Eureka的自我保护机制
最近项目在Kubernetes上使用Eureka遇到一些问题,在网站上找到一篇针对Eureka自我保护机制原理的文章,觉得不错,总结如下:
Eureka的自我保护特性主要用于减少在网络分区或者不稳定状况下的不一致性问题
- Eureka自我保护的产生原因:
Eureka在运行期间会统计心跳失败的比例,在15分钟内是否低于85%,如果出现了低于的情况,Eureka Server会将当前的实例注册信息保护起来,同时提示一个警告,一旦进入保护模式,Eureka Server将会尝试保护其服务注册表中的信息,不再删除服务注册表中的数据。也就是不会注销任何微服务。
- Kubernetes环境
但在Kubernetes环境下,如果某个节点的Kubelet下线,比较容易造成自我保护。阶段如下:
-
- Kubelet下线,会造成大量的服务处于Unknow状态, Kubernetes为了维持Deployment指定的Pod数量,会在其他节点上启动服务,注册到Eureka,这个时候是不会触发自我保护的。
- 重新启动Kubelet进行让节点Ready,这时候Kubernetes发现Pod数量超过了设计值,然后Terminate原来Unknown的Pod,这个时候就会出现大量的服务下线状态,从而触发自我保护
- 而处于自我保护状态的Eureka不再同步服务的信息,同时也不再和另一个实例保持同步。
这个是个比较核心的问题,如果这样的话,只能够手工删除Eureka实例让他重建,恢复正常状况。
所以在Kubernetes环境下,关闭服务保护,让Eureka和服务保持同步状态。
目前的解决办法
- Eureka Server端:配置关闭自我保护,并按需配置Eureka Server清理无效节点的时间间隔。
eureka.server.enable-self-preservation# 设为false,关闭自我保护 eureka.server.eviction-interval-timer-in-ms # 清理间隔(单位毫秒,默认是60*1000)
- Eureka Client端:配置开启健康检查,并按需配置续约更新时间和到期时间
eureka.client.healthcheck.enabled# 开启健康检查(需要spring-boot-starter-actuator依赖) eureka.instance.lease-renewal-interval-in-seconds# 续约更新时间间隔(默认30秒) eureka.instance.lease-expiration-duration-in-seconds # 续约到期时间(默认90秒)
原文如下, 我把结论翻译一下
- 我在自我保护方面的经验是,在大多数情况下,它错误地假设一些弱微服务实例是一个糟糕的网络分区。
- 自我保护永不过期,直到并且除非关闭微服务(或解决网络故障)。
- 如果启用了自我保留,我们无法微调实例心跳间隔,因为自我保护假定心跳以30秒的间隔接收。
- 除非这些网络故障在您的环境中很常见,否则我建议将其关闭(即使大多数人建议将其保留)。
Eureka is an AP system in terms of CAP theorem which in turn makes the information in the registry inconsistent between servers during a network partition. The self-preservation feature is an effort to minimize this inconsistency.
-
Defining self-preservation
Self-preservation is a feature where Eureka servers stop expiring instances from the registry when they do not receive heartbeats (from peers and client microservices) beyond a certain threshold.
Let’s try to understand this concept in detail.
-
Starting with a healthy system
Consider the following healthy system.
