
大数据的开始:安装hadoop
为实现全栈,从今天开始研究Hadoop,个人体会是成为某方面的专家需要从三个方面着手
- 系统化的知识(需要看书或者比较系统的培训)
- 碎片化的知识(需要根据关注点具体的深入的了解)
- 经验的积累(需要遇到问题)
好吧,我们从安装入手。
1.找三个CentOS的虚拟环境,我的是centos 7,大概的规划如下,一个master,两个slave
修改三台机器的/etc/hosts文件
192.168.0.104 master 192.168.0.105 slave1 192.168.0.106 slave2
2.配置ssh互信
在三台机器上输入下面的命令,生成ssh key以及authorized key,为了简单,我是在root用户下操作,大家可以在需要启动hadoop的用户下操作更规范一些
ssh-keygen -t rsa
cd .ssh
cp id_rsa.pub authorized_keys
然后将三台机器的authorized_keys合并成一个文件并且复制在三台机器上。比如我的authorized key
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCrtxZC5VB1tyjU4nGy4+Yd//LsT3Zs2gtNtpw6z4bv7VdL6BI0tzFLs8QIHS0Q82BmiXdBIG2fkLZUHZuaAJlkE+GCPHBmQSdlS+ZvUWKFr+vpbzF86RBGwJp1HHs7GtDFtirN3Z/Qh6pKgNLFuFCxIF/Ee4sL50RUAh6wFOY/TRU4XxQissNXd9rhVFrZnOkctfA3Wek4FgNRyT+xUezSW1Vl2GliGc0siI5RCQezDhKwZNHyzY4yyiifeQYL14S4D0RrlCvv+5PIUZUrKznKc1BMYIljxMVOrAs0DsvQ0fkna/Q/pA53cuPhkD4P8ehA/fJuMCTZ+1q/Z2o1WW4j root@master ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDBmuwzWdWI1oEwA8BC2RutAWWeCvFkkH7qYR4pWyMK8Ubkpc5HxB+mqCr24Bgug17bvFdrTdUyABY7GSJpGx3xBIcyh96bBgG9Thnc0k/XT6oO3cTai0jDr74CCTkkXymBwpVkAIlYY/MrdxQAym4gOMnU2celMMpkq7GhFJ7zOZqfI3cdQ6Q9x9LyNP6DcDFp7QQePcGylNpHeZITgABZzozWFyqg1nHi9qfGy3NtXM2lnGF+W+6JR/OtShTWeaxAOwQXt0rDEjHyUZ8JAv95J4sawGrwgWX89oWr4xorR8rMYl0FZz84OtvvNSFm5KR2NRxj8yPZZQKjaJ8nuDGN root@slave1 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDCrRbwk8Xc2EHLNRL25ve3IlLLkshByTXwwWslP61ASNeKhYk2HObGAjL09mOpOmzdbVXJJ6YLDWIKczLSnSt4o5W7bjWQpCh136O9vCupibxCr1q4uJa+qpW69mUhrvREa4hOLvRXCXmz16p0/dOtCnPudF8AgzhezrqI/4yQkLubGZamQauHB8LEd+1VMdjRHWx0j6mQHrcDnqlaIEq8XW4UM2TcmSS7Ztp6q0zzcC39dz/xopwq/WixwQi2z4Ywc++YufXHmyDp/gkqyXG1tHwH9TMQ/kkmD3piEcnrFKDlU8Kk/B1YCnNIKTG5BT9k1JI1qenJ8NxHJ06gtM3J root@slave2
3.安装JDK,我们用jdk-7u79-linux-x64.gz版本。
tar xzvf jdk-7u79-linux-x64.gz
修改.bashrc
JAVA_HOME=/hadoop/jdk1.7.0_79 CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar PATH=$JAVA_HOME/bin:$PATH export JAVA_HOME CLASSPATH PATH
4.安装hadoop并配置
在下面链接下载2.8.1版本,然后解压
http://hadoop.apache.org/releases.html
