莫烦Python:Scikit-learn (sklearn) 优雅地学会机器学习笔记
当今存在的机器学习方法包含:
监督学习,无监督学习,半监督学习,强化学习,遗传算法
有监督的分类,无监督的聚类,线性回归预测,高维数据降维。
PCA:主成分分析,降维。
通用学习模式
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier # K近邻算法
iris = datasets.load_iris() # 导入鸢尾花的数据
iris_x = iris.data
iris_y = iris.target # 属性
print(iris_x[:2, :]) # 花的属性值,长,宽,高...
print(iris_y) # 有三类品种 0 1 2
x_train, x_test, y_train, y_test = train_test_split(iris_x,
iris_y, test_size=0.3) # 把数据分为训练和测试集,按照0.3的比例
print(y_train) # 可以看出再划分的时候进行了置乱
knn = KNeighborsClassifier() # 调出分类器
knn.fit(x_train, y_train) # .fit()就是开始进行训练
print(knn.predict(x_test)) # 输出预测结果
print(y_test) # 输出真实值
'''
运行结果:
[0 2 1 2 1 1 2 0 0 0 2 0 2 0 1 1 1 1 1 2 2 0 0 1 2 2 2 2 1 1 2 2 0 0 0 2 1
0 0 1 1 1 1 0 0]
[0 1 1 2 1 1 2 0 0 0 2 0 2 0 1 1 1 1 1 2 2 0 0 1 2 2 2 2 1 1 2 2 0 0 0 2 1
0 0 1 1 1 1 0 0]
'''
sklearn的datasets数据库
from sklearn import datasets
from sklearn.linear_model import LinearRegression
from matplotlib.pyplot as plt
loaded_data = datasets.load_boston()
data_X = loaded_data.data # 导入数据
data_y = loaded_data.target # 导入属性label
model = LinearRegression()
model.fit(data_X, data_y)
print(model.predict(data_X[:4, :])) # 预测值
print(data_y[:4]) # 真实值
'''
运行结果:
[30.00384338 25.02556238 30.56759672 28.60703649]
[24. 21.6 34.7 33.4]
'''
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# loaded_data = datasets.load_boston()
# data_X = loaded_data.data # 导入数据
# data_y = loaded_data.target # 导入属性label
#
# model = LinearRegression()
# model.fit(data_X, data_y)
#
# print(model.predict(data_X[:4, :])) # 预测值
# print(data_y[:4]) # 真实值
'''构建自己的数据'''
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=1)
# 创建一些数据点,100个sample点,noise表示数据加噪,noise越大,结果越离散
plt.scatter(X, y)
plt.show()
运行结果:
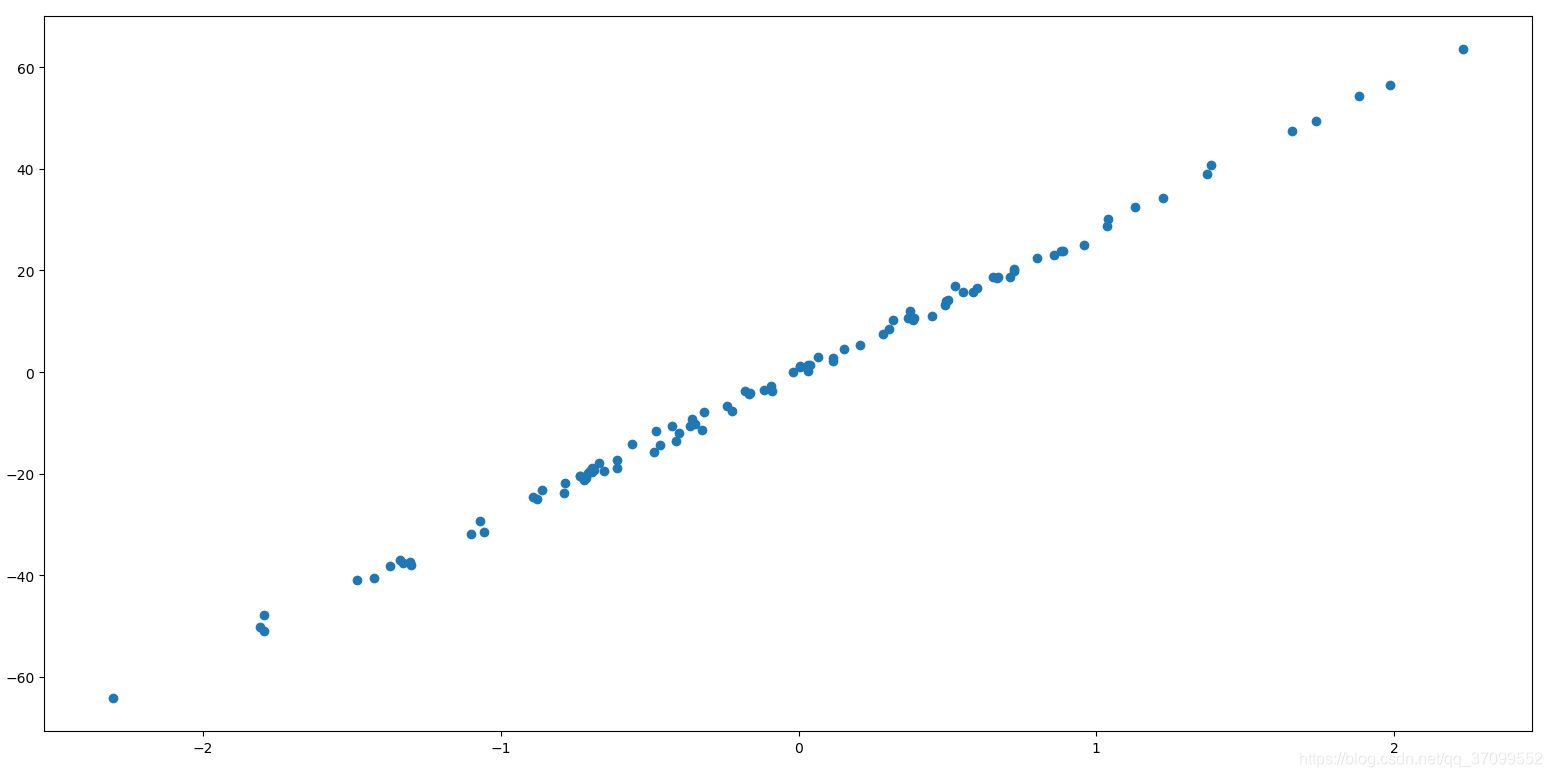
noise = 10
model 常用属性和功能
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
