

大数据技术-hive
HIVE是什么?
Hive是一个在Hadoop中用来处理结构化数据的数据仓库基础工具。它架构在Hadoop之上,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。通过类SQL语句实现快速MapReduce统计,使MapReduce编程变得更加简单易行。
特点
优点:
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点:
1.Hive的HQL表达能力有限
(1)迭代式算法无法表达递归算法
(2)数据挖掘方面不擅长(数据挖掘和算法机器学习)
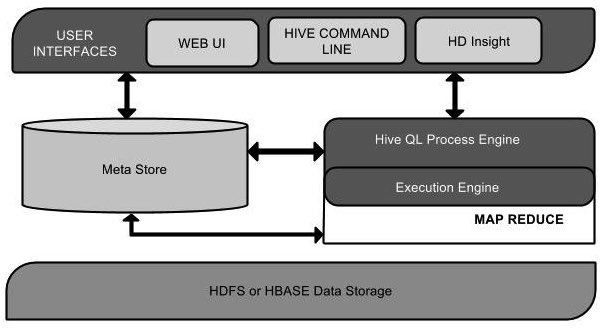
HIVE架构
HIVE应用场景
- 海量结构化数据离线分析,如海量数据的准确率,年同比, 环比等指标报表
- 多维度数据拼接,组合等处理
HIVE文件格式
TextFile
1、存储方式:行存储。默认格式,如果建表时不指定默认为此格式。
2、每一行都是一条记录,每行都以换行符"\n"结尾。默认是不压缩,但可以采用多种压缩方式,但是部分压缩算法压缩数据后生成的文件是不支持split。
3、可结合Gzip、Bzip2等压缩方式一起使用(系统会自动检查,查询时会自动解压),推荐选用可切分的压
缩算法。
4、该类型的格式可以识别在hdfs上的普通文件格式(如txt、csv),因此该模式常用语仓库数据接入和导出层;
5、无法区分数据类型,各个字段都被认为是文本,但需要制定列分隔符和行分隔符。
Sequence File
1、SequenceFile是一种二进制文件,以<key,value>的形式序列化到文件中。存储方式:行存储;
2、支持三种压缩选择:NONE、RECORD、BLOCK。RECORD压缩率低,一般建议使用BLOCK压缩。
3、优势是文件和Hadoop API的MapFile是相互兼容的
4、缺点是由于该种模式是在textfile基础上加了些其他信息,故该类格式的大小要大于textfile,现阶段基本上不用。
RC File
1、存储方式:数据按行分块,每块按照列存储 。
A、首先,将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。
B、其次,块数据列式存储,有利于数据压缩和快速的列存取。
2、相对来说,RCFile对于提升任务执行性能提升不大,但是能节省一些存储空间。可以使用升级版的ORC格式。
ORC File
1、存储方式:数据按行分块,每块按照列存储
2、Hive提供的新格式,属于RCFile的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快,快速
列存取。
3、ORC File会基于列创建索引,当查询的时候会很快,现阶段主要使用的文件格式。
Parquet File
1、存储方式:列式存储。
2、Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列查询,Parquet特别有用。
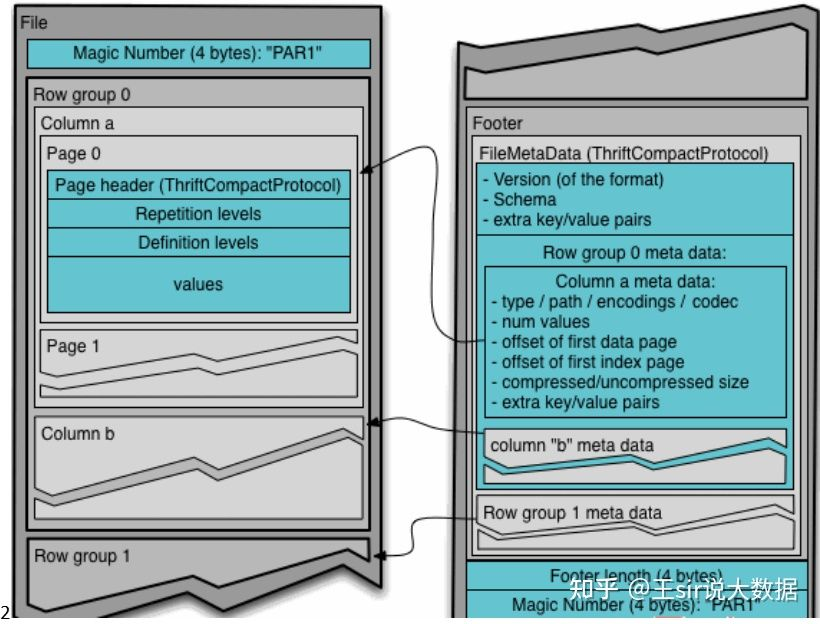
如下图, Parquet一般使用Snappy、Gzip压缩,默认是Snappy。
Parquet 文件的内容,一个文件中可以存储多个行组,文件的首位都是 该文件的 Magic Code,用于校验它是否是一个 Parquet 文件,Footer length 记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行 组的元数据信息和该文件存储数据的 Schema 信息。除了文件中每一个行组的元数据,每一 页的开始都会存储该页的元数据,在 Parquet 中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最 多包含一个字典页,索引页用来存储当前行组下该列的索引,目前 Parquet 中还不支持索引 页。
建表语法解释之-STORED&Row format
hive表数据在存储在文件系统上的,因此需要有文件存储格式来规范化数据的存储,一边hive写数据或者读数据。hive有一些已构建好的存储格式,也支持用户自定义文件存储格式。主要由两部分内容构成file_format和row_format,两者息息相关,在create table语句中结构如下:
点击查看代码
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
InputFormat、OutputFormat与SerDe三者间的关系
STORED AS TEXTFILE
