爬虫--scrapy框架
框架:集成了很多功能并且具有很强通用型的一个项目模板
如何学习框架: 学习框架封装功能的用法; 框架进阶:学习源码及编程思想
scrapy: 高性能持久化存储,异步的数据下载,高性能的数据分析,分布式
scrapy框架的基本使用:
--环境安装:
mac / linux :pip install scrapy windows: 1.pip install wheel 2.pip install twisted 3.pip install pywin32 4.pip install scrapy
终端里录入scrapy指令,无报错即安装成功
--创建工程:
cd到你想创建的文件夹内,输入指令 scrapy startproject xxxPro
# 工程创建成功后,在spiders子目录中创建一个爬虫文件
cd xxxPro
scrapy genspider spidername www.xxx.com
# 后续爬虫代码都是写在一个个的爬虫文件中
--执行工程:
# 执行工程
scrapy crawl spidername
--基本使用设置:
# Obey robots.txt rules ROBOTSTXT_OBEY = False # 显示指定类型的日志信息 LOG_LEVEL = 'ERROR'
import scrapy class RedSpiderSpider(scrapy.Spider): # 爬虫文件的名称:爬虫源文件的唯一标识 name = 'red_spider' # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送 # 这个参数多数情况下不会启用 # allowed_domains = ['www.xxx.com'] # 起始的url列表:该列表中存放的url会被scrapy自动进行请求发送 start_urls = ['https://www.baidu.com/','https://www.sogou.com'] # 用作数据解析:response参数表示的就是请求成功后对应的响应对象 # 上述每一个url请求发送返回一个response,然后每个response自动调用parse def parse(self, response): print(response)
scrapy数据解析基本代码:
import scrapy class RedSpiderSpider(scrapy.Spider): # 爬虫文件的名称:爬虫源文件的唯一标识 name = 'red_spider' # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送 # 这个参数多数情况下不会启用 # allowed_domains = ['www.xxx.com'] # 起始的url列表:该列表中存放的url会被scrapy自动进行请求发送 start_urls = ['https://www.pearvideo.com/category_8'] # 用作数据解析:response参数表示的就是请求成功后对应的响应对象 # 上述每一个url请求发送返回一个response,然后每个response自动调用parse def parse(self, response): li_list = response.xpath('//ul[@id="listvideoListUl"]/li') print(li_list) for li in li_list: # 在scrapy框架中,xpath返回的是Selector类型的对象列表,不是之前模块中的列表 # extract()方法可以将Selector对象中data参数存储的字符串提取出来 # 如果对象列表调用了extract()方法后,则返回Selector列表中对象的字符串组成的一个列表 title = li.xpath('.//div[@class="vervideo-title"]/text()')[0].extract() img_src = li.xpath('.//div[@class="img"]/@style')[0].extract() print(title,img_src) # 注意执行方法是在终端中输入:scrapy crawl red_spider
scrapy持久化存储:
--基于终端指令的持久存储
1.要求:只可以将parse方法的返回值存储到本地的文本文件中,无法存储在数据库中
2.终端指令只能将数据存储为json,jsonlines,jl,csv,xml,marshal,pickle
3.简洁高效便捷,但是具有局限性
def parse(self, response): li_list = response.xpath('//ul[@id="listvideoListUl"]/li') data_list = [] for li in li_list: # 在scrapy框架中,xpath返回的是Selector类型的对象列表,不是之前模块中的列表 # extract()方法可以将Selector对象中data参数存储的字符串提取出来 # 如果对象列表调用了extract()方法后,则返回Selector列表中对象的字符串组成的一个列表 title = li.xpath('.//div[@class="vervideo-title"]/text()')[0].extract() img_src = li.xpath('.//div[@class="img"]/@style')[0].extract() # 持久化存储操作,基于终端指令,只能将parse方法的返回值存储到本地 # 只能存储为json,jsonlines,jl,csv,xml,marshal,pickle # 终端持久化存储指令:scrapy crawl red_spider -o ./data.csv dic = { 'title':title, 'img_src':img_src, } data_list.append(dic) return data_list
--基于管道的持久化存储
编码流程:
1.数据解析
2.在item类中定义相关的属性
3.将解析的数据分装存储到item类型的对象
4.将item类型的对象提交给管道进行持久化存储的操作
5.在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
