MySql基础知识
数据库是保存有组织数据的容器,DBMS是为管理数据库而设计的软件管理系统,MYSQL 等是数据库管理系统。MYSQL是一种数据库管理软件。
MYSQL命令
create database dbname -- 创建数据库 use dbname-- 选择数据库 drop database dbname -- 直接删除数据库 show database -- 显示可用数据库列表 show table -- 显示数据库中的表的列表 show full columns from tableName -- 与 DESCRIBE tableName 等效,显示表的字段信息 show grants -- 显示授予用户的安全权限 SHOW ERRORS -- 显示服务器错误 SHOW WARNINGS -- 显示警告信息
SQL
SQL(STRUCTURED QUERY LANGUAGE) 结构化查询语言,一种专门用于与数据库通信的语言,不是DBMS专有的语言,很多DBMS都支持SQL,但是某个DBMS支持的SQL语法不能完全适用于其他DBMS。
SQL语句不区分大小写,多条语句需要分号分隔,单条语句可以不用分号。
创建表
use dbname
create table 表名 ( id INT NOT NULL AUTO_INCREMENT, 字段2 VARCHAR(50) NOT NULL, 字段3 VARCHAR (50) NOT NULL DEFAULT 1, PRIMARY KEY(id) ) ENGINE =INNODB
检索列
select 字段1,字段2,... from 表名 where id=123 and ...
除非真的需要全部字段,否则建议不要使用用'*',这种操作是很耗性能的。
限制结果(用于分页查询)
select 字段1,... from 表名 limit 10 检索前10行 select 字段1,... from 表名 limit 11,20 检索11到20 select 字段1,... from 表名 limit 11,-1 检索11到最后一行
结果排序
select 字段1,... from 表名 order by 字段 asc -- asc 默认按照字段升序,此时可以不用orderby select 字段1,... from 表名 order by 字段 desc -- desc 按照字段降序 ,必须写 DESC select 字段1,... from 表名 where id=值 order by 字段 desc -- order by 放在where之后 select 字段1,... from 表名 where id=值 order by 字段a asc,字段b desc -- 按照字段a正序,如果字段a相同,则按照字段b倒叙
where筛选过滤
select * from 表名 where 字段2 <> '值' -- 不等于 和 != 效果相同 select * from 表名 where 数值字段 between 2 and 5 -- 检索2到5的记录,包括2和5 select * from 表名 where 字段2 is null -- 查找列无值的行,这里的无值不等于 值为0 和 空字符串 select * from 表名 where id in (1,2) -- 效果和or相似,但是据说一般or执行更快 select * from 表名 where id not in (1,2) -- 一般不建议这样使用 select * from 表名 where 字段a=10 or 字段b='lsk' and 字段c='avf123' -- 执行顺序是 字段a=10 or (字段b='lsk' and 字段c='avf123'),因为and的优先级高于or,添加括号的可增加可读性
过滤之通配符
select * from 表名 where 字段a like 'abc%' -- 匹配abc开头的字段a,无论其后多少字符,注意:like '%'是不匹配值为NULL的行,且匹配值区分大小写 select * from 表名 where 字段a like 'abc_', -- _仅仅匹配一个字符
除非必要,否则不建议使用 '%字符%'的形式进行匹配,非常好性能且查询效率非常慢。
过滤之正则表达式
select * from 表名 where 字段a regexp 'abc|XYZ' -- 等同于or select * from 表名 where 字段a regexp '[abc]|XYZ' -- 匹配包含'aXYZ'或者'bXYZ'或者'cXYZ' select * from 表名 where 字段a regexp '.abc' -- 正则表达式. 匹配任意一个字符,等同于like的_ select * from 表名 where 字段a regexp 'abc' -- 匹配包含abc的字段a,等同于like的双侧%
[^123]表示123除外
[1-9],[A-Z],用'-'表示范围
匹配特殊字符(比如'.'和'_')可以采用'\'转义,比如匹配有'.'的可以这样表示'\.'