loaded_data = datasets.load_boston()
data_X = loaded_data.data # 导入数据
data_y = loaded_data.target # 导入属性label
model = LinearRegression()
model.fit(data_X, data_y)
# print(model.predict(data_X[:4, :])) # 预测值
# print(data_y[:4]) # 真实值
'''model的其他属性'''
print(model.coef_) # 权重系数(斜率)
print(model.intercept_) # 偏置(截距)
'''
有多少个系数,就会有多少个参数,LinearRegression是线性回归,也可能是曲线,不同的属性乘以下面不同的值
[-1.08011358e-01 4.64204584e-02 2.05586264e-02 2.68673382e+00
-1.77666112e+01 3.80986521e+00 6.92224640e-04 -1.47556685e+00
3.06049479e-01 -1.23345939e-02 -9.52747232e-01 9.31168327e-03
-5.24758378e-01]
36.459488385089855
'''
print(model.get_params()) # 返回model定义的参数,没有定义的话就是默认参数
'''{'copy_X': True, 'fit_intercept': True, 'n_jobs': None, 'normalize': False}'''
print(model.score(data_X, data_y))
# 用data_X做为训练,data_y作为预测,到底有多吻合,来对模型进行打分,采用R^2可决系数进行打分,coefficient of determination
'''0.7406426641094095'''
normalization标准化
'''
Make true features are on a similar scale,当两个参数跨度比较大时,比较难找到最好的那个点,所以我们
同时除以他们的维度,让他们的范围跨度没那么大,更容易找到最优的点
特征缩放,标准化,预处理方便机器学习处理的结构
'''
from sklearn import preprocessing
import numpy as np
a = np.array([[10, 2.7, 3.6],
[-100, 5, -2],
[120, 20, 40]], dtype=np.float64)
print(a)
print(preprocessing.scale(a))
'''
运行结果:
[[ 10. 2.7 3.6]
[-100. 5. -2. ]
[ 120. 20. 40. ]]
[[ 0. -0.85170713 -0.55138018]
[-1.22474487 -0.55187146 -0.852133 ]
[ 1.22474487 1.40357859 1.40351318]]
'''
from sklearn import preprocessing
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC # 支持向量机,也叫大间距分类器
import matplotlib.pyplot as plt
X, y = make_classification(n_samples=300, n_features=2, n_redundant=0, n_informative=2,
random_state=22, n_clusters_per_class=1, scale=100)
# plt.scatter(X[:, 0], X[:, 1], c=y)
# plt.show()
# X = preprocessing.scale(X) # 数据压缩,归一化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) # 数据划分
clf = SVC()
clf.fit