6.在配置文件中开启管道
优点:通用型强,但略复杂
注:
--管道文件中一个管道类对应的是将数据存储到一个平台
--爬虫文件提交的item只会给管道文件中第一个被执行的管道类接受
--process_item中return item表示将item传递给下一个即将被执行的管道类
# red_spider.py
import scrapy from myscrapy.items import MyscrapyItem # 红色报错为误报,代码正常 class RedSpiderSpider(scrapy.Spider): # 爬虫文件的名称:爬虫源文件的唯一标识 name = 'red_spider' # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送 # 这个参数多数情况下不会启用 # allowed_domains = ['www.xxx.com'] # 起始的url列表:该列表中存放的url会被scrapy自动进行请求发送 start_urls = ['https://www.pearvideo.com/category_8'] # 用作数据解析:response参数表示的就是请求成功后对应的响应对象 # 上述每一个url请求发送返回一个response,然后每个response自动调用parse def parse(self, response): li_list = response.xpath('//ul[@id="listvideoListUl"]/li') for li in li_list: # 在scrapy框架中,xpath返回的是Selector类型的对象列表,不是之前模块中的列表 # extract()方法可以将Selector对象中data参数存储的字符串提取出来 # 如果对象列表调用了extract()方法后,则返回Selector列表中对象的字符串组成的一个列表 title = li.xpath('.//div[@class="vervideo-title"]/text()')[0].extract() img_src = li.xpath('.//div[@class="img"]/@style')[0].extract() # 从MyscrapyItem类中生成对象 item = MyscrapyItem() item['title'] = title item['img_src'] = img_src # 将item提交给管道 yield item # 注意执行方法是在终端中输入:scrapy crawl red_spider
# pipelines.py
from itemadapter import ItemAdapter import pymysql class MyscrapyPipeline: fp = None # 重写父类的一个方法:该方法只在爬虫开始的时候被调用一次 def open_spider(self, spider): print('开始爬虫...') self.fp = open('./红色爬虫数据.txt', 'w', encoding='utf-8') # 专门用来处理item类对象 # 该方法可以接收爬虫文件提交过来的item对象 # 该方法每接收到一个item就会被调用一次 def process_item(self, item, spider): title = item['title'] img_src = item['img_src'] self.fp.write(title + ':' + img_src + '\n') return item # 有这个return,就会传递给下一个即将被执行的管道类 def close_spider(self, spider): print('结束爬虫!') self.fp.close() # 管道文件中一个管道类对应将一个数据存储到一个平台或者载体中 # 将数据存储到mysql中 class MysqlPipeline: conn = None cursor = None def open_spider(self, spider): self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='123456', db='redspider', charset='utf-8') def process_item(self, item, spider): self.cursor = self.conn.cursor() try: self.cursor.execute('insert into redspider values("%s","%s")'%(item["title"],item["img_src"])) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def close_spider(self, spider): self.cursor.close() self.conn.close()
# settings.py
BOT_NAME = 'myscrapy' SPIDER_MODULES = ['myscrapy.spiders'] NEWSPIDER_MODULE = 'myscrapy.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome...' # Obey robots.txt rules ROBOTSTXT_OBEY = False # 显示指定类型的日志信息 LOG_LEVEL = 'ERROR' ITEM_PIPELINES = { 'myscrapy.pipelines.MyscrapyPipeline': 300, #300表示的是优先级,数值越小优先级越高 'myscrapy.pipelines.MysqlPipeline': 301, #300表示的是优先级,数值越小优先级越高 }
基于spider的全站数据爬取
--将某网站板块下的全部页码对应的页面数据进行爬取
--实现方式:
--1.将所有页码的url都单独进行爬取(可行,但页码特别多的时候不方便)
--2.自行手动进行请求发送
-- yield scrapy.Request(url=new_url,callback=self.parse)
