hive的几种join
作为数据分析中经常进行的join 操作,传统DBMS 数据库已经将各种算法优化到了极致,而对于hadoop 使用的mapreduce 所进行的join 操作,去年开始也是有各种不同的算法论文出现,讨论各种算法的适用场景和取舍条件,本文讨论hive 中出现的几种join 优化,然后讨论其他算法实现,希望能给使用hadoop 做数据分析的开发人员提供一点帮助.
Facebook 今年在yahoo 的hadoop summit 大会上做了一个关于最近两个版本的hive 上所做的一些join 的优化,其中主要涉及到hive 的几个关键特性: 值分区 , hash 分区 , map join , index ,
1、Common Join
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join.
整个过程包含Map、Shuffle、Reduce阶段。
- Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
按照key进行排序
- Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
- Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
以下面的HQL为例,图解其过程:
SELECT
a.id,a.dept,b.age
FROM a join b
ON (a.id = b.id);
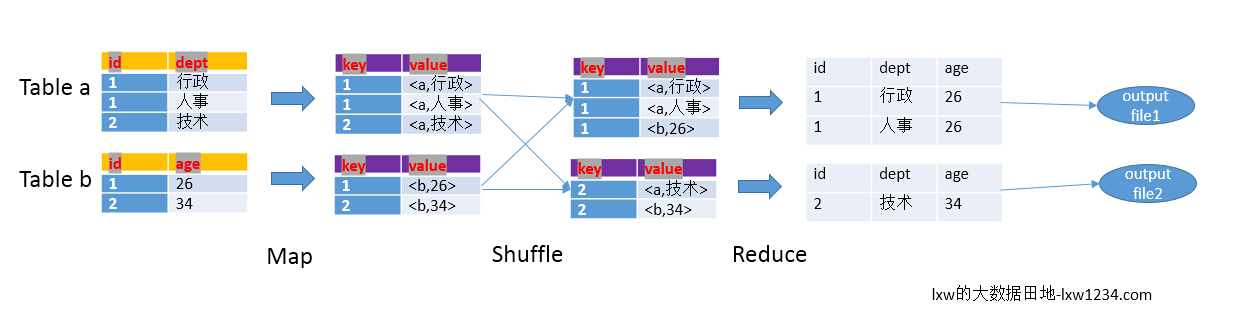
最为普通的join策略,不受数据量的大小影响,也可以叫做reduce side join ,最没效率的一种join 方式. 它由一个mapreduce job 完成.
首先将大表和小表分别进行map 操作, 在map shuffle 的阶段每一个map output key 变成了table_name_tag_prefix + join_column_value , 但是在进行partition 的时候它仍然只使用join_column_value 进行hash.
每一个reduce 接受所有的map 传过来的split , 在reducce 的shuffle 阶段,它将map output key 前面的table_name_tag_prefix 给舍弃掉进行比较. 因为reduce 的个数可以由小表的大小进行决定,所以对于每一个节点的reduce 一定可以将小表的split 放入内存变成hashtable. 然后将大表的每一条记录进行一条一条的比较.
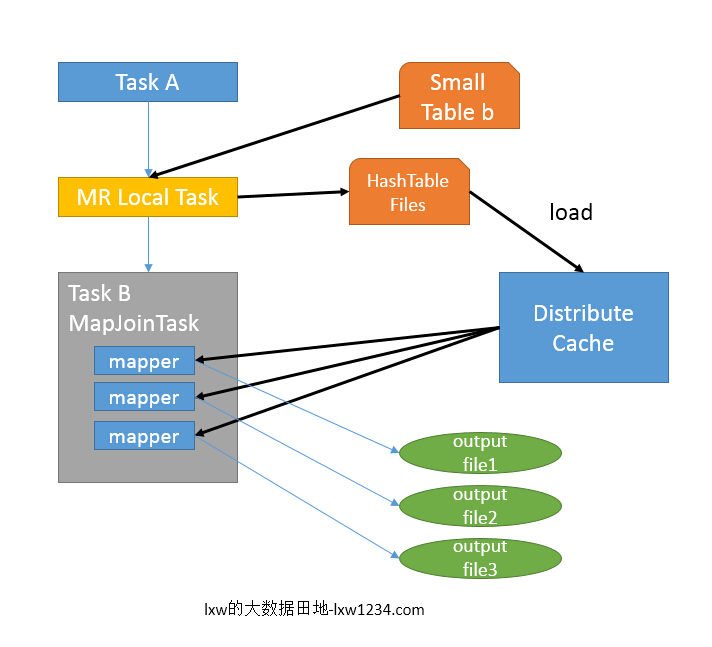
2、Map Join
Map Join 的计算步骤分两步,将小表的数据变成hashtable广播到所有的map 端,将大表的数据进行合理的切分,然后在map 阶段的时候用大表的数据一行一行的去探测(probe) 小表的hashtable. 如果join key 相等,就写入HDFS.
map join 之所以叫做map join 是因为它所有的工作都在map 端进行计算.
hive 在map join 上做了几个优化:
-
hive 0.6 的时候默认认为写在select 后面的是大表,前面的是小表, 或者使用 /*+mapjoin(map_table) */ 提示进行设定. hive 0.7 的时候这个计算是自动化的,它首先会自动判断哪个是小表,哪个是大表,这个参数由(hive.auto.convert.join=true)来控制. 然后控制小表的大小由(hive.smalltable.filesize=25000000L)参数控制(默认是25M),当小表超过这个大小,hive 会默认转化成common join. 你可以查看HIVE-1642.
-
首先小表的Map 阶段它会将自己转化成MapReduce Local Task ,然后从HDFS 取小表的所有数据,将自己转化成Hashtable file 并压缩打包放入DistributedCache 里面.
目前hive 的map join 有几个限制,一个是它打算用BloomFilter 来实现hashtable , BloomFilter 大概比hashtable 省8-10倍的内存, 但是BloomFilter 的大小比较难控制.
