爬虫案例--梨视频下载地址抓取(使用普通模块)
本案例为学习研究,不可做非法用途使用!
本案例使用的是普通的lxml,requests模块结合抓包工具做的抓取.
后续有selenium能够更好的满足需求
案例需求:
获取梨视频生活页面的热点视频数据,提取对应视频的真实下载地址.
页面分析:
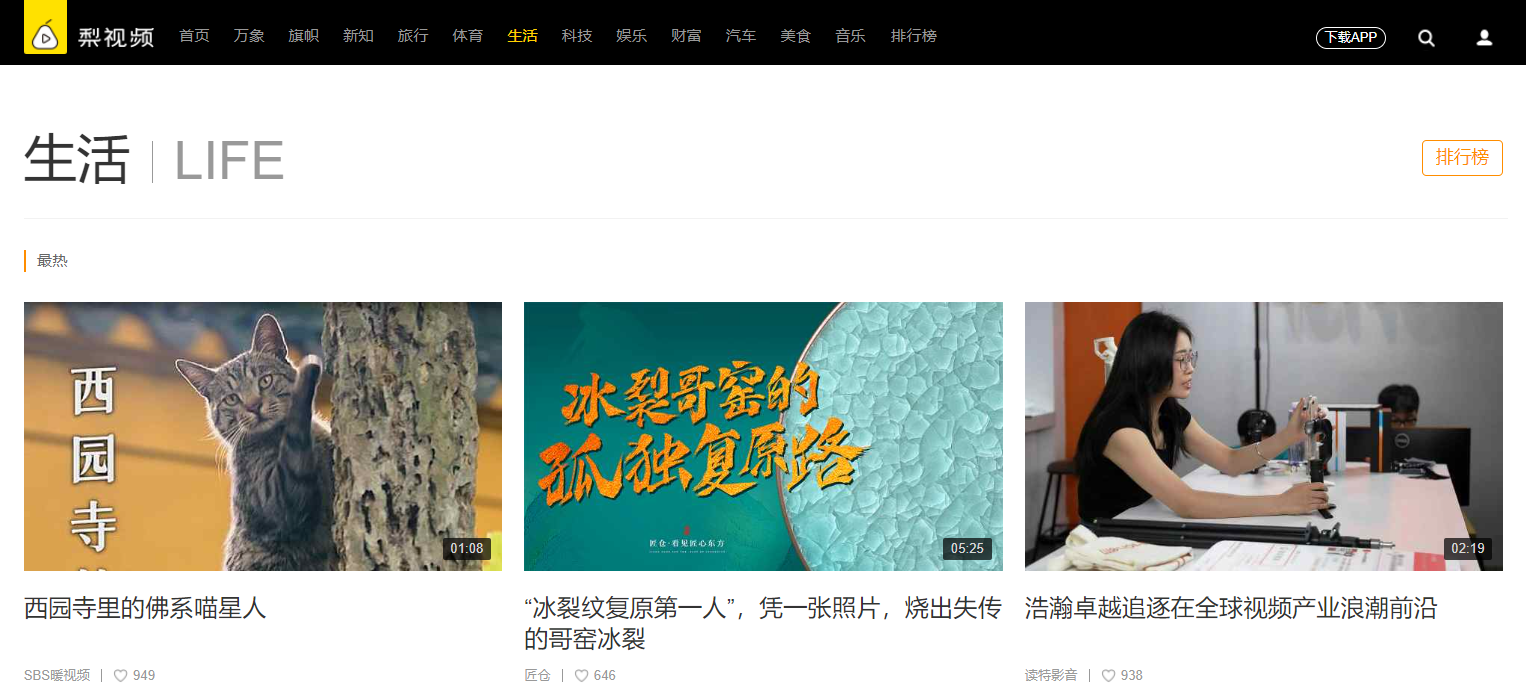
直接打开开发者工具,查看页面源码,分析出页面get请求可以直接获取,我们所需要的视频列表数据可以直接使用xpath进行获取
获取视频标题,视频详情页地址:
import requests from lxml import etree import random import re from multiprocessing.dummy import Pool if __name__ == '__main__': headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome... } # 对url发起请求解析出视频详情页URL和视频的名称 url = 'https://www.pearvideo.com/category_5' page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) li_list = tree.xpath('//div[@class="category-top"]//li') for li in li_list: detail_url = 'https://www.pearvideo.com/' + li.xpath('.//div[@class="vervideo-bd"]/a/@href')[0]
根据详情页的地址,分析详情页面中视频真实下载地址:
详情页能够直接播放视频,但是视频并不在源码中,而在开发者工具中能够搜索到mp4,
也就是页面源码和开发者工具中渲染结果后的页面不一致,说明视频是经过二次渲染的.