文本处理函数
length(字符字段) -- 返回串长度 lower(字符字段) -- 将串转换为小写 upper(字符字段) -- 将串转换为大写 ltrim(字符字段) -- 去掉串左边的空格 rtrim(字符字段) -- 去掉串右边的空格
日期和时间处理函数
curdate() -- 当前日期 yyyy-MM-dd curtime() -- 当前时间 例10:52:10 NOW() -- yyyy-MM-dd hh-mm-ss DATE(须有值) -- 返回日期的日期部分 SELECT DATE(NOW()) yyyy-MM-dd DATE_FORMAT() -- 返回格式化的日期和时间串 HOUR() -- 返回一个时间的小时部分 MINUTE() -- 返回一个时间的分钟部分 MONTH() -- 返回一个日期的月份部分 SECOND() -- 返回一个时间的秒部分 TIME() -- 返回一个日期时间的时间部分 YEAR() -- 返回一个日期的年份部分
聚集函数
select avg(数值字段) as avgNumber from 表名 -- 求平均值 select count(*) from 表名 -- 记录数 select column(name) from 表名 -- 表里列有值的记录数,值为NULL不计 select sum(count) from 表名 -- 返回指定列的和,也可以 SUM(a*b) select max(score) from 表名 -- 查找最大值 select min(score) from 表名 -- 查找最小值
数据分组
select avg(score) from score group by classId -- 检索不同课的平均分 select avg(score) from score group by classId,depId, ... -- GROUP BY 后面可以多个字段,select的字段必须是group by 后面的字段或者是聚合函数 select count(*) from 表名 group by id having count(*)>10 -- 分组后,对分组再进行过滤,需要使用having。
注意:
如果分组列有NULL值的,将列值为NULL的分为一组;
GROUP BY 要在WHERE之后,ORDER BY 之前,也就是先过滤再分组再排序;
子查询
select * from 表A where id in (select a_Id from 表B where 表B字段1='值') select 字段1,(select field1 from 表2 where ...) as f1 from 表1 where 表1字段='值'
建议少用子查询,耗性能
主键
唯一标识自己的一列或一组列,唯一区别表中的一行,主键不能为空,任意两行的主键值必须不同
主键不是必须的,但是建议每个表中有一个主键,这样操作管理更方便,主键值最好不更新,以免数据对应不上
一个表的主键只能有一个
外键
一个表的主键指向另一个表的外键,比如说student表的主键studentId,在score表中也有,并且是score表的外键
外键保持了数据完整性和一致。,比如你在student表里面修改了studentId后,则score的studentId也会联动更新(前提是做好了外键值关联)。并且score表中插入的studentId必须是student表里有的
联表查询
select a.字段1,b.字段甲 from 表A as a,表B as b -- 两个表进行联结,进行的是笛卡尔积,结果的行数表A行数*表B的行数 select a.字段1,b.字段甲 from 表A as a,表B as b where a.id=b.A_Id -- 在上面的基础上,加上WHERE进行过滤 select a.字段1,b.字段甲 from 表A as a inner join 表B as b on a.id=b.A_Id -- 内部联结 外部联结:left outer join 和 right outer join ,LEFT JOIN 保证了保证左边表的所有行,右联结同理 full join效果等同于 left outer join + right outer join ,即左表不匹配的右表不匹配的都会列出
UNION与UNION ALL
[SQL 语句 1] UNION [SQL 语句 2]
[SQL 语句 1] UNION ALL [SQL 语句 2]
UNION去重且排序
UNION ALL不去重不排序
使用时,必须确保搜出的结果集字段数量、类型、名称一致。
插入数据
INSERT INTO 表名 VALUES ('值1','值2') -- 必须值的个数和顺序必须和字段的个数顺序一致 INSERT INTO 表名 (字段1,字段2) VALUES ('值1','值2') -- 列和值,只要一一对应就好 INSERT INTO 表名 VALUES ('值1','值2'),('值1','值2'),.. -- 插入多行 INSERT INTO 表名 VALUES (SELECT 字段1 ,字段2 FROM 其他表) -- 查询出其他表的字段,列明无所谓,顺序要注意
更新数据
update 表名 set 字段a ='值1',.. WHERE id=123 -- 需要注意的是WHERE一定不要漏,要不然会更新全表
更新多行的时候如果中途出现错误,会将更新的恢复回原来的值。
如果要做到即使中途发生错误也要继续更新可以采用 IGNORE关键字:update ignore 表名 set ....
删除数据
删除一个列的值:SET username=null,前提是该字段允许为null
删除一行:delete from 表名 where id=123
删除整个表的行 delete from 表名 ,(此时只是记录清空)。
turncate 表名,也有记录清空的效果。不同的是turncate是先删除表,然后新建立一个同名表
表更新
ALTER TABLE 表名 ADD 字段a CHAR(20) -- 添加一列 ALTER TABLE 表名 DROP COLUMN 字段1 -- 删除一列 ALTER TABLE 表名 CONSTRAINT foregin_key FOREGIN KEY (字段a) REFERENCES 外表 (字段1) -- 定义外键 ALTER TABLE 表名 ADD PRIMARY KEY (id) -- 添加主键
视图
创建视图:CREATE VIEW 视图名称 AS SELECT 字段1,,... FROM 表名 删除视图:DROP VIEW MY_VIEW
当我们查询后出现一个结果,包装成一个虚拟表,也就是视图,我们可以把视图当成表使用(仅查看);
视图本身不包含数据,数据是从其他表检索出来;
使用视图可以重用SQL,并且可以保护数据,可以授予用户部分数据权限而不是全部数据;
如视图中存在分组(GROUP BY)、联结、子查询、并(UNOIN)、聚合函数(SUM/COUNT等)、计算字段、DISTINCT等都不能对视图进行更新操作;
存储过程
有些时候SQL也需要有逻辑判断(If),这样就出现一种“把多条SQL语句封装在一起执行”的场景,也就是存储过程,这样不仅简单安全而且性能也会更高(减少了多次的SQL网络传输时间)
注意:存储过程并不显示结果,只是将结果返回给你指定的变量。
执行的方式:1、创建一个存储过程;2、调用存储过程,将参数传入;3、SELECT参数输出结果。
参数类型说明: in 传递给存储过程,out 从存储过程传出,inout 对存储过程传入传出。结果将返回给OUT变量
示例:
创建存储过程:
CREATE PROCEDURE pro_name ( IN @inputParaValue INT, OUT @outParaVlaue INT ) BEGIN SELECT count(id) FROM tableA WHERE age =@inputParaValue INTO @outParaVlaue END
调用 和 输出:
call pro_name (123,@outParaVlaue); select @outParaVlaue;-- 调用并且会输出@outParaVlaue
另外:
show create procedure 存储过程名字 -- 显示此存储过程的创建语句 show procedure status -- 列出所有存储过程
删除:drop procedure procedurename
触发器
我们还有一种需求:事件(INSERT UPDATE DELETE)发生的前后自动执行某些语句,此时就是触发器的作用了。
CREATE TRIGGER <触发器名称> -- 触发器必须有名字,最多64个字符,可能后面会附有分隔符.它和MySQL中其他对象的命名方式基本相象.
