【HDFS】:Unable to close file because the last block does not have enough number of replicas报错分析
一、问题
跑spark或hive脚本报错如下:
[INFO] 2020-03-31 11:06:03 -> java.io.IOException: Unable to close file because the last block does not have enough number of replicas.
at org.apache.hadoop.hdfs.DFSOutputStream.completeFile(DFSOutputStream.java:2266)
at org.apache.hadoop.hdfs.DFSOutputStream.close(DFSOutputStream.java:2233)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:106)
at org.apache.hadoop.io.IOUtils.copyBytes(IOUtils.java:54)
at org.apache.hadoop.io.IOUtils.copyBytes(IOUtils.java:112)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:366)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:338)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:289)
at org.apache.spark.deploy.yarn.Client.copyFileToRemote(Client.scala:356)
at org.apache.spark.deploy.yarn.Client.org$apache$spark$deploy$yarn$Client$$distribute$1(Client.scala:478)
at org.apache.spark.deploy.yarn.Client$$anonfun$prepareLocalResources$11$$anonfun$apply$6.apply(Client.scala:600)
at org.apache.spark.deploy.yarn.Client$$anonfun$prepareLocalResources$11$$anonfun$apply$6.apply(Client.scala:599)
at scala.collection.mutable.ArraySeq.foreach(ArraySeq.scala:74)
at org.apache.spark.deploy.yarn.Client$$anonfun$prepareLocalResources$11.apply(Client.scala:599)
at org.apache.spark.deploy.yarn.Client$$anonfun$prepareLocalResources$11.apply(Client.scala:598)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:598)
at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:869)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:169)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:164)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:500)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2493)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:934)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:925)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:925)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.<init>(SparkSQLCLIDriver.scala:317)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:166)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:894)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:198)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:228)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
20/03/31 11:06:03 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
二、分析
java.io.IOException: Unable to close file because the last block does not have enough number of replicas.
1
这个报错直观的意思是因为最后一个block快没有足够的副本而不能关闭文件。直观的理解很容易认为是Namenode在为client请求分配block存储地址失败,是NameNode的原因。网上也大多是网络或CPU的原因类似的答复,却没有抛出根本的原因来。
以下是hdfs写数据的流程:
具体hdfs写文件的流程描述详见不再赘述:https://www.cnblogs.com/Java-Script/p/11090379.html
当datanode建立的pipline写流程(取决于最后一个replica写完)都完成后,会依次建立返回接收成功的标志给上游datanode,最后返回到客户端,这时表示写数据成功??这里加了问号,说明是有问题的。说明上述的第9步流程不全。在最后写完block数据后,client会执行关闭流的操作,关闭流的时候,会rpc请求namenode说写文件已经完成了,回调成功,则返回true,表示写的流程彻底完成,上述图片流程少了客户端跟NameNode确认文件写完成的这一步,为了验证,根据上表报错打印的类方法信息,追溯到这里,直接上源码
org.apache.hadoop.hdfs.DFSOutputStream.completeFile
private void completeFile(ExtendedBlock last) throws IOException {
long localstart = Time.monotonicNow();
// 重试的间隔时间,默认400毫秒,无法更改
long localTimeout = 400;
boolean fileComplete = false;
// 重试rpc请求的次数,默认5次
int retries = dfsClient.getConf().nBlockWriteLocateFollowingRetry;
// 只有请求不成功才会进入下面的流程
while (!fileComplete) {
// 这里会rpc请求NameNode,告诉NameNode数据已经写完成了,
//NameNode接受到client的请求回复个true就 表示写文件大功告成
fileComplete =
dfsClient.namenode.complete(src, dfsClient.clientName, last, fileId);
if (!fileComplete) {
final int hdfsTimeout = dfsClient.getHdfsTimeout();
if (!dfsClient.clientRunning
|| (hdfsTimeout > 0
&& localstart + hdfsTimeout < Time.monotonicNow())) {
String msg = "Unable to close file because dfsclient " +
" was unable to contact the HDFS servers." +
" clientRunning " + dfsClient.clientRunning +
" hdfsTimeout " + hdfsTimeout;
DFSClient.LOG.info(msg);
throw new IOException(msg);
}
try {
// 重试完5次后,就报了上面的错
if (retries == 0) {
throw new IOException("Unable to close file because the last block"
+ " does not have enough number of replicas.");
}
retries--;
Thread.sleep(localTimeout);
localTimeout *= 2;
if (Time.monotonicNow() - localstart > 5000) {
DFSClient.LOG.info("Could not complete " + src + " retrying...");
}
} catch (InterruptedException ie) {
DFSClient.LOG.warn("Caught exception ", ie);
}
}
}
}
说明根本原因是在于写完文件后关闭流的时候客户端与NameNode rpc请求出了问题!!