我把jdk和hadoop都放在/hadoop目录下,然后建立目录
mkdir tmp mkdir -p hdfs/data mkdir -p hdfs/name
然后修改核心的几个配置文件。/hadoop/hadoop-2.8.1/etc/hadoop
core-site.xml
[root@master hadoop]# cat core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.0.104:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/hadoop/tmp</value> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> </configuration>
hdfs-site.xml
[root@master hadoop]# cat hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.0.104:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
mapred-site.xml
[root@slave1 hadoop]# cat mapred-site.xml <configuration> <property> <name>mapred.job.tracker</name> <value>master:49001</value> </property> <property> <name>mapred.local.dir</name> <value>/hadoop/var</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
yarn-site.xml
[root@slave1 hadoop]# cat yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <description>The address of the applications manager interface in the RM.</description> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <description>The address of the scheduler interface.</description> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <description>The http address of the RM web application.</description> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> <property> <description>The https adddress of the RM web application.</description> <name>yarn.resourcemanager.webapp.https.address</name> <value>${yarn.resourcemanager.hostname}:8090</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property> <property> <description>The address of the RM admin interface.</description> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
配置hadoop-env.sh、yarn-env.sh中JAVA_HOME
配置slave节点
[root@master hadoop]# cat slaves 192.168.0.105 192.168.0.106
将master节点的软件复制到slave上。
scp -r /hadoop 192.168.0.105:/ scp -r /hadoop 192.168.0.106:/
5.格式化
在master节点上进入/hadoop/hadoop-2.8.1/bin目录运行,格式化hdfs系统
./hdfs namenode -format
6.启动,停止
需要在三台机器上关闭防火墙
service firewalld stop