现在DistributedCache 里面hashtable默认的复制是3份,对于一个有1000个map 的大表来说,这个数字太小,大多数map 操作都等着DistributedCache 复制.
3、Bucket Map Join
hive 建表的时候支持hash 分区通过指定clustered by (col_name,xxx ) into number_buckets buckets 关键字.
当连接的两个表的join key 就是bucket column 的时候,就可以通过
hive.optimize.bucketmapjoin= true
来控制hive 执行bucket map join 了, 需要注意的是你的小表的number_buckets 必须是大表的倍数. 无论多少个表进行连接这个条件都必须满足.(其实如果都按照2的指数倍来分bucket, 大表也可以是小表的倍数,不过这中间需要多计算一次,对int 有效,long 和string 不清楚)
Bucket Map Join 执行计划分两步,第一步先将小表做map 操作变成hashtable 然后广播到所有大表的map端,大表的map端接受了number_buckets 个小表的hashtable并不需要合成一个大的hashtable,直接可以进行map 操作,map 操作会产生number_buckets 个split,每个split 的标记跟小表的hashtable 标记是一样的, 在执行projection 操作的时候,只需要将小表的一个hashtable 放入内存即可,然后将大表的对应的split 拿出来进行判断,所以其内存限制为小表中最大的那个hashtable 的大小.
Bucket Map Join 同时也是Map Side Join 的一种实现,所有计算都在Map 端完成,没有Reduce 的都被叫做Map Side Join ,Bucket 只是hive 的一种hash partition 的实现,另外一种当然是值分区.
create table a (xxx) partition by (col_name)
不过一般hive 中两个表不一定会有同一个partition key, 即使有也不一定会是join key. 所以hive 没有这种基于值的map side join, hive 中的list partition 主要是用来过滤数据的而不是分区. 两个主要参数为(hive.optimize.cp = true 和 hive.optimize.pruner=true)
hadoop 源代码中默认提供map side join 的实现, 你可以在hadoop 源码的src/contrib/data_join/src 目录下找到相关的几个类. 其中TaggedMapOutput 即可以用来实现hash 也可以实现list , 看你自己决定怎么分区. Hadoop Definitive Guide 第8章关于map side join 和side data distribution 章节也有一个例子示例怎样实现值分区的map side join.
4、Sort Merge Bucket Map Join
Bucket Map Join 并没有解决map join 在小表必须完全装载进内存的限制, 如果想要在一个reduce 节点的大表和小表都不用装载进内存,必须使两个表都在join key 上有序才行,你可以在建表的时候就指定sorted by join key 或者使用index 的方式.
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
Bucket columns == Join columns == sort columns
这样小表的数据可以每次只读取一部分,然后还是用大表一行一行的去匹配,这样的join 没有限制内存的大小. 并且也可以执行全外连接.
例子参考:http://superlxw1234.iteye.com/blog/1545150
5、Skew Join
真实数据中数据倾斜是一定的, hadoop 中默认是使用
hive.exec.reducers.bytes.per.reducer = 1000000000
也就是每个节点的reduce 默认是处理1G大小的数据,如果你的join 操作也产生了数据倾斜,那么你可以在hive 中设定
set hive.optimize.skewjoin = true;
set hive.skewjoin.key = skew_key_threshold (default = 100000)
