hive的行列转换2
需求:
孙悟空 白羊座 A
沙悟净 射手座 A
宋松松 白羊座 B
猪八戒 白羊座 A
小凤姐 射手座 A
转换成以下格式:
白羊座,A 孙悟空|猪八戒
白羊座,B 宋松松
射手座,A 沙悟净|小凤姐
思路:表的行转列
知识点:concat(string1,string2) string1和string2需要是列名
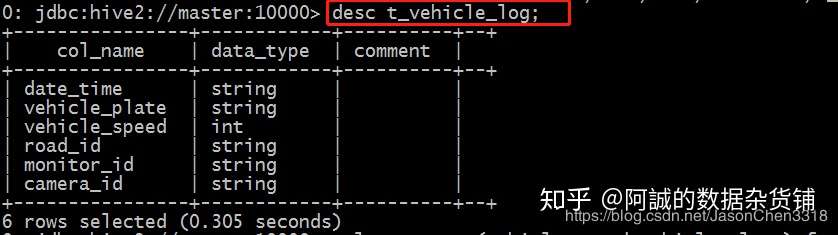
-- 使用hive的beeline客户端,使用t_vehicle_log,并查看该表的secma ./bin/beeline desc t_vehicle_log;
-- 对其中两列字段进行拼接
select concat(vehicle_speed,vehicle_plate) from t_vehicle_log;

--concat() 对拼接的两列字符串中间用,连接 select concat(vehicle_speed,",",vehicle_plate) from t_vehicle_log;
加入我们要拼接多个列,并且需要用同样的分隔符(如A,B,C,D),该怎么做呢?
——我们可以使用concat_ws()
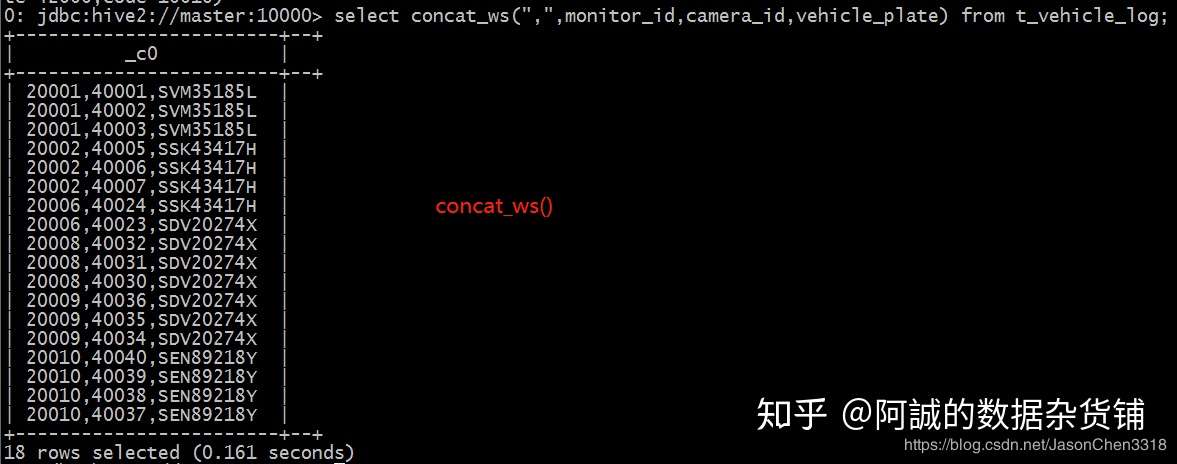
select concat_ws(",",monitor_id,camera_id,vehicle_plate) from t_vehicle_log;
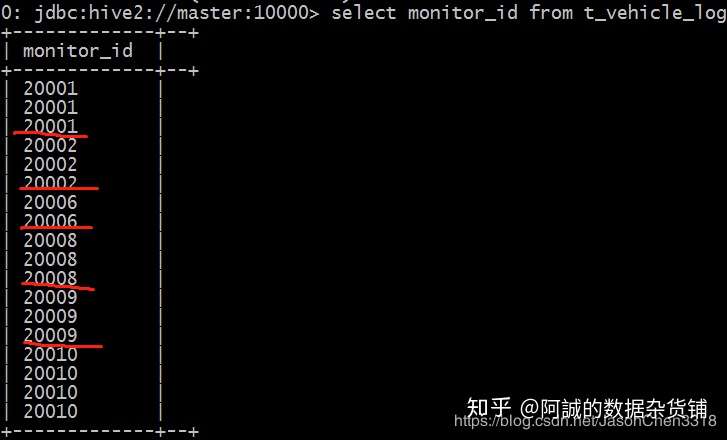
如果某一列有很多重复的字段,我们需要对其进行去重,并对去重字段返回一个数组,该怎么办呢?
—— 我们可以使用 collect_set()
select monitor_id from t_vehicle_log;
select collect_set(monitor_id) from t_vehicle_log;

以上为本次需求所需的知识点的讲解,下面开始解决本次需求:
-- 建表: create table person_info( name string, constellation string, blood_type string) row format delimited fields terminated by "\t";
-- 插数据
load data local inpath '/person_info.txt' into table person_info;
使用concat_ws()查询:
select concat_ws(",",constellation,blood_type) c_b,name from person_info;
结果:

对上一步结果作为子查询,在查询:
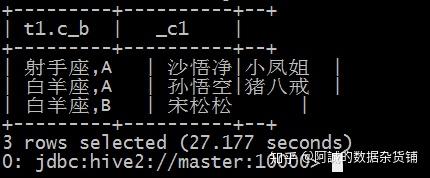
select t1.c_b, collect_set(t1.name) from( select concat_ws(",",constellation,blood_type) c_b, name from person_info ) t1 group by t1.c_b;
最终结果:collect_set()返回的是数组,concat_ws()接受的string或者是string数组

将数组划分开:
select t1.c_b, concat_ws("|",collect_set(t1.name)) from( select concat_ws(",",constellation,blood_type) c_b, name from person_info ) t1 group by t1.c_b;
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号