实际上等于:
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
STORED AS SEQUENCEFILE
实际上等于:
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.SequenceFileInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.mapred.SequenceFileOutputFormat'
STORED AS RCFILE
实际上等于:
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.RCFileInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.RCFileOutputFormat'
STORED AS ORC/ORCFILE
实际上等于
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
STORED AS PARQUET/PARQUETFILE
实际上等于:
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
STORED AS AVRO/AVROFILE
实际上等于:
点击查看代码
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
INPUTFORMAT and OUTPUTFORMAT
前边介绍的那些文件格式,实际上都是由INPUTFORMAT 和 OUTPUTFORMAT来进行定义的。
通过指定INPUTFORMAT 和 OUTPUTFORMAT对应的类来决定输入输出的处理方式,同时也要配合合适的Serde。比如LZO表的建立,就只能使用这种方式,貌似是lzo的授权问题,可以看到’INPUTFORMAT “com.hadoop.mapred.DeprecatedLzoTextInputFormat”是第三方包。使用LZO需要用户进行配置。
HIVE默认格式
hive默认的分割方式,即行为\n,列为^A(OW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe')
如果用户需要指定的话,等同于row format delimited fields terminated by '\001',因为^A八进制编码体现为'\001'.
hive默认的存储格式为textfile(STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat')
常见语法
建表
点击查看代码
CREATE TABLE `库名.表名`
(
`data_version` string COMMENT '数据版本'
) PARTITIONED BY ( `partition_key` string COMMENT '分区日期yyyyMMdd')
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
查看表结构
show create table table_name;
上传数据
点击查看代码
load data inpath 'hdfs://XXXXX/0501_ratio.csv' into table XXXX.XXX (inc_day='20220501');
like建表法
点击查看代码
create table if not exists tableName2 like tableName1;
查询建表法
点击查看代码
- create table if not exists tableName2 as select [....] from tableName1;
</details>
#### 从其他表查询,插入并覆盖新表
insert overwrite table XXX.XXX partition(XXX)
<details>
<summary>点击查看代码</summary>
insert overwrite table XXX.XXX partition(XXX)
select * from XXXX;
</details>
select * from XXXX;
本文来自博客园,作者:codeBetter1993,转载请注明原文链接:https://www.cnblogs.com/ermao1993/p/17148573.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)