【Kafka】flinkProducer kafka分区策略及kafka 默认分区策略
前言
最近在学习Flink 读写 Kafka, 突然想到如果 Flink 生产消息到Kafka,那么这条消息如何确定发往那个分区。顺便也回顾下 Kafka 本身一个默认分区策略和生产策略这里整理并记录下。
Flink 1.15Kafka 2.7
一、KafkaSink
FlinkKafkaProducer 已在 Flink 1.15 中删除 ,所以下文使用的 KafkaSink。
1. 默认
这里我们使用 KafkaSink 来将数据写入到 Kafka,那么KafkaSink 是如何确定一条消息要发送到那个分区?默认的策略是什么?
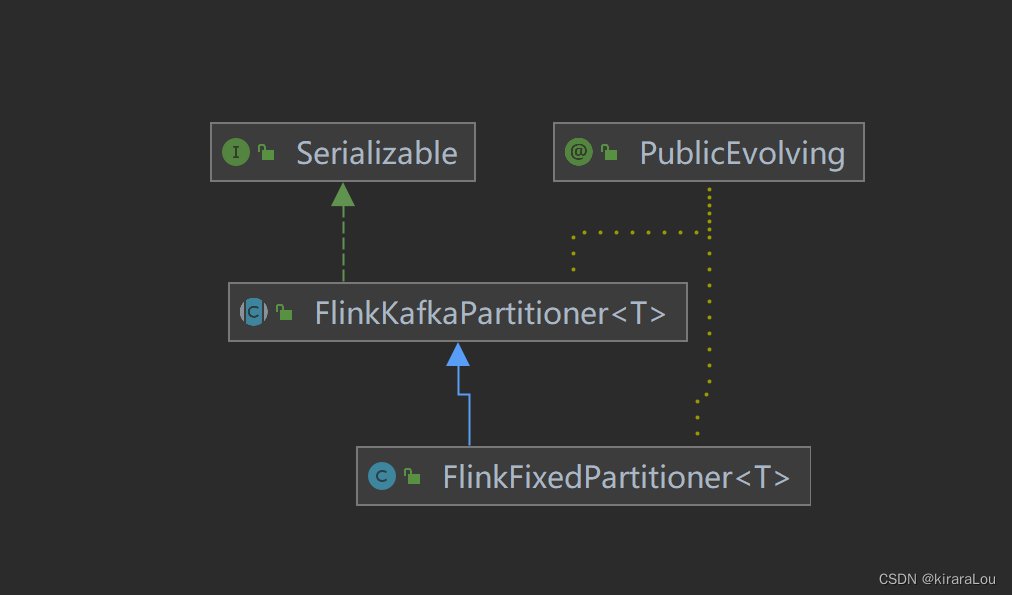
可以看到 KafkaSink 只有 FlinkFixedPartitioner 这一个默认的实现。
相关的分区策略代码如下:

public int partition(T record, byte[] key, byte[] value, String targetTopic, int[] partitions) {
Preconditions.checkArgument(partitions != null && partitions.length > 0, "Partitions of the target topic is empty.");
return partitions[this.parallelInstanceId % partitions.length];
}
可以看出 FlinkKafkaProducer 是根据Flink运行子任务的并行度进行分区数的取余写入的。计算公式如下。
partitions = parallelInstanceId % partitions.length
总结:Flink 默认的分区策略是并行度Id 与topic 分区数取模的结果,但是这样如果 并行度数 % partitions.length != 0 ,那么势必会造成分区负载不均衡。
2. null
当我们代码指定分区策略为 null 时,那么肯定就会选用Kafka 本身默认的分区策略。我们在下面介绍。
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers("59.110.32.152:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("test")
.setPartitioner(null)
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// 设置 ts 的id前缀
.setTransactionalIdPrefix("ts")
// 精确一次生产
.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setKafkaProducerConfig(properties)
.build();
二、Kafka 默认的分区策略
只针对Kafka来说,如何确认一条消息发送的分区?