上述的渲染后的mp4地址在浏览器可以打开,也可以下载,说明这是视频的真实地址,下面就是如何不经过浏览器,而用代码获取到这个地址
尝试用xpath获取<video>标签中的src属性来获得该视频地址,代码如下:
detail_page_text = requests.get(url=detail_url,headers=headers).text # 从详情页解析出视频的地址(url) video_tree = etree.HTML(detail_page_text) video_url = video_tree.xpath('//video/@src') print(video_url) # 打印结果为空列表,没有获取到相应的mp4地址
在requests函数get到的html代码中没有得到mp4地址,说明视频地址的获取是经过了二次数据提交后获得的
因此猜测可能是使用了ajax进行了数据传递,打开浏览器抓包工具Fetch/XHR进行分析
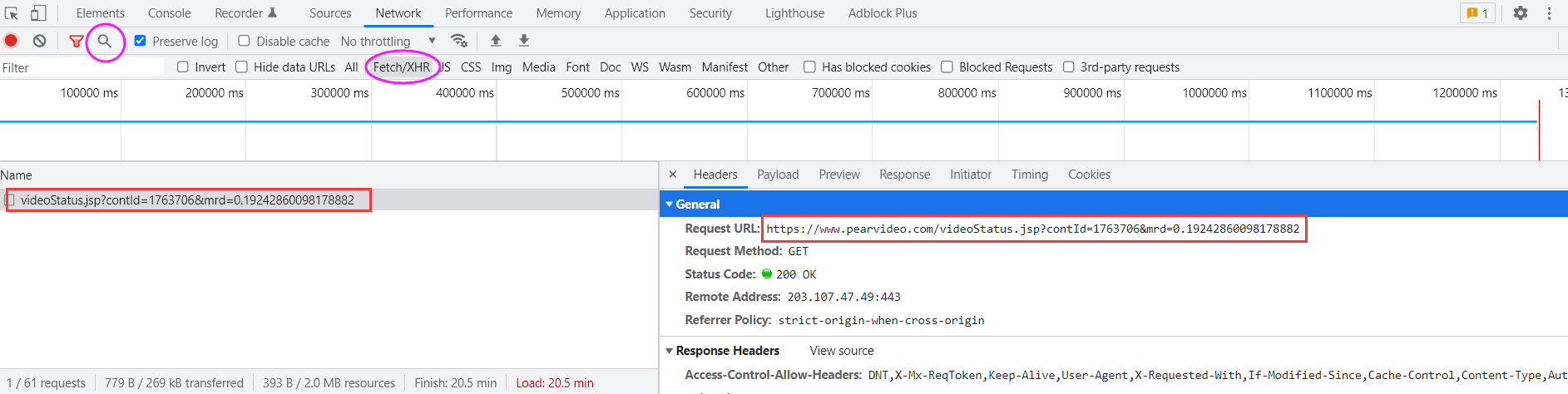
注:可以直接在搜索标志中全局搜mp4看看哪里有mp4相关数据.
经过抓包工具发现有一个ajax数据的请求,请求地址:videostatus.jsp,同时还有参数
同时在response中发现了mp4的地址痕迹

上述地址和浏览器中得到的真实mp4地址进行比较:

发现仅仅只有部分数字不一致,其他的都一致,因此大概率这个我们通过代码可以获取的地址和真实地址是有着很大的关联的.
再仔细分析发现,其实只需要将'cont-页面的id'和上述的第一段数字替换即可以获得真实的视频地址,这段数字就是response数据中的systemtime数据
用代码获取解析地址:
for li in li_list: detail_url = 'https://www.pearvideo.com/' + li.xpath('.//div[@class="vervideo-bd"]/a/@href')[0] video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0] # 获取id contId = detail_url.split('_')[1] request_detail_url = "https://www.pearvideo.com/videoStatus.jsp" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36", "Referer": f"https://www.pearvideo.com/video_{contId}" # 防爬措施反制 } # ajax发送请求时传递了两个参数contId和mrd # mrd参数参考网上的定义,直接用random函数生成 params = { 'contId': contId, 'mrd': str(random.random()) } # 网页返回的是一个json格式的数据,这里直接进行json格式化为字典对象 data = requests.get(request_detail_url, params=params,headers=headers).json() # 获取需要被替换的systemTime数字 systemTime = data['systemTime'] srcUrl = data['videoInfo']['videos']['srcUrl'] # 进行替换 srcUrl = srcUrl.replace(systemTime, f"cont-{contId}") video_dic = { 'video_name' : video_name, 'video_url' : srcUrl } video_urls.append(video_dic)
运用多线程池的视频解析及下载的完整代码:
import requests from lxml import etree import random import re from multiprocessing.dummy import Pool # 需求:爬取梨视频的视频数据 if __name__ == '__main__': headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36' } # 对url发起请求解析出视频详情页URL和视频的名称 url = 'https://www.pearvideo.com/category_5' page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) li_list = tree.xpath('//div[@class="category-top"]//li') video_urls = [] for li in li_list: detail_url = 'https://www.pearvideo.com/' + li.xpath('.//div[@class="vervideo-bd"]/a/@href')[0] video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0] # 获取id contId = detail_url.split('_')[1] request_detail_url = "https://www.pearvideo.com/videoStatus.jsp" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36", "Referer": f"https://www.pearvideo.com/video_{contId}" # 防爬措施反制 } # ajax发送请求时传递了两个参数contId和mrd # mrd参数参考网上的定义,直接用random函数生成 params = { 'contId': contId, 'mrd': str(random.random()) } # 网页返回的是一个json格式的数据,这里直接进行json格式化为字典对象 data = requests.get(request_detail_url, params=params,headers=headers).json() # 获取需要被替换的systemTime数字 systemTime = data['systemTime'] srcUrl = data['videoInfo']['videos']['srcUrl'] # 进行替换 srcUrl = srcUrl.replace(systemTime, f"cont-{contId}") video_dic = { 'video_name' : video_name, 'video_url' : srcUrl } video_urls.append(video_dic) # 视频下载函数 def get_video(video_dic): video_name = video_dic['video_name'] video_url = video_dic['video_url'] with open(f'{video_name}.mp4', mode="wb") as f: f.write(requests.get(video_url).content) # 实例化线程 pool = Pool(4) pool.map(get_video, video_urls) pool.close() pool.join()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号