三、分析监控
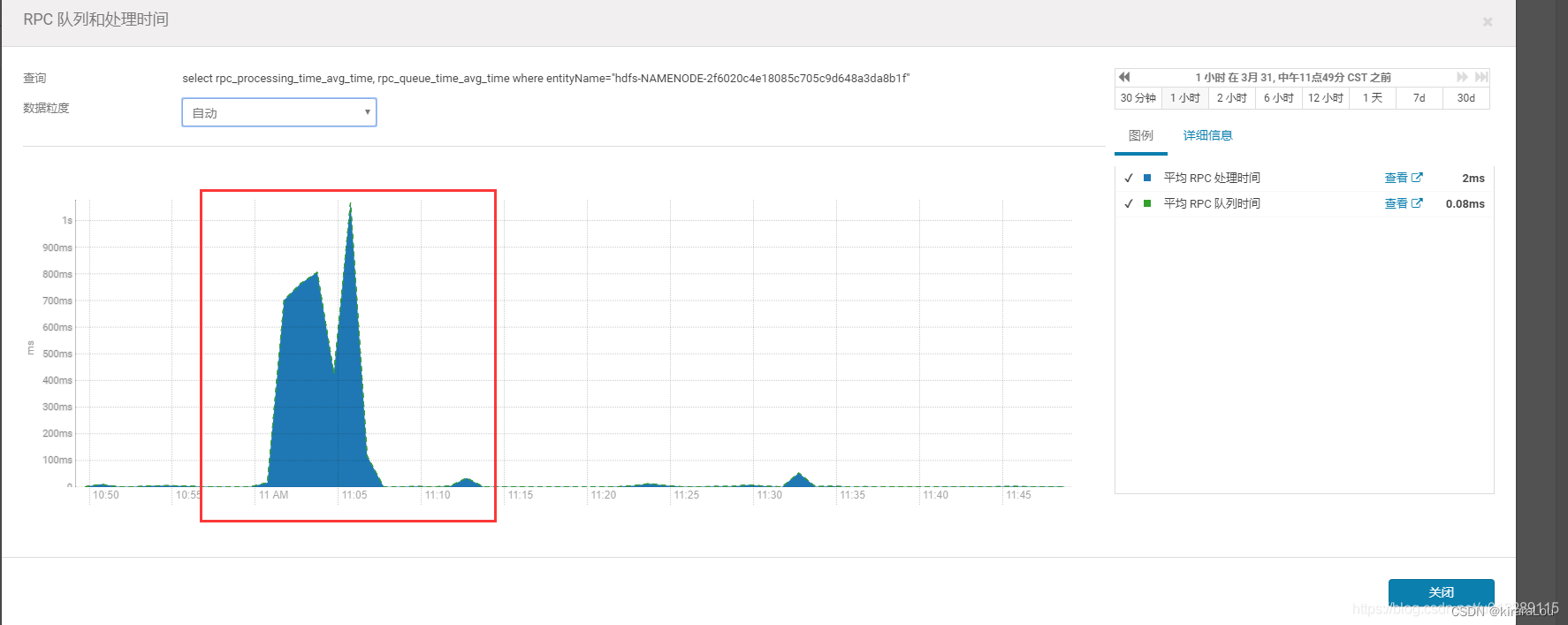
上图是NameNode rpc队列处理时间,11:06分有一个峰值,有rpc请求堆积,脚本报错时间是11:06,刚好吻合,说明上面分析正确。这个峰值范围内,可能在跑大量写数据的任务,NameNode压力大,处理不过来,导致请求堆积延迟,理论上所有单点的NameNode集群规模到了一定量级都会有这个问题
四、解决方案
短线:增加retry次数,默认5次,dfs.client.block.write.locateFollowingBlock.retries 改成10或更多
长线:现有的hadoop搭了HA,但是始终只有一个active状态,所有压力都在一个NameNode上,搭建hadoop Federation能同时多个active的NameNode,这样分担单点压力
————————————————
版权声明:本文为CSDN博主「喜剧之皇」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u013289115/article/details/105220663/

