

<三>从编译器角度理解C++代码编译和链接原理
代码1
**sum.cpp**
int gdata=10;
int sum(int a,int b){
return a+b;
}
**main.cpp**
extern int gdata;
int sum(int , int );
int data=20;
int main(){
int a =gdata;
int b=data;
int ret=sum(a,b);
return 0;
}
1:编译

需要关注的几个点
1:.o 文件的格式组成是什么样子?
2:.exe 文件的组成格式是什么样子?
3:"所有.o文件段的合并 符号表合并后,进行符号解析"
4: "符号的重定位(重定向)"
5: "符号表的输出"=> "符号"
6: 符号什么时候分配虚拟地址?
预编译
以#开头的命令
除#pragma lib -> 链接阶段处理
除#pragma link -> 链接阶段处理
编译
语法分析,语义分析,代码优化 gcc g++
编译汇编后生成相应平台的 汇编代码 X86 和 AT&T
链接
链接所有 .o文件和 静态库文件


.o 文件 主要是由以下组成
elf 文件头
.text
.data
.bss
.symtab
.section table
....
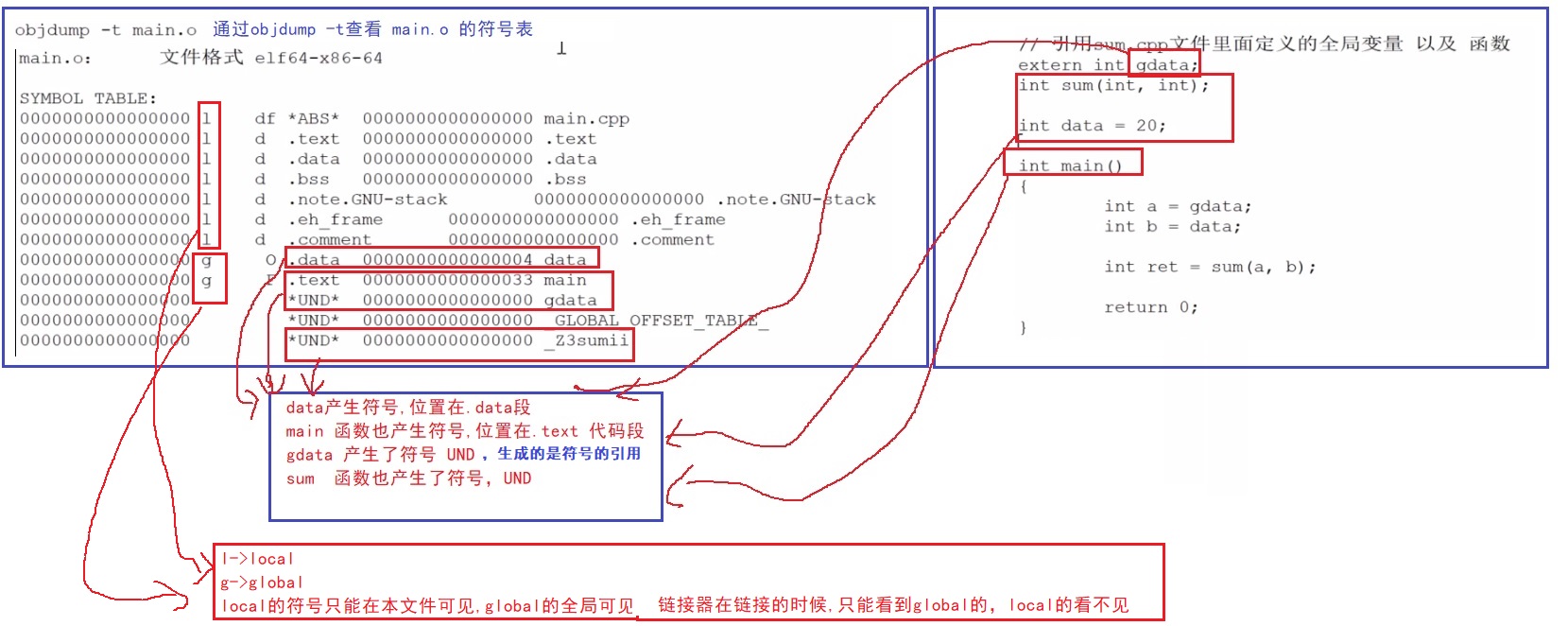
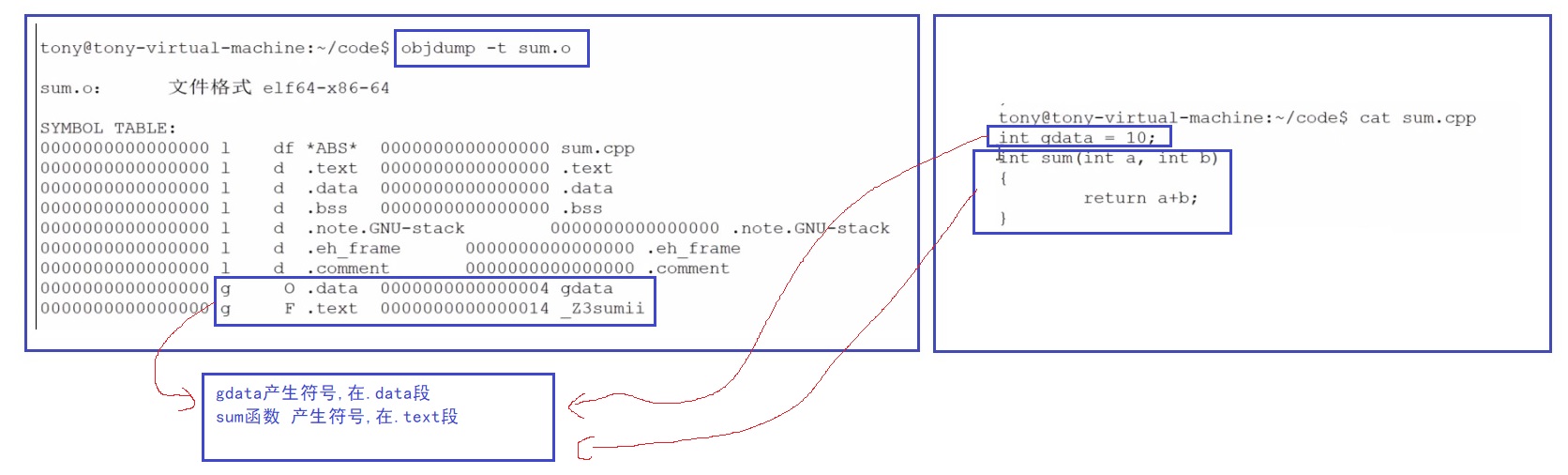
符号表中,在自己文件中定义的,那就是符号定义,如果是引用外部的就 是 "UND"符号引用
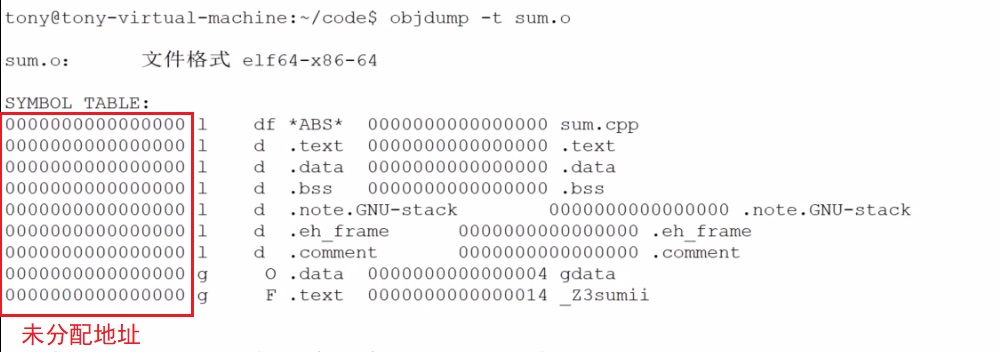
符号表中的符号 都没有分配地址,如下图,所以编译过程中,符号是不分配虚拟地址的,是在链接的时候分配

