【flink】flink学习
前言
flink 是什么?
对于无界和有界的数据流进行有状态计算引擎
常见的数据架构
- 传统基础数据架构
- 微服务数据架构
- 大数据数据架构
- 有状态流计算架构
基于有状态流计算方式最大的优势:不需要将原始数据重新从外部存储中拿出来,从而进行全量计算,因为这种计算方式的代价可能是非常高的。
用户不需要通过调度和各种批计算工具,从数据仓库中获取数据统计结果,然后在落地存储,减少数据计算过程中的时间损耗和硬件存储。
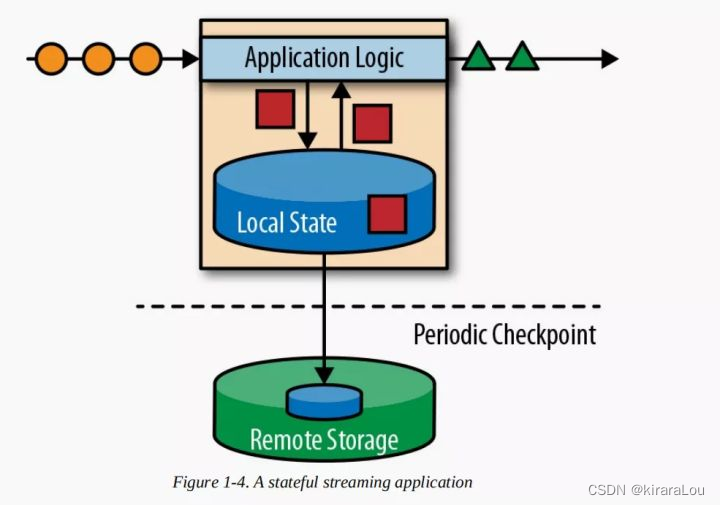
为什么选Flink
Flink 具有如下的优势:
(1)同时支持高吞吐、低延迟、高性能
Spark streaming 无法做到低延迟。
Storm 无法满足高吞吐。
(2)支持事件时间(Event Time)概念
在流式计算中,窗口计算的地位举足轻重,目前大多数框架窗口计算采用的都是系统时间(Process Time),就是时间传输到计算框架处理时,系统主机的当前时间。
Flink 能够支持基于事件时间 语义进行窗口计算。这种基于时间驱动的机制使得事件即使乱序到达,流系统也能够计算出精确结果,保持了事件原本产生时的时序性。
(3)支持有状态计算
所谓的状态就是在流式计算过程中将算子的中间结果数据保存在内存或文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果后计算当前的结果。无需每次都基于全部的原始数据来统计结果。
(4)支持高度灵活的窗口(Window)操作
数据是连续不断的,需要通过窗口的方式对流数据进行一定范围的聚合计算。
(5)轻量级分布式快照(Snapshot)实现的容错
Flink 能够自动发现事件处理过程中的错误,如节点宕机、网络传输等,基于分布式快照的checkpoint,将执行过程中的状态信息进行持久化存储。
(6)基于JVM 实现独立的内存管理
Flink 自管理内存,尽可能减少JVM GC 对系统的影响。Flink 通过将数据序列化/反序列化方法将数据对象转化成二进制存储在内存,降低数据存储大小。
(7)Save Point (保存点)
在一段时间内应用的终止可能会导致数据的丢失或者计算结果的不准确,例如集群升级和停机维护等,Flink 通过save point技术将任务执行的快照保存在介质上,当任务重启后,可以直接从事先保存的Save point恢复原有的计算状态。
Flink vs Spark
都能同时支持流式计算和批量处理。
数据处理架构
spark 通过批处理模式来统一处理不同类型的数据集,对于流数据是将数据按照批次切分成微批(有界数据集)来进行处理。
Flink 通过流处理模式来统一处理不同类型的数据集。对于有界数据可以转化成无界数据统计进行流式,最终将批处理和流处理统一在一套流式引擎中。
数据模型
Spark 采用的是RDD 模型。spark streaming 的 DStream 是一组组小批数据RDD 的集合。
Flink 基本数据模型是 数据流,以及事件(Even)序列。
运行时的架构
spark 是批计算,将DAG划分为不同的stage,一个完成后才能进行下一个。
flink 是标准的流计算架构,一个事件在一个节点完成处理后可以直接发往下一个节点进行处理。
提交模式
- session 会话模式
- Pre-job 单作业模式
- Application 应用模式
主要区别在于:集群的生命周期以及资源的分配方式。 以及应用的(main方法)到底在哪里执行,客户端cllient还是 jobmanager。
__EOF__

本文链接:https://www.cnblogs.com/erlou96/p/16878169.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」