hive中row_number() rank() dense_rank()的用法
1.函数说明
主要是配合over()窗口函数来使用的,通过over(partition by order by )来反映统计值的记录。
1. rank() over()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
2. dense_rank() over()是连续排序,有两个第二名时仍然跟着第三名。相比之下 row_number是没有重复值的
3. row_number() 会根据顺序计算,仅仅是加了序号
2.应用场景
可以用于学生成绩排名
row_number()按照值排序时产生一个自增编号,不会重复(如:1、2、3、4、5、6)
rank() 按照值排序时产生一个自增编号,值相等时会重复,会产生空位(如:1、2、3、3、3、6)
dense_rank() 按照值排序时产生一个自增编号,值相等时会重复,不会产生空位(如:1、2、3、3、3、4)
下面开始学习这几个函数:
有以下数据:字段名为:name、orderdate、cost
Jack,2017-01-01,10
Tony,2017-01-02,15
Jack,2017-02-03,23
Tony,2017-01-04,29
Jack,2017-01-05,46
Jack,2017-04-06,42
Tony,2017-01-07,50
Jack,2017-01-08,55
Mark,2017-04-08,62
Mart,2017-04-09,68
Meil,2017-05-10,12
Mart,2017-04-11,75
Meil,2017-06-12,80
Mart,2017-04-13,94
创建表:
create table business(
name string,
orderdate string,
cost int)
row format delimited
fields terminated by ",";
加载数据:
load data local inpath "/root/business.txt" into table business;
1、row_number() over()排序功能:
(1) row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where group by order by 的执行。
partition by 用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,它和聚合函数不同的地方在于它能够返回一个分组中的多条记录,而聚合函数一般只有一个反映统计值的记录。
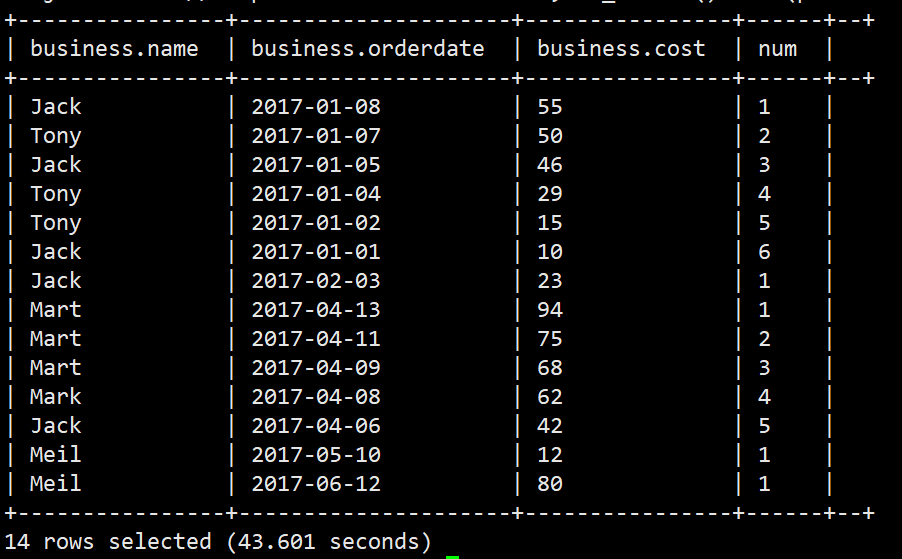
例子:按月份来查询,根据cost来降序排序:
select *,row_number() over(partition by substr(orderdate,1,7) order by cost desc) as num
from business;
2、rank() over()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
为了演示效果,我们再把txt文件导入hive中,相当于hive表中有2份相同的数据
导入数据:
load data local inpath "/root/business.txt" into table business;
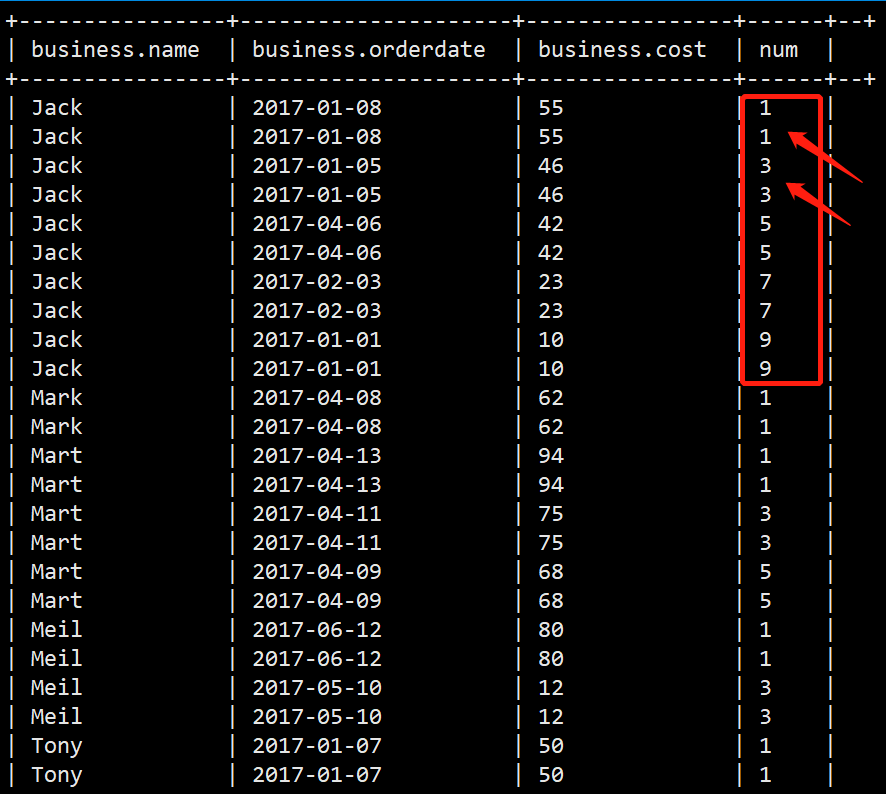
例子:按名字分组,并按照金额进行排序,给出编号
select *,rank() over(partition by name order by cost desc) as num from business;
3、dense_rank() over()是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的
还是上面那个例子:按名字分组,按金额降序排序,给出序号
select *,dense_rank() over(partition by name order by cost desc) as num from business;