chkconfig firewalld off
全部启动sbin/start-all.sh,也可以分开sbin/start-dfs.sh、sbin/start-yarn.sh
[root@master sbin]# ./start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [master] master: starting namenode, logging to /hadoop/hadoop-2.8.1/logs/hadoop-root-namenode-master.out 192.168.0.106: starting datanode, logging to /hadoop/hadoop-2.8.1/logs/hadoop-root-datanode-slave2.out 192.168.0.105: starting datanode, logging to /hadoop/hadoop-2.8.1/logs/hadoop-root-datanode-slave1.out Starting secondary namenodes [master] master: starting secondarynamenode, logging to /hadoop/hadoop-2.8.1/logs/hadoop-root-secondarynamenode-master.out starting yarn daemons starting resourcemanager, logging to /hadoop/hadoop-2.8.1/logs/yarn-root-resourcemanager-master.out 192.168.0.105: starting nodemanager, logging to /hadoop/hadoop-2.8.1/logs/yarn-root-nodemanager-slave1.out 192.168.0.106: starting nodemanager, logging to /hadoop/hadoop-2.8.1/logs/yarn-root-nodemanager-slave2.out
停止的话,输入命令,sbin/stop-all.sh
输入命令,jps,可以看到相关信息
master上
[root@master bin]# jps 4018 NameNode 4223 SecondaryNameNode 4383 ResourceManager 4686 Jps
slave上
[root@slave2 ~]# jps 3592 NodeManager 3510 DataNode 7173 Jps
运行验证/bin/hadoop dfsadmin -report
[root@master bin]# ./hadoop dfsadmin -report DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Configured Capacity: 79401328640 (73.95 GB) Present Capacity: 63387807744 (59.03 GB) DFS Remaining: 63387783168 (59.03 GB) DFS Used: 24576 (24 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (2): Name: 192.168.0.105:50010 (slave1) Hostname: slave1 Decommission Status : Normal Configured Capacity: 39700664320 (36.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 8011935744 (7.46 GB) DFS Remaining: 31688716288 (29.51 GB) DFS Used%: 0.00% DFS Remaining%: 79.82% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Aug 10 18:41:48 CST 2017 Name: 192.168.0.106:50010 (slave2) Hostname: slave2 Decommission Status : Normal Configured Capacity: 39700664320 (36.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 8001585152 (7.45 GB) DFS Remaining: 31699066880 (29.52 GB) DFS Used%: 0.00% DFS Remaining%: 79.85% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Aug 10 18:41:48 CST 2017