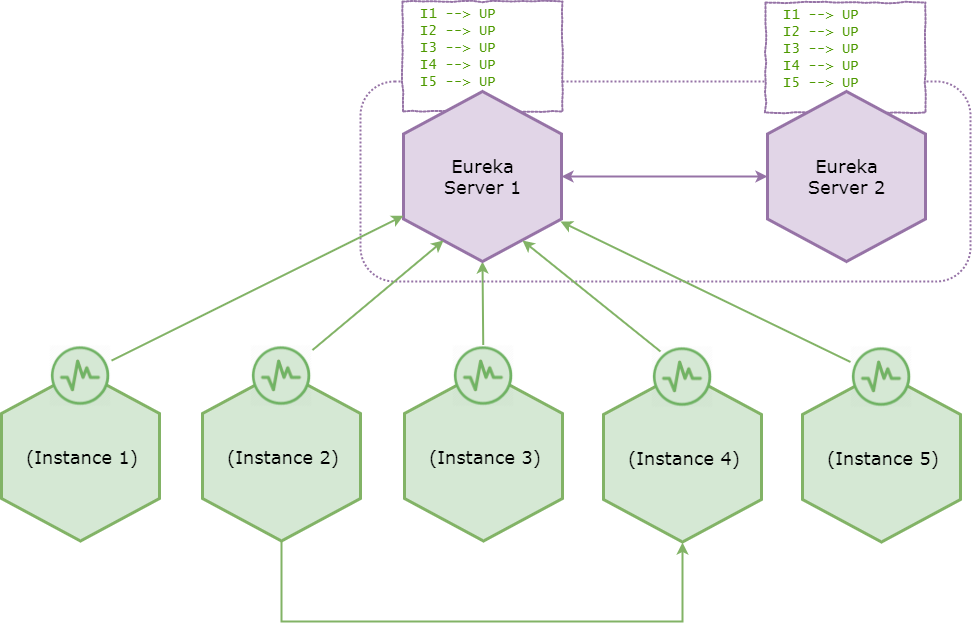
The healthy system — before encountering network partition
Suppose that all the microservices are in healthy state and registered with Eureka server. In case if you are wondering why — that’s because Eureka instances register with and send heartbeats only to the very first server configured in service-url list. i.e.
eureka.client.service-url.defaultZone=server1,server2
Eureka servers replicate the registry information with adjacent peers and the registry indicates that all the microservice instances are in UP state. Also suppose that instance 2 used to invoke instance 4 after discovering it from a Eureka registry.
-
Encountering a network partition
Assume a network partition happens and the system is transitioned to following state.