class WhitespiderSpider(scrapy.Spider): name = 'whiteSpider' # allowed_domains = ['example.com'] # start_urls中的url列表会被自动发送请求,每一个请求收到的response会自动调用parse函数 start_urls = ['https://www.xxx.com/category/xxx'] # 生成一个通用的url模板 url = 'https://www.xxx.com/category/xxx/page/%d' page_num = 2 def parse(self, response): article_list = response.xpath('//div[@class="article-container "]/article') for article in article_list: title = article.xpath('.//a/@title')[0].extract() img_src = article.xpath('.//img/@data-src')[0].extract() print(title,img_src) if self.page_num <= 11: new_url = format(self.url%self.page_num) self.page_num += 1 # 手动请求发送,callback回调函数是专门用于数据解析 yield scrapy.Request(url=new_url,callback=self.parse)
五大核心组件
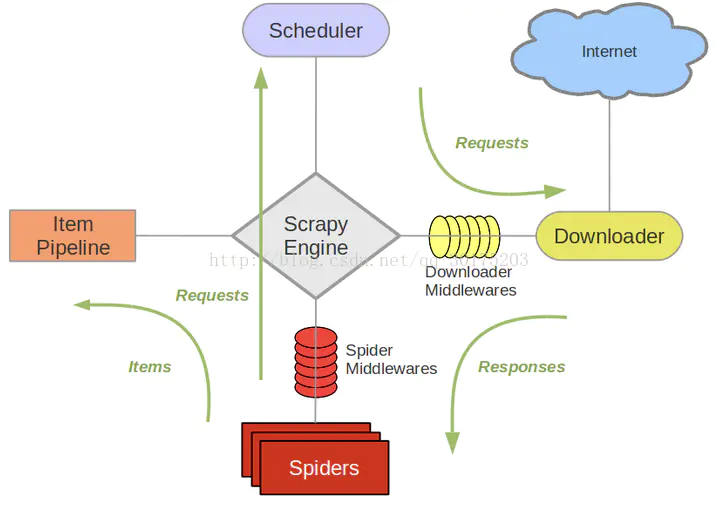
引擎: 用来处理整系统的数据流处理,触发事务(框架核心)
调度器: 接收引擎发送过来的请求,去除重复网址,将请求放入队列中,并在引擎再次请求时返回
下载器:下载网页内容,并将网页内容返回给蜘蛛(异步下载,建立在twisted异步模块上)
爬虫:干活的,从网页爬取信息
项目管道:负责处理爬虫从网页中获取的信息,持久化存储,清除过滤不需要的信息.
scrapy框架工作流程:
Scrapy运行流程大概如下:
首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取,
引擎把URL封装成一个请求(Request)传给下载器,
下载器把资源下载下来,并封装成应答包(Response)
然后,爬虫解析Response
若是解析出实体(Item),则交给实体管道进行进一步的处理。
若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
请求传参: 给request传递参数
使用场景: 爬取解析的数据不在同一张页面中,需要深度爬取(比如展示页--详情页),传递item参数等
import scrapy from mywhitespider.items import MywhitespiderItem class WhitespiderSpider(scrapy.Spider): name = 'whiteSpider' # allowed_domains = ['example.com'] # start_urls中的url列表会被自动发送请求,每一个请求收到的response会自动调用parse函数 start_urls = ['https://www.fuzokuu.com/category/fuzokuuguide-thailand/thailand-basic'] # 生成一个通用的url模板 url = 'https://www.fuzokuu.com/category/fuzokuuguide-thailand/thailand-basic/page/%d' page_num = 2 def parse(self, response): article_list = response.xpath('//div[@class="article-container "]/article') for article in article_list: title = article.xpath('.//a/@title')[0].extract() # 获取内容页url,为深度爬取做准备 content_url = article.xpath('.//a/@href')[0].extract() img_src = article.xpath('.//img/@data-src')[0].extract() item = MywhitespiderItem() item['title'] = title item['img_src'] = img_src # 内容页发请求获取详情页的页面源码数据,parse_detail为自定义的处理详情页数据的函数,和parse类似 # 请求传参:meta={},可以将meta字典传递给请求对应的回调函数 yield scrapy.Request(content_url,callback=self.parse_detail,meta={'item':item}) print(title,content_url,img_src) if self.page_num <= 11: new_url = format(self.url%self.page_num) self.page_num += 1 # 手动请求发送,callback回调函数是专门用于数据解析 yield scrapy.Request(url=new_url,callback=self.parse) # 自定义的深度页面解析函数 def parse_detail(self,response): item = response.meta['item'] content = response.xpath('//div[@id="content"]//div[@class="entry-content"]') content = ''.join(content) item['content'] = content yield item
图片数据爬取之ImagesPipeline
--专门用于图片数据爬取
--xpath只能解析到图片的地址,还需要单独的对图片地址发起请求获取图片二进制类型的数据
--只需要抓取图片src地址,提交到ImagesPipline,管道会自动请求图片地址并持久化存储
防爬措施:图片软加载--只显示屏幕上的图片,滚轮拖动多少加载多少图片,无可视化界面即无图片真正加载