7.访问
要先开放端口或者直接关闭防火墙
(1)输入命令,systemctl stop firewalld.service
(2)浏览器打开http://192.168.0.104:8088/
(3)浏览器打开http://192.168.0.104:50070/
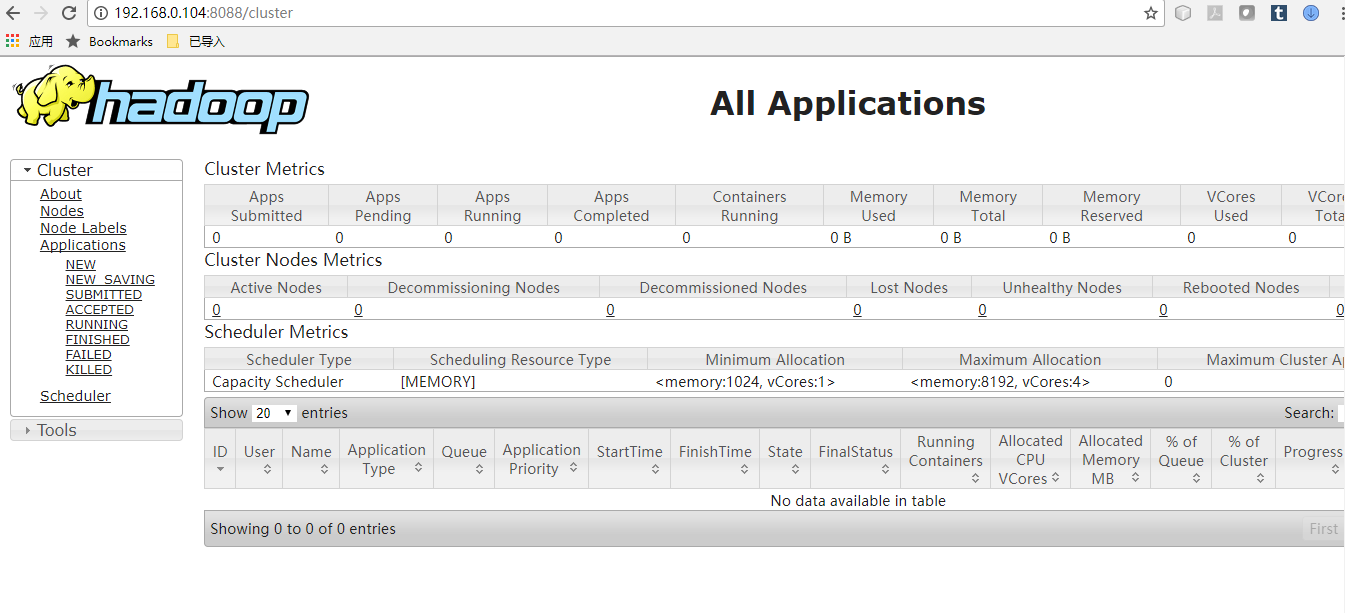
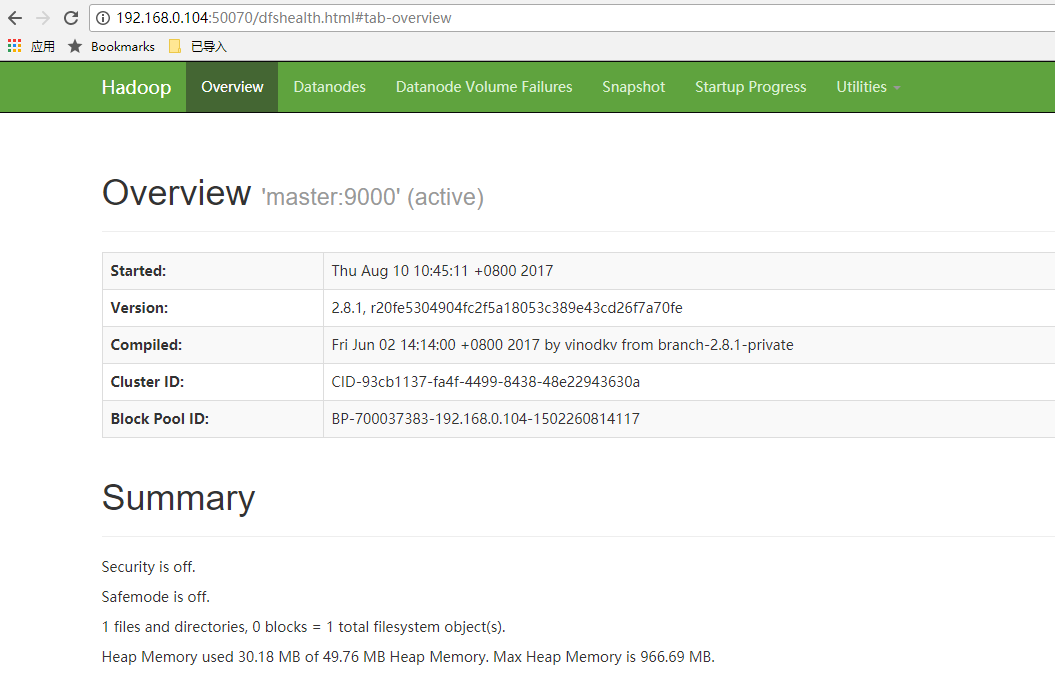
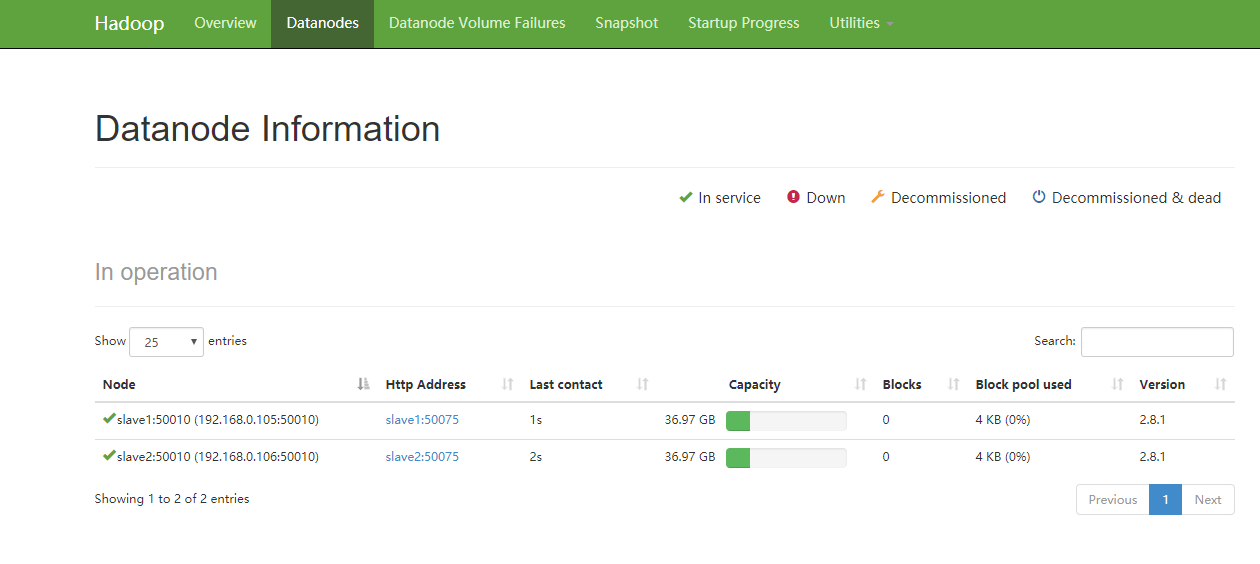
8. 放入文件,并且浏览
[root@master bin]# ./hadoop dfs -put /hadoop/input /input DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. [root@master bin]# ./hadoop dfs -ls /input DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Found 2 items -rw-r--r-- 2 root supergroup 12 2017-08-10 18:48 /input/test1.txt -rw-r--r-- 2 root supergroup 13 2017-08-10 18:48 /input/test2.txt
运行wordcount
[root@master bin]# ./hadoop jar /hadoop/hadoop-2.8.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /input /output 17/08/12 21:20:09 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.0.104:8032 17/08/12 21:20:10 INFO input.FileInputFormat: Total input files to process : 2 17/08/12 21:20:10 INFO mapreduce.JobSubmitter: number of splits:2 17/08/12 21:20:11 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1502543903142_0002 17/08/12 21:20:11 INFO impl.YarnClientImpl: Submitted application application_1502543903142_0002 17/08/12 21:20:12 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1502543903142_0002/ 17/08/12 21:20:12 INFO mapreduce.Job: Running job: job_1502543903142_0002 17/08/12 21:20:25 INFO mapreduce.Job: Job job_1502543903142_0002 running in uber mode : false 17/08/12 21:20:25 INFO mapreduce.Job: map 0% reduce 0% 17/08/12 21:20:42 INFO mapreduce.Job: map 50% reduce 0% 17/08/12 21:20:44 INFO mapreduce.Job: map 100% reduce 0% 17/08/12 21:20:52 INFO mapreduce.Job: map 100% reduce 100% 17/08/12 21:20:52 INFO mapreduce.Job: Job job_1502543903142_0002 completed successfully 17/08/12 21:20:53 