【presto】presto集群频繁OOM问题排查
前言:
今天早上09:30-09:40时分,presto集群又出现了多个worker节点OOM然后服务挂掉的问题。集群此时非常的不稳定。

看来了下节点的日志,是发生了内存堆溢出
那么先观察一下这段时间跑的任务。由于公司的presto集群是配置了内存不足的保护策略的query.low-memory-killer.policy=total-reservation,所以先看一下任务是否又被主动kill掉的吧。
看一眼kibana:
09:30 - 09: 50 的任务数量其实也没有很多。
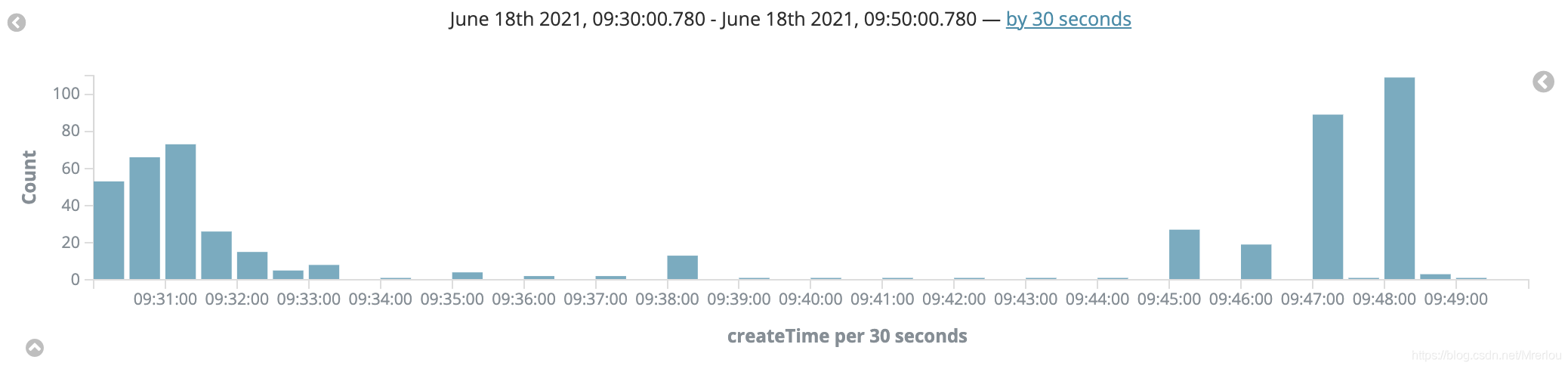
那么为什么集群内存不足,但没有触发OOM killer?
任务什么时候会被kill掉?
一个任务什么时候会被kill掉?
1.sql 本身使用的资源超出配置
相关的配置如下:
query.max-memoryquery.max-memory-per-nodequery.max-total-memory-per-node
2.集群内存不足时,触发内存保护机制
query.low-memory-killer.policy
nonetotal-reservation-on-blocked-nodestotal-reservation
先来再来看一眼集群的配置吧。
集群配置:
目前集群固定节点有23个节点,然后10点-17点处于集群繁忙状态,会增加5个节点。
config.properties
综上,Presto合适的内存分配配置为如下,-Xmx40G,Worker数大于23台,下面是config.properties文件一些重要的配置。
jvm.properties
下面是另一个重要的配置文件jvm.properties内容:
集群的配置第一眼看着没有什么问题,悬念留到后面再说。
参考文章:http://armsword.com/2020/02/18/presto-memory-kill-policy/
Presto集群内存不足时保护机制
再来看下集群内存不足时,代码逻辑吧!
判断节点是否内存不足:
代码位置:presto-main/src/main/java/com/facebook/presto/memory/ClusterMemoryPool.java
代码如下:
内存不足kill任务的代码:
代码位置:
presto-main.src/main/java/com/facebook/presto/memory/ClusterMemoryManager.java
详细如下:
此时一句log.debug的输出引起了我的注意:
翻译翻译:
如果集群内存不足并且我们没有触发 oom 杀手,我们会记录状态以使调试更容易
😯哦?那么我只需要看一下OOM节点的日志有没有输出这句话,看看是因为什么在集群内存不足时没有触发OOM killer?
正好有一个节点 开启了DEBUG级别日志。赶紧来查询一下:
结果出乎意料,日志里并没有出现这段话,那到底是什么原因导致节点OOM,但是没有?
虽然出现了新的疑问,但是却能解决第一个问题,为什么节点OOM,但是并没有触发内存不足保护机制,并不是我们保护机制写错或者配置不正确。
而是要么当时并没有出现内存不足,或者说还没来得及触发 内存保护机制时,JVM已经被kill掉了。
看来第二个可能性高一些。
也就是说有别的原因导致被kill掉。
- 操作系统触发的OOM
- 结点是否有内存泄露情况。(可以排除,有一个节点10分钟内挂掉2次)
于是将目光投向了第一个原因,是操作系统触发的OOM。
查看操作系统日志
然后搜索presto,发现并不是操作系统层面kill掉的presto。
后面当在看了一眼配置时,发现了问题:
-XX:OnOutOfMemoryError
当发生内存溢出的时候,还可以让JVM调用任一个shell脚本。大多数时候,内存溢出并不会导致整个应用都Crash掉,但是最好还是把应用重启一下,因为一旦发生了内存溢出,可能会让应用处于一种不稳定的状态,一个不稳定的应用可能会提供错误的响应。使用举例:
当给JVM传递上述参数的时候,如果发生了内存溢出,JVM会调用kill -9 将jvm 杀掉。
总结:
XX:OnOutOfMemoryError是JVM级别的query.low-memory-killer.policy=total-reservation是代码级别
两种内存保护策略起了 “冲突”,当preosto集群发生内存不足时,presto还没来得及触发内存不足保护策略,JVM那边就已经被kill掉了。
XX:OnOutOfMemoryError这个配置本意是好的,防止内存溢出后,程序不稳定主动kill掉,反而给我们带来了困惑,看来以后排查问题需要更加认真。
还有一点需要注意: 即使我们去掉了XX:OnOutOfMemoryError的配置,presto 依旧发生了内存溢出的现象,只不过发生内存溢出的节点并不会被kill掉,但是也会引起一些别的问题。所以presto判断内存不足的条件有点苛刻,并且就算检测到内存不足,presto也会在5分钟后,才会将任务杀死,我们应该让他更早的触发内存保护策略。
即让:poolInfo.getFreeBytes() + poolInfo.getReservedRevocableBytes() 比如小于JVM内存的15% ~ 20%。来早的触发内存保护策略。
__EOF__

本文链接:https://www.cnblogs.com/erlou96/p/16878319.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律