反制:抓取伪属性,多看看其中的一个属性,其中一个应该为伪属性
使用流程:
1.数据解析出图片的地址
2.将存储图片地址的item提交到制定的管道类
3.在管道文件中自定义一个基于ImagePipeline的管道类,重写三个方法:
--get_media_requests()
--file_path()
--item_completed()
4.在配置文件中指定图片存储目录:IMAGE_STORE = './imgs'
5.在配置中注册开启自定义的管道类
items.py文件和蜘蛛文件都不需要修改,只要item中有对应的图片地址即可
# pipelines.py
import scrapy from itemadapter import ItemAdapter from scrapy.pipelines.images import ImagesPipeline # 这是字符串或二进制文件的管道 class MywhitespiderPipeline: def process_item(self, item, spider): return item # 自定义一个处理图片的管道(记得在settings中注册管道) class ImgsPipline(ImagesPipeline): # 该函数根据图片地址进行图片数据的请求 def get_media_requests(self, item, info): yield scrapy.Request(item['img_src']) # 指定图片存储的路径 def file_path(self, request, response=None, info=None, *, item=None): # img_name = request.url.split('/')[-1] img_name = item['title'] + '.jpg' return img_name def item_completed(self, results, item, info): return item # 返回给下一个即将被执行的管道类
# settings.py
# 注册自定义的管道 ITEM_PIPELINES = { 'mywhitespider.pipelines.MywhitespiderPipeline': 300, 'mywhitespider.pipelines.ImgsPipline': 299, } # 指定图片存储的目录 IMAGES_STORE = './imgs'
scrapy中间件:
两个中间件:引擎和下载器之间--下载器中间件 引擎和爬虫之间--爬虫中间件
下载器中间件:
--能够批量拦截到整个工程中所有的请求和响应
--拦截请求:
--UA伪装:process_request
--代理IP设定:process_exception: 记得return request
--拦截响应:
--篡改响应数据,响应对象
# 拦截请求:UA伪装,代理IP设置示例
class MiddlewareDownloaderMiddleware: user_agent_list = [ 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)', 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)', 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/5.0)', ] PROXY_http = [ '151.106.13.222:1080', '43.255.113.232:8083', '113.194.210.253:8085', ] PROXY_https = [ '47.95.117.151:22', '171.96.225.202:8080', '47.94.161.219:22', ] # 拦截请求 def process_request(self, request, spider): # UA伪装 request.headers['User_Agent'] = random.choice(self.user_agent_list) return None # 拦截响应 def process_response(self, request, response, spider): return response # 拦截发生异常的请求 def process_exception(self, request, exception, spider): # 一般是将代理ip处理放到process_exception中,因为正常请求的就不用代理ip,报错再换代理ip if request.url.split(':')[0] == 'http': # 代理 request.meta['proxy'] = 'http://' + random.choice(self.PROXY_http) else: request.meta['proxy'] = 'https://' + random.choice(self.PROXY_https) return request # 将修正之后的请求对象进行重新的请求发送 def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
# 拦截响应,修改响应示例:
需求:爬取网易新闻中的新闻数据(标题和内容)
页面分析:
--网页新闻页面板块名称非动态加载,解析板块名称和板块url
--板块页面对应的页面是动态加载的,解析新闻标题和新闻详情页url
--板块页面的新闻详情页里的内容非动态加载,解析新闻内容
解析分析:
--板块名称为非动态加载,通过scrapy正常获取解析
--板块页面信息动态加载,通过 scrapy下载器中间件+selenium 结合进行解析
--新闻详情页非动态加载,通过scrapy正常获取解析
selenium在scrapy中的使用流程:
--1.在爬虫类中实例化一个浏览器对象,将其作为爬虫类的一个属性
--2.在中间件中实现浏览器自动化相关的操作
--3.在爬虫类中重写closed(self,spider),在其内部关闭浏览器对象