hive 在运行的时候没有办法判断哪个key 会产生多大的倾斜,所以使用这个参数控制倾斜的阈值,如果超过这个值,新的值会发送给那些还没有达到的reduce, 一般可以设置成你
(处理的总记录数/reduce个数)的2-4倍都可以接受.
倾斜是经常会存在的,一般select 的层数超过2层,翻译成执行计划多于3个以上的mapreduce job 都很容易产生倾斜,建议每次运行比较复杂的sql 之前都可以设一下这个参数. 如果你不知道设置多少,可以就按官方默认的1个reduce 只处理1G 的算法,那么 skew_key_threshold = 1G/平均行长. 或者默认直接设成250000000 (差不多算平均行长4个字节)
6、Left Semi Join
hive 中没有in/exist 这样的子句,所以需要将这种类型的子句转成left semi join. left semi join 是只传递表的join key给map 阶段 , 如果key 足够小还是执行map join, 如果不是则还是common join.
join 策略中的难点
大多数只适合等值连接(equal join) ,
范围比较和全外连接没有合适的支持
提前分区,零时分区,排序,多种不同执行计划很难评价最优方案.
没有考虑IO 比如临时表,网络消耗和网络延迟时间,CPU时间,
最优的方案不代表系统资源消耗最少.
join 策略中的难点
大多数只适合等值连接(equal join) ,
范围比较和全外连接没有合适的支持
提前分区,零时分区,排序,多种不同执行计划很难评价最优方案.
没有考虑IO 比如临时表,网络消耗和网络延迟时间,CPU时间,
最优的方案不代表系统资源消耗最少.
对于common join 这样的内部也稍微有点区别
通过 explain dependency这样分析输入数据源 也可以判断出细微的区别
inner join
对于inner join 左表和右表 当有非等值过滤条件时,可以按照过滤条件进行过滤。
左表有过滤条件,只过滤左表,右表不过滤
右表有过滤条件,只过滤右表,左表不过滤
左右表有过滤条件,同时过滤
案例如下:
explain dependency select * from student_part a inner join student_part_parquet b
on a.s_name = b.s_name and a.s_age <23;

左4 右7
explain dependency select * from student_part a inner join student_part_parquet b
on a.s_name = b.s_name and b.s_age <23;

左7 右4
explain dependency select * from student_part a inner join student_part_parquet b
on a.s_name = b.s_name and b.s_age <23 and a.s_age >24;

左2 右3
left join
只过滤左表 左表无过滤 右表有过滤
只过滤右表 左表无过滤 右表有过滤
同时过滤左右表 左表无过滤 右表有过滤
只过滤左表 ---结果 左7 右 7 无过滤
explain dependency select * from student_part a left outer join student_part_parquet b
on a.s_name = b.s_name and a.s_age <23;

只过滤右表 ---结果 左7 右 3 左表无过滤,右表有过滤
explain dependency select * from student_part a left outer join student_part_parquet b
on a.s_name = b.s_name and b.s_age <23;

同时过滤左右表 ---结果 左7 右 3 左表无过滤,右表有过滤
explain dependency select * from student_part a left outer join student_part_parquet b
on a.s_name = b.s_name and b.s_age <23 and a.s_age >25;

所以建议尽早在子查询中,提前过滤数据。

