【10分钟入门】想学爬虫?关于正则表达式,看这一篇就够了!
最近接触到正则表达式,用于匹配对应的字符串,觉得很神奇,于是开始一个学习。
有句老话说得好:“爬虫写得好,牢范吃得饱。”哈哈哈当然是开个玩笑。
工具推荐
regex101: build, test, and debug regex
这个网站可以帮助我们实时地测试RegExp(正则表达式),后面的教程都在这个平台上进行。
RegEx中各种符号的用法
要学习RegEx首先要学会各种符号的用法。
1.限定符
限定符仅作用与左边一个字符,或左边的一块表达式。
- ? 表示可以出现0次或1次,也就是可有可无
- + 表示可以出现1次或多次
- * 表示可以出现任意次
- {x} 表示必须出现x次,
- {l, r} 表示出现次数必须在闭区间[l, r]之间,可以省略一个,下界默认为0,上界默认无穷
假如我要在一些字符中找出以a开头,以c结尾,中间有若干个b的字符串,可以像下面这样写:
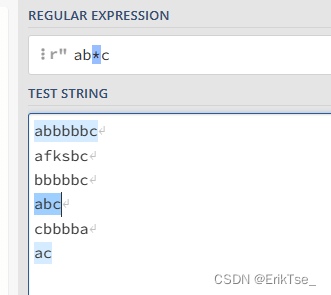
也可以这样写:
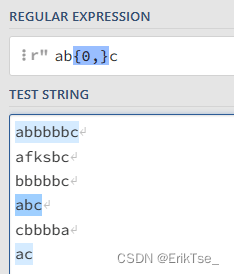
不难发现,前面的这些?+*都可以用{}来表达,不过为了方便就会用前面的表示。
2.“或”运算
在几乎所有编程语言中都有或运算来表示一个不太好一步表示的逻辑集合,在RegExp中也可以。
符号:| 可以将左右两个表达式取并集作为新的表达式,但优先级低于表达式的拼接
比如我要得到所有的a和an,就可以像下面这样写。注意两边要用括号和\b包围起来,\b确保这是一个单词而不是一个单词的一部分,括号是为了防止把"\ba"和"an\b"作为两个表达式,我们的表达式应该是a和an。
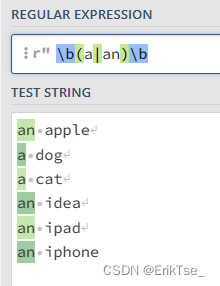
3.字符类
格式:[abc]表示这一位可以是abc中的任意字符,也可以用区间来表示,比如[a-z]表示这一位可以是一个小写字母,[a-zA-Z0-9]+表示这里可以是一个或多个“大写字母或小写字母或数字”。
举个例子,我要匹配所有格式为"班级+学号"中找出所有zy02班的人,可以像下图这样做。
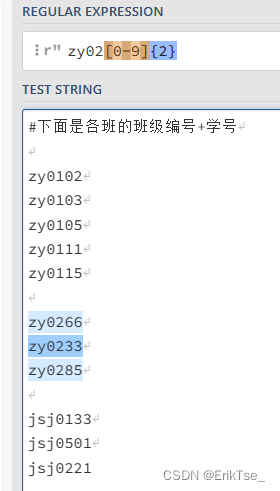
如果要找出所有jsj1班到3班的,可以像下面这样做。
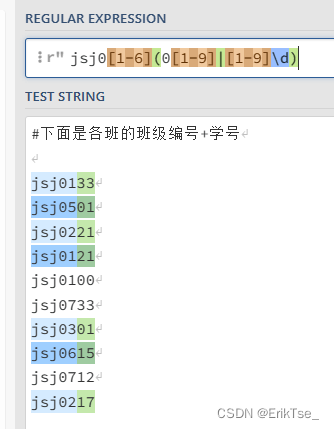
这里的\d和[0-9]等价。值得注意的是这里的非法学号jsj0100没有被匹配到。
也可以在 [ ] 的开头添加一个 ^ 字符,表示排除。
4.元字符
- \d 表示数字
- \D 表示非数字
- \w 表示字母、数字和下划线
- \W 表示非字母、数字和下划线
- \s 表示空白字符
- \S 表示非空白字符
- ^ 匹配行首
- $ 匹配行尾
5.贪婪匹配与懒惰匹配
RegExp默认匹配模式为贪婪匹配,也就是尽可能长。
假如我在一段HTML中想要匹配出每一个<>标签,如果像下面这样写,会把整个文档作为一个长字符串匹配。
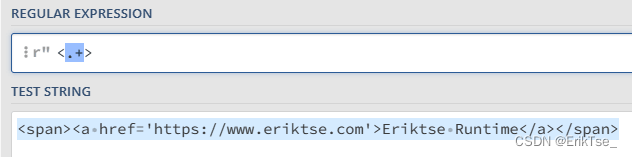
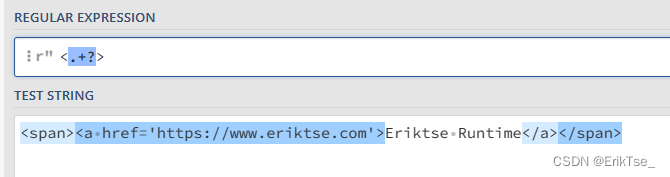
这显然不是我们想要的结果,我们就可以利用?来改为懒惰匹配。
修饰符
引用一段菜鸟教程的文章《正则表达式 – 修饰符(标记) | 菜鸟教程》,直接偷懒一手。
一般会用/g,表示global全局搜索。
在Python中使用RegEx
python需要先引入re库,这是一个很强大的字符串匹配库。
我们利用re.search(pattern, string[, flags])来做匹配,会返回一个结果组成的元组,如果没找到返回None,常用于判断。
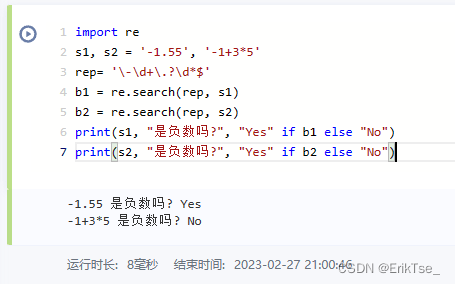
假如我要在python中识别一段式子是一个负数,还是一个表达式时,可以这样匹配:
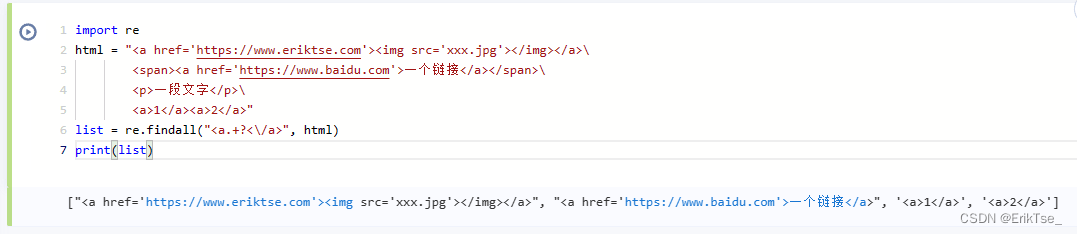
再举个例子,假如我要在一段html中找出所有a标签,可以像下面这样做,,re.findall返回一个list。
本文结束啦,感谢大家的阅读,如果本文对你有用的话欢迎点赞收藏和关注!