经过了上面的 预编译-》编译-》汇编 各个阶段后 下面开始进入了 链接阶段
main.o 文件 sum.o 文件
上面我们看到 .o 文件是由各个段组成的,所以进入链接阶段的时候
第一步 将各个.o 文件 的各个段合并
main.o 文件的 .text段 与 sum.o 文件的 .text 段合并
main.o 文件的 .data段 与 sum.o 文件的 .data 段合并
main.o 文件的 .bss段 与 sum.o 文件的 .bss 段合并
main.o 文件的 符号表 与 sum.o 文件的符号表 段合并
第二步 非常重要的一点是 在main.o文件的符号表与sum.o文件的符号表段合并的时候,需要进行符号解析。
什么是"符号解析"?
所有对符号的引用,都要找到该符号定义的地方 “符号的引用” 即符号为 UND形式, 要找到该符号定义的地方即要找到该符号是在.text 段中定义还是在.data段中定义,
例如:链接器发现main.o文件的sum函数和gdata是UND形式的,那么链接器会去其他文件中找到sum和gdata的定义,如果没找到,那么链接器报错"符号未定义",
如果链接器找到了多个,那么链接器也会报错 “符号重定义”,所以在整个工程中,全局的名字是不能重名的,否则会产生冲突.
符号解析成功以后 就开始回给所有的符号分配地址
第三步 "符号重定向"
在符号解析成功以后并且给所有的符号分配地址后,需要继续做 "符号重定向"
在我们指令编译汇编生成.O文件的时候,生成的指令中的符号的地址都是用0 代理,如下图

现在我们需要将给符号分配好的地址 将指令中的这些0地址重新修正
现在我看下链接后的情况
符号表情况

指令情况
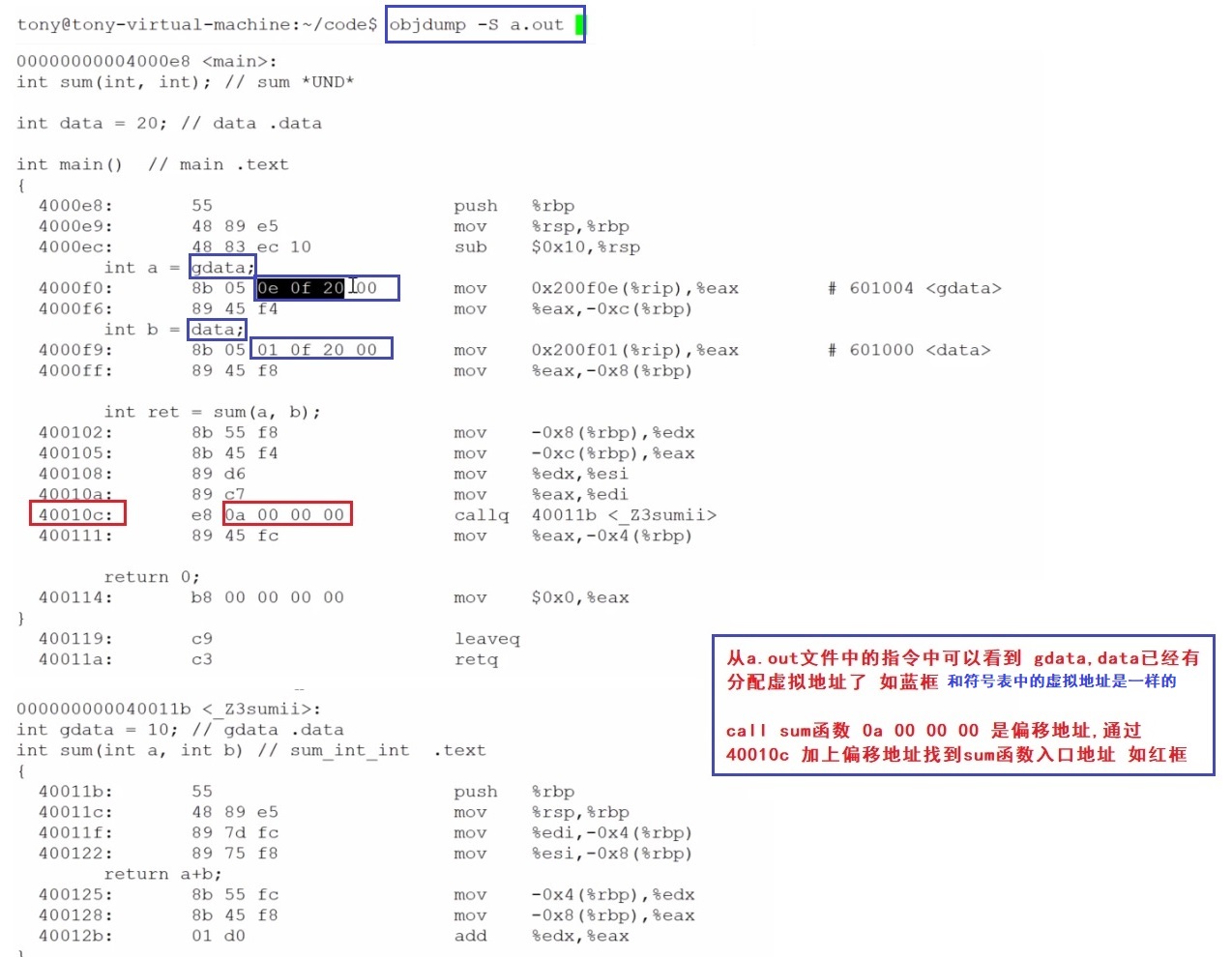
所以现在我们知道 “符号是在什么时候分配地址”, 在链接第一阶段 符号解析成功后