Kafka2.4 前
对于Kafka 2.4 版本来说,有以下几个方式确定数据发送的分区。
- 非 key 写入的情况下,使用 轮询 (
round-robin) 的方式进行分区。 - 有 key 写入的情况下,使用 哈希 (
murmur2 哈希算法)的方式进行分区。 - 代码中指定消息写入的分区。
Kafka 2.4 后
- 非 key 写入的情况下,使用 粘性(
StickyPartitioning Strategy) 的方式进行分区。 - 有 key 写入的情况下,使用 哈希 (
murmur2 哈希算法)的方式进行分区。 - 代码中指定消息写入的分区。
StickyPartitioning Strategy
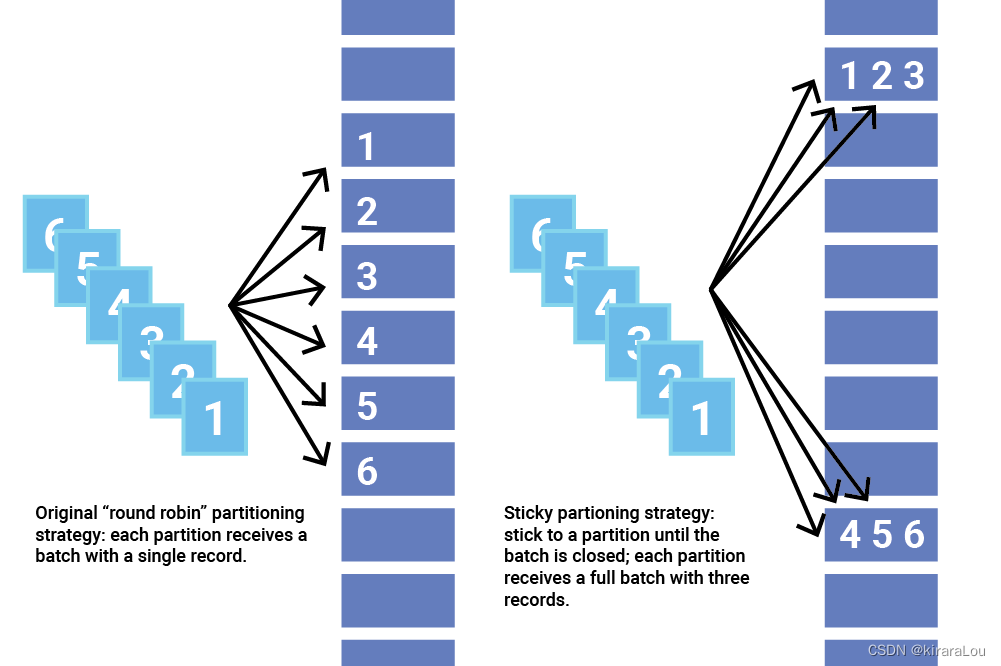
Kafka 2.4 之前的旧分区策略是循环遍历主题的分区并向每个分区发送一条记录。不幸的是,这种方法不能很好地批处理,实际上可能会增加延迟。
粘性分区器的主要目标是增加每个批次中的记录数,以减少批次总数并消除过度排队。当批次较少且每个批次中的记录较多时,每条记录的成本较低,并且使用粘性分区策略可以更快地发送相同数量的记录。
StickyPartitioning Strategy会随机地选择另一个分区并会尽可能地坚持使用该分区——即所谓的粘住这个分区
一旦该分区的批次被填充或以其他方式完成,粘性分区器会随机选择并“粘贴”到新分区。这样,在更长的时间内,记录大致均匀分布在所有分区中。
粘性分区器通过选择单个分区来发送所有非键记录,解决了将没有键的记录分散到更小的批次中的问题。
当 Kafka 生产者向主题发送记录时,它需要决定将其发送到哪个分区。如果我们几乎同时将几条记录发送到同一个分区,它们可以作为一个批次发送。处理每个批次需要一些开销,批次中的每条记录都会导致该成本。小批量的记录每条记录的有效成本更高。通常,较小的批次会导致更多的请求和排队,从而导致更高的延迟。
总结
- 如果不单独设置
partition策略,会默认使用FlinkFixedPartitioner,该partitioner分区的方式是 task 所在的并发 id 对 topic 总partition数取余:parallelInstanceId % partitions.length。 - 如果构建
FlinkKafkaProducer时,setPartition设置为null,此时会使用kafka producer默认分区方式。 - 对于
Kafka2.4版本前:
非 key 写入的情况下,使用round-robin的方式进行分区,每个 task 都会轮循的写下游的所有partition。该方式下游的partition数据会比较均衡。
带key 写入的情况下,使用 哈希算法。 - 对于
Kafka2.4版本后:
非key写入的情况下,使用粘性分区算法的方式进行分区。会随机指定一个分区,并尽可能往这个分区,同样使用该方式下游的partition数据也会比较均衡。
带key写入的情况下,使用 哈希算法。
参考:
https://www.confluent.io/blog/apache-kafka-producer-improvements-sticky-partitioner/https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/connectors/table/kafka/
