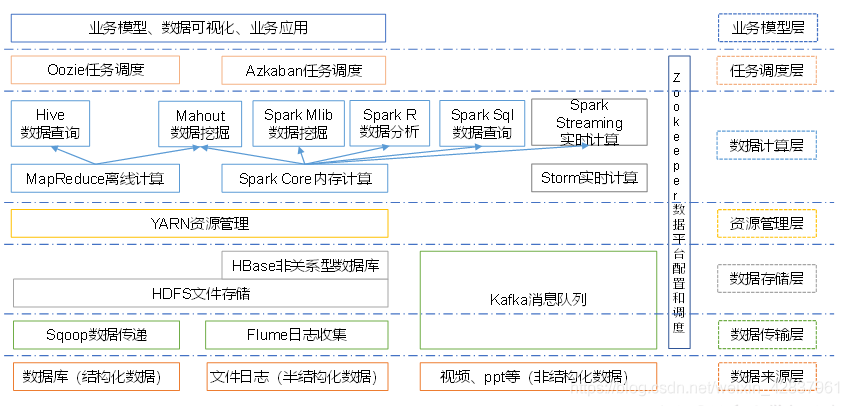
特点
架构
应用场景
本文来自博客园,作者:codeBetter1993,转载请注明原文链接:https://www.cnblogs.com/ermao1993/p/17149090.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)