{ BEFORE | AFTER } -- 触发器有执行的时间设置:可以设置为事件发生前或后。
{ INSERT | UPDATE | DELETE } -- 同样也能设定触发的事件:它们可以在执行insert、update或delete的过程中触发。
ON <表名称> -- 触发器是属于某一个表的:当在这个表上执行插入、 更新或删除操作的时候就导致触发器的激活. 我们不能给同一张表的同一个事件安排两个触发器。
FOR EACH ROW -- 触发器的执行间隔:FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次。
<触发器SQL语句> -- 触发器包含所要触发的SQL语句:这里的语句可以是任何合法的语句, 包括复合语句,但是这里的语句受的限制和函数的一样。
-- 必须拥有相当大的权限才能创建触发器(CREATE TRIGGER),如果你已经是Root用户,那么就足够了。这跟SQL的标准有所不同。
一个表最多6个触发器,插入删除更新的前后。
create trigger trigger_Name after insert on tabe1 for each row begin -- 要做的一些操作 insert into tab2(tab2_id) values(new.tab1_id); end
在触发器中可以引用NEW新的虚拟表,访问插入的行。可以引用OLD虚拟表,访问被删除的行。
注意: 只有表支持触发器,视图不支持; 触发器中不能调用存储过程。
删除触发器:DROP TRIGGER trigger_Name
MySql引擎
使用命令,查看库的所有引擎:
show storage Engines
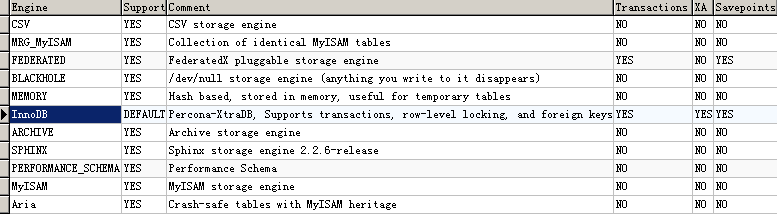
查看目的表的引擎方法:
show create table 表名
新建标的时候,在create语句的最后,加上 ENGINE =引擎名,可为表指定引擎。
修改表的引擎:
alter table 表名 engine=引擎名;
MyISAM读操作性能好;InnoDB支持事务,写操作更好并发度。
| MyISAM | InnoDB | |
|---|---|---|
| 存储文件 | 三个文件组成。.frm(存储表定义).MYD (存储数据文件)。.MYI (存储索引)。 | 所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。 |
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 自增列 | 必须是索引列,不需要一定是组合索引的第一列 | 必须是索引,若是组合索引,必须是组合索引的第一列 |
| 查询行数 | 存储了表的行数,查找时候很快 | 必须扫描全表 |
| 增删改查优势 | 适合查询 | 新增和修改 |
| 锁 | 表锁 | 行锁、表锁 |
| 删除表数据 | 重建表方式 | 一行一行删 |
| 存储空间 | 表支持3种存储格式,静态表(默认存储格式,每条记录固定长度),动态表(每条记录不是固定长度,存储的空间减少了),压缩表(每条记录被单独压缩,占据空间更少) | 需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引 |
| 可移植性 | 数据以文件形式存储,跨平台转移方便 | 所有表都保存在同一个数据文件(也可能是多个文件),相对来说不好备份 |
作者:Eric Li
出处:http://www.cnblogs.com/ericli-ericli/
除转载文章外,随笔版权归作者和博客园所有,欢迎转载,转载请标明出处。
如果您觉得本篇博文对您有所收获,觉得作者还算用心,请点击右下角的 [推荐],谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号