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=55 FILE: Number of bytes written=409069 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=237 HDFS: Number of bytes written=25 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=31403 Total time spent by all reduces in occupied slots (ms)=6730 Total time spent by all map tasks (ms)=31403 Total time spent by all reduce tasks (ms)=6730 Total vcore-milliseconds taken by all map tasks=31403 Total vcore-milliseconds taken by all reduce tasks=6730 Total megabyte-milliseconds taken by all map tasks=32156672 Total megabyte-milliseconds taken by all reduce tasks=6891520 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=41 Map output materialized bytes=61 Input split bytes=212 Combine input records=4 Combine output records=4 Reduce input groups=3 Reduce shuffle bytes=61 Reduce input records=4 Reduce output records=3 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=681 CPU time spent (ms)=1720 Physical memory (bytes) snapshot=510668800 Virtual memory (bytes) snapshot=2578022400 Total committed heap usage (bytes)=257564672 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=25 File Output Format Counters Bytes Written=25
查看结果
[root@master bin]# ./hadoop dfs -ls /output DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Found 2 items -rw-r--r-- 2 root supergroup 0 2017-08-12 21:20 /output/_SUCCESS -rw-r--r-- 2 root supergroup 25 2017-08-12 21:20 /output/part-r-00000 [root@master bin]# ./hadoop dfs -cat /output/part-r-00000 DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. hadoop 1 hello 2 world 1
问题和定位
1.启动后发现slave的nodemanager全部没有启动起来,但看log信息又没有什么问题,修改yarn-site.xml文件后解决。
2.运行wordcount的时候报错说memory问题,调整了yarn-site.xml中的yarn.scheduler.maximum-allocation-mb,yarn.nodemanager.resource.memory-mb后解决
3.name node in safe mode,主要引起的原因是作业在运行过程中用了ctrl-c来进行退出,解决办法是:
[root@master bin]# ./hadoop dfsadmin -safemode leave DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Safe mode is OFF

 浙公网安备 33010602011771号
浙公网安备 33010602011771号