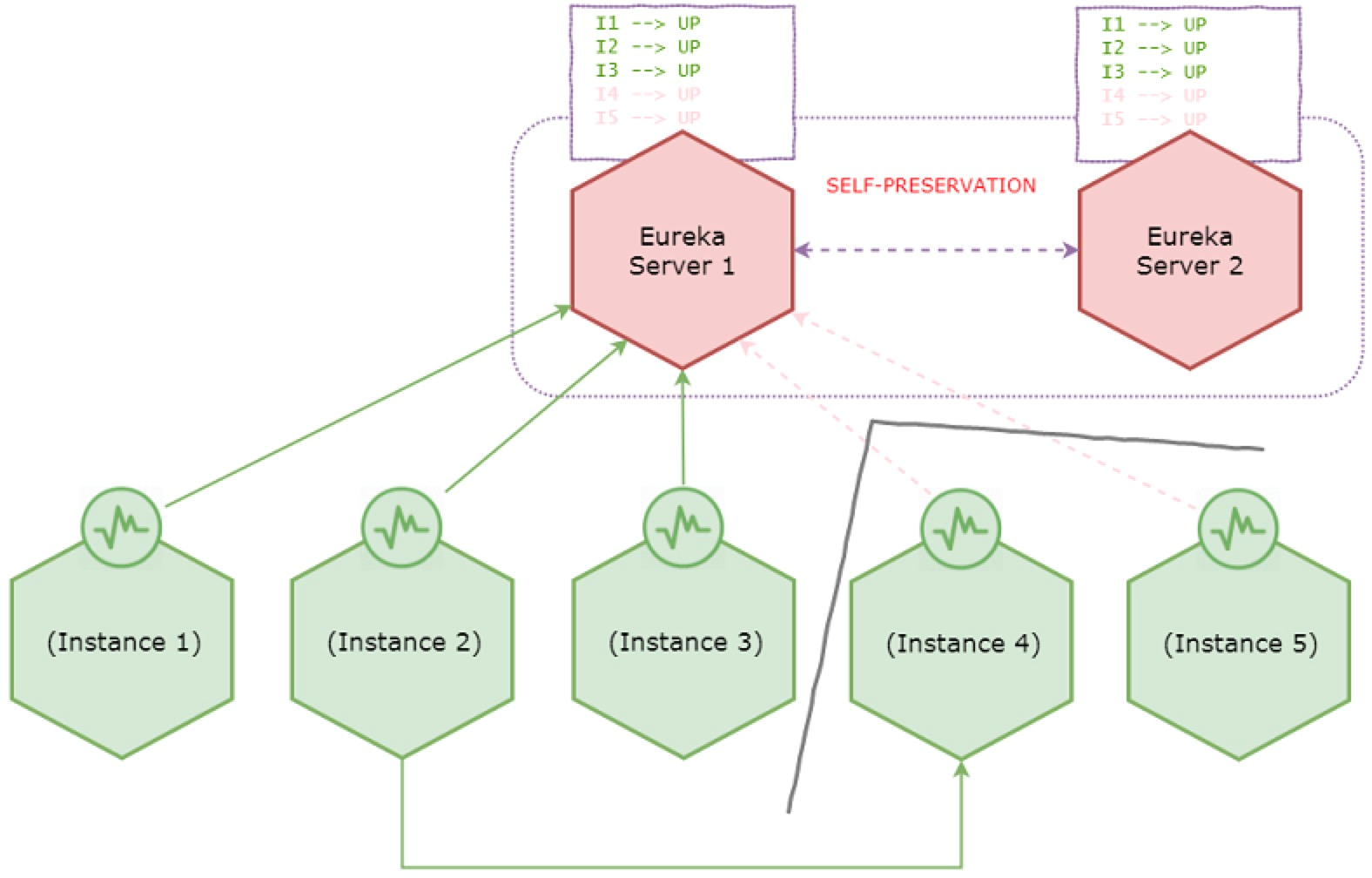
During network partition - enters self-preservation
Due to the network partition instance 4 and 5 lost connectivity with the servers, however instance 2 is still having connectivity to instance 4. Eureka server then evicts instance 4 and 5 from the registry since it’s no longer receiving heartbeats. Then it will start observing that it suddenly lost more than 15% of the heartbeats, so it enters self-preservation mode.
From now onward Eureka server stops expiring instances in the registry even if remaining instances go down.
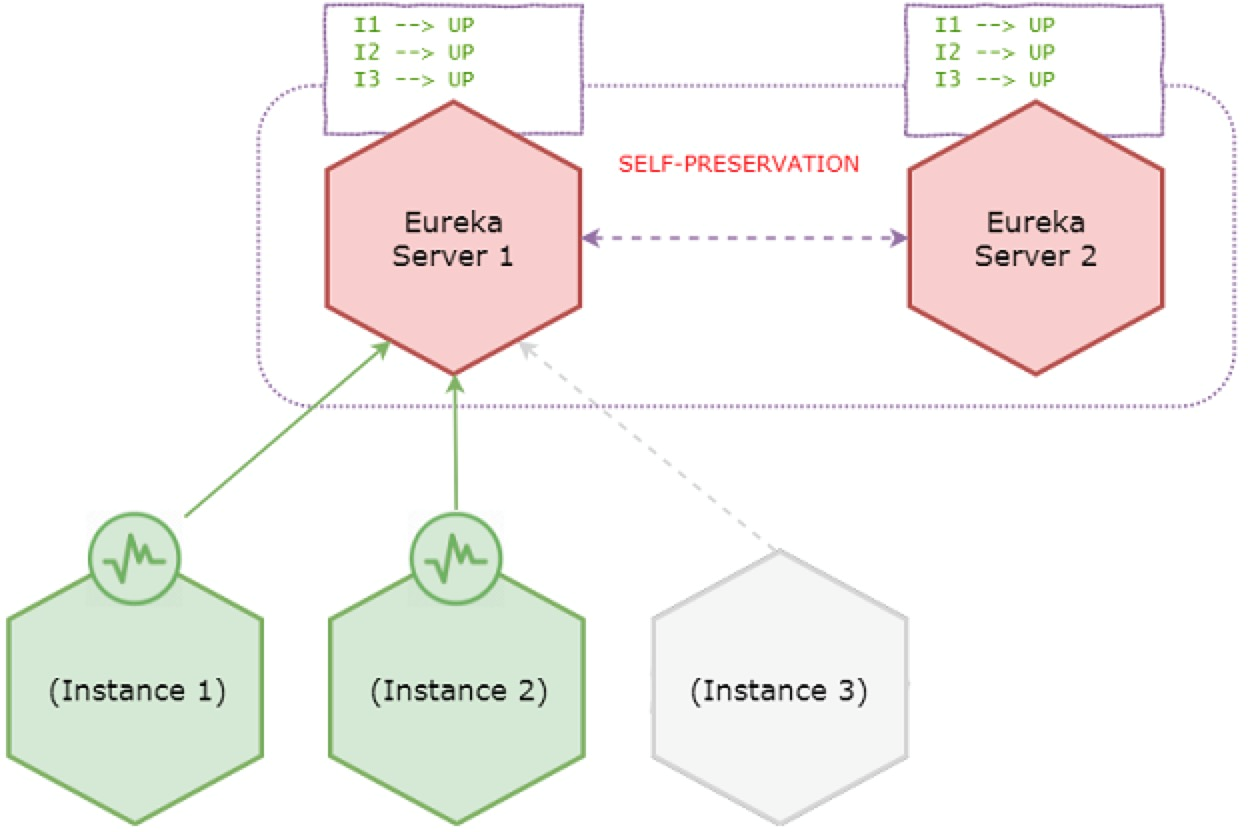
During self-preservation - stops expiring instances
Instance 3 has gone down, but it remains active in the server registry. However servers accept new registrations.
