Redis集群
为什么要redis集群?
即使有了主从复制,每个数据库都要保存整个集群中的所有书,这样很容易造成木桶效应。使用Jedis实现了分片集群,是由客户端决定哪些key数据放到哪个数据库中,如果在水平扩容时就需要手动的进行数据的迁移,而且需要将整个redis停止服务,这样是及其不好的,所以redis3.0引入了集群。
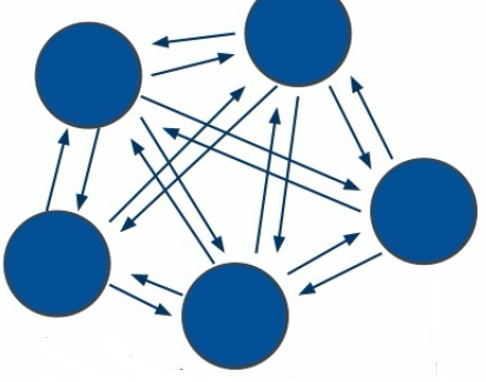
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
(2)节点的fail是通过集群中超过半数的节点检测失效时才会生效。
(3)客户端与redis节点直连,不需要中间proxy层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
(4)redis-cluster把所欲的物理节点映射到[0-16383]slot插槽上,cluster负责维护node<->slot<->value.
配置集群
1.修改配置文件
(1)设置不同的端口
(2)开启集群cluster-enabled yes
(3)指定集群的配置文件,cluster-config-file "nodes-xxxx.conf"
2.创建集群环境
(1)安装ruby环境(redis5.0及以上不用安装ruby环境)
(2)创建集群

插槽的分配
通过cluster nodes命令可以查看当前集群的信息。

该信息反映了集群中的每一个节点的id、身份、连接数、插槽数。
当我们执行set命令时,redis是如何将数据保存到redis集群中的?
1.接收set命令
2.通过key计算出插槽值,根据插槽值找到相应的节点
3.重定向到该节点执行命令
整个redis提供了18364个插槽
插槽和key的关系
计算key的插槽值:key的有效部分使用CRC16算法计算出hash值,再将hash值对16384取余,得到插槽值。
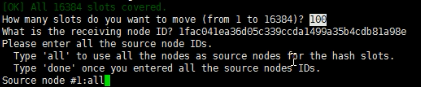
新增集群节点

重新分配插槽:

删除集群节点
想要删除集群中的某个节点,必须严格的执行两步:
(1)将这个节点上的所有插槽全部移到其他节点上;
(2)使用redis-trib.rb删除节点

Redis故障转移机制
1.集群中的每个节点都会定期的向其他节点发送PING命令,并且通过有没有收到恢复判断目标节点是都下线;
2.集群中每一秒就会随机选择5个节点,然后选择其中最久没有响应的节点发送PING命令;
3.如果一定时间内目标节点都没有响应,那么该节点就认为目标节点疑似下线;
4.当集群中的节点超过半数认为该目标节点疑似下线,那么该节点就会标记为下线;
5.当集群中的任何一个节点下线,就会导致插槽区有空档,不完整,那么该集群将不可用;
6.如何解决上述问题?
a)在redis集群中可以使用主从模式实现某一个节点的高可用
b)当该节点(master)宕机后,集群会将该节点的从库(slave)转变为主库(master)继续完成集群服务。
使用集群需要注意的事项
1.多键的命令操作(如MGET、MSET),如果每个键都位于同一个节点,则可以正常支持,否则会提示错误。
2.集群中的节点只能使用0号数据库,如果执行SELECT切换数据库会提示错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号