SparkStreaming实时流式大数据处理实战总结
总结《SparkStreaming实时流式大数据处理实战》
一、初始spark
1. 初始sparkstreaming
1.1 大数据处理模式
1. 一种是原生流处理(Native)的方式,即所有输入记录会一条接一条地被处理,storm 和 flink
2. 另一种是微批处理(Batch)的方式,将输入的数据以某一时间间隔,切分成多个微批量数据,然后对每个批量进行处理,sparkStreaming
1.2 消息传输保障
at most once 至多一次,可能会丢
at least once 至少一次,可能重复
exactly once 精确传递一次
1.3 容错机制
流式处理发生中断出错的现象是常有的情况,可能是发生在网络部分、某个节点宕机或程序异常等。,当发生错误导致任务中断后,应该能够恢复到之前成功的状态重新消费。
Storm是利用记录确认机制(Record ACKs)来提供容错功能。
Spark Streaming则采用了基于RDD Checkpoint的方式进行容错。
1.4 性能
延时时间:storm > spark
吞吐量 :spark > storm
1.5. Structed Streaming(结构化)简述
不同点:
Spark Streaming是以RDD构成的DStream为处理结构.
Structed Streaming是一种基于Spark SQL引擎的可扩展且容错的流处理引擎
Structed 提供了更加低延迟的处理模式
相同点:
都是微批的实时处理,内部并不是逐条处理数据记录,而是按照一个个小batch来处理,从而实现低延迟的端到端延迟和一次性容错保证。
二、共享变量
节点之间会给每个节点传递一个map、reduce等操作函数的独立副本,这些变量也会被复制到每台机器上,而节点之间的运算是相互独立的。
这些变量会被复制到每一台机器上,并且当变量发生改变时,并不会同步传播回Driver程序。
如果进行通用支持,任务间的读写共享变量需要大量的同步操作,这会导致低效。
Spark提供了两种受限类型的共享变量用于两种常见的使用模式:广播变量和累加器。
2.1 累加器(Accumulator)
累加器是一种只能通过关联操作进行“加”操作的变量,因此它能够高效地应用于并行操作中。累加器能够用来实现对数据的统计和求和操作。Spark原生支持数值类型的累加器,开发者可以自己添加支持的类型。
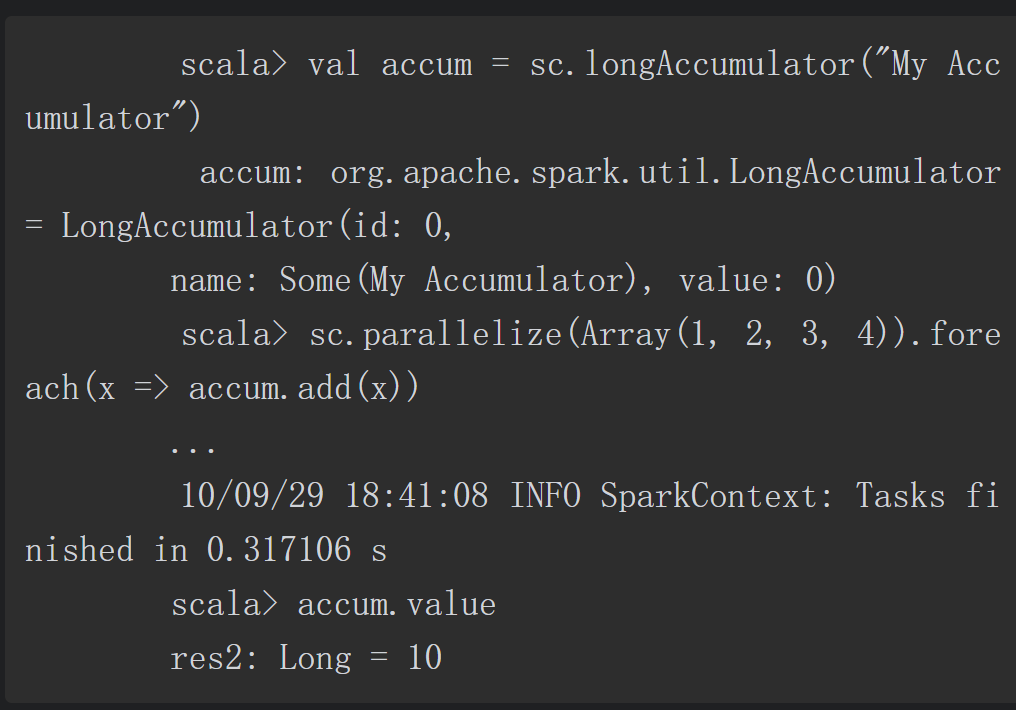
节点上的任务可以利用add方法进行累加操作,但是它们并不能读取累加器的值。只有Driver程序能够通过value方法读取累加器的值。
2.2 广播变量(Broadcast)
广播变量允许程序员在每台机器上缓存一个只读的变量,而不是每个任务保存一份拷贝。
利用广播变量,我们有效的将一个大数据量输入集合的副本分配给每个节点。Spark也有效的利用广播算法去分配广播变量,以减少通信的成本。

可以利用广播变量将一些经常访问的大变量进行广播,而不是每个任务保存一份,这样可以减少资源上的浪费。
三、DStream
Spark Streaming对微批处理方式做了一个更高层的抽象,将原始的连续的数据流抽象后得到的多个批处理数据(batches)抽象为离散数据流(discretized stream),DStream本质是RDD数据结构的序列
3.1 DStream的创建方式
一是从Kafka、Flume等输入数据流上直接创建。
二是对其他DStream采用高阶API操作之后得到(如map、flatMap等)。
3.2 DStream的Transform操作
与RDD的Transformation类似,DStream的转移操作也不会触发真正的计算,只会记录整个计算流程。
- map
- flatMap
- fliter
- repartition
- union
- reduce
- join
3.2.1 UpdateStateByKey操作
流式处理本身是无状态的,如何记录更新一种状态呢?
我们可以利用外部存储介质或者利用累加器来实现,而UpdateStateByKey就是专门用于这项工作,可以利用这个操作根据新的信息流持续地更新任意状态。
(1)定义状态(state):该状态可以是任意数据类型。
(2)定义状态更新函数(update function):我们需要制定一个函数,根据先前的状态和数据流中新的数据值来更新状态值。
特别注意:使用updateStateByKey需要配置checkpoint,这个将在后面详细介绍。
3.2.2 Transform操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号