-
The rationale behind self-prservation
Self-preservation feature can be justified for following two reasons.
-
Servers not receiving heartbeats could be due to a poor network partition (i.e. does not necessarily mean the clients are down) which could be resolved sooner.
-
Even though the connectivity is lost between servers and some clients, clients might have connectivity with each other. i.e. Instance 2 is having connectivity to instance 4 as in the above diagram during the network partition.
-
Configurations (with defaults)
Listed below are the configurations that can directly or indirectly impact self-preservation behavior.
eureka.instance.lease-renewal-interval-in-seconds = 30
Indicates the frequency the client sends heartbeats to server to indicate that it is still alive. It’s not advisable to change this value since self-preservation assumes that heartbeats are always received at intervals of 30 seconds.
eureka.instance.lease-expiration-duration-in-seconds = 90
Indicates the duration the server waits since it received the last heartbeat before it can evict an instance from its registry. This value should be greater than lease-renewal-interval-in-seconds. Setting this value too long impacts the precision of actual heartbeats per minute calculation described in the next section, since the liveliness of the registry is dependent on this value. Setting this value too small could make the system intolerable to temporary network glitches.
eureka.server.eviction-interval-timer-in-ms = 60 * 1000
A scheduler is run at this frequency which will evict instances from the registry if the lease of the instances are expired as configured by lease-expiration-duration-in-seconds. Setting this value too long will delay the system entering into self-preservation mode.
eureka.server.renewal-percent-threshold = 0.85
This value is used to calculate the expected heartbeats per minute as described in the next section.
eureka.server.renewal-threshold-update-interval-ms = 15 * 60 * 1000
A scheduler is run at this frequency which calculates the expected heartbeats per minute as described in the next section.
eureka.server.enable-self-preservation = true
Last but not least, self-preservation can be disabled if required.
Making sense of configurations
Eureka server enters self-preservation mode if the actual number of heartbeats in last minute is less than the expected number of heartbeats per minute.
Expected number of heartbeats per minute
We can see the means of calculating expected number of heartbeats per minute threshold. Netflix code assumes that heartbeats are always received at intervals of 30 seconds for this calculation.
Suppose the number of registered application instances at some point in time is N and the configured renewal-percent-threshold is 0.85.
-
Number of heartbeats expected from one instance / min = 2
-
Number of heartbeats expected from N instances / min = 2 * N
-
Expected minimum heartbeats / min = 2 * N * 0.85
Since N is a variable, 2 * N * 0.85 is calculated in every 15 minutes by default (or based on renewal-threshold-update-interval-ms).
Actual number of heartbeats in last minute
This is calculated by a scheduler which runs in a frequency of one minute.
Also as describe above, two schedulers run independently in order to calculate actual and expected number of heartbeats. However it’s another scheduler which compares these two values and identifies whether the system is in self-preservation mode — which is EvictionTask. This scheduler runs in a frequency of eviction-interval-timer-in-ms and evicts expired instances, however it checks whether the system has reached self-preservation mode (by comparing actual and expected heartbeats) before evicting.
The eureka dashboard also does this comparison every time when you launch it in order to display the message ‘…INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE’.
-
Conclusion
-
My experience with self-preservation is that it’s a false-positive most of the time where it incorrectly assumes a few down microservice instances to be a poor network partition.
-
Self-preservation never expires, until and unless the down microservices are brought back (or the network glitch is resolved).
-
If self-preservation is enabled, we cannot fine-tune the instance heartbeat interval, since self-preservation assumes heartbeats are received at intervals of 30 seconds.
-
Unless these kinds of network glitches are common in your environment, I would suggest to turn it off (even though most people recommend to keep it on).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号