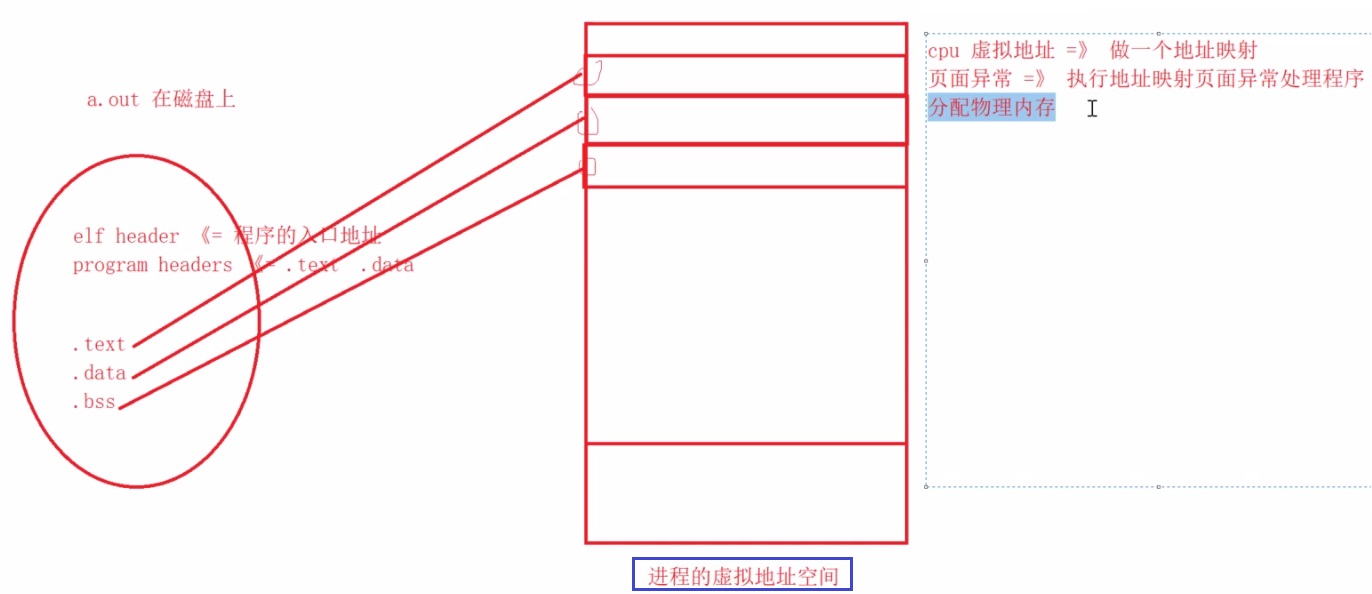
可执行文件 a.out 和 .O文件的组成方式很像,但是还是有一点区别

在a.out 可执行文件中 增加了 “program headers” , a.out 文件中不是 所有的内容都会加载到内存中的,这个
"program headers"中指定了需要加载哪些到内存中

上图中的 有两个load 就是需要加载到内存中的.
下面我们再看看可执行程序加载到内存过程


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!