# 爬虫文件news.py
import scrapy from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options from wangyinews.items import WangyinewsItem class NewsSpider(scrapy.Spider): name = 'news' # allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] t_url_list = [] # 存储板块的url # 要用到selenium,而且整个抓取过程,只要有一个浏览器就可以,因此用init方式实例化一个浏览器对象 def __init__(self): self.service = Service('D:\pythonworks\spider\wangyinews\wangyinews\spiders\chromedriver.exe') self.options = webdriver.ChromeOptions() self.options.add_experimental_option('excludeSwitches', ['enable-logging']) self.bro = webdriver.Chrome(service=self.service,options=self.options) # 解析news页面上板块的名称和url def parse(self, response): li_list = response.xpath('//*[@id="index2016_wrap"]/div[2]/div[2]/div[2]/div[2]/div//li') list_num = [2] for index in list_num: t_name = li_list[index].xpath('./a/text()')[0].extract() t_url = li_list[index].xpath('./a/@href')[0].extract() self.t_url_list.append(t_url) # 依次对每一个板块对应的页面进行请求 for t_url in self.t_url_list: yield scrapy.Request(url=t_url, callback=self.parse_t) # 解析每一个板块页面中新闻的标题和新闻详情页的url # 板块页面的新闻是动态加载出来的,所以直接解析是解析不出来的,通过中间件结合selenium进行操作 def parse_t(self, response): div_list = response.xpath('//div[@class="ndi_main"]/div') for div in div_list: news_title = div.xpath('.//h3[1]/a/text()').extract_first() news_detail_url = div.xpath('.//h3[1]/a/@href').extract_first() # 请求传参准备 item = WangyinewsItem() item['news_title'] = news_title item['news_detail_url'] = news_detail_url # 对新闻详情页的url发起请求,及请求传参 yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item}) # 解析新闻详情页 def parse_detail(self,response): content = response.xpath('//*[@id="content"]/div[2]//text()').extract() content = ''.join(content) item = response.meta item['content'] = content yield item # 爬虫结束后关闭浏览器(重写了一个closed函数) def closed(self,spider): self.bro.quit()
# middlewares.py
from scrapy import signals from itemadapter import is_item, ItemAdapter from scrapy.http import HtmlResponse from time import sleep class WangyinewsDownloaderMiddleware: def process_request(self, request, spider): return None # 拦截板块对应的响应对象,进行篡改 def process_response(self, request, response, spider): # 获取在爬虫类中定义的浏览器对象 bro = spider.bro # 挑选出指定的响应对象进行修改,如果指定? # 通过url指定request,通过request确定response,一个request对应着一个response if request.url in spider.t_url_list: # 用selenium的bro浏览器对象发送请求获取包含动态数据的页面数据 bro.get(request.url) sleep(2) page_text = bro.page_source # 包含了动态加载的数据 # 针对定位到的板块response,篡改过程在这里 # 实例化一个新的响应对象(要包含动态加载的新闻数据),替代原来的response # HtmlResponse是scrapy内置的一个response构造函数,能够构建符合scrapy标准的response对象,包含四个参数 # 如何获取动态加载的数据? selenium new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request) return new_response else: return response def process_exception(self, request, exception, spider): pass def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
注:在中间件中可以结合各种第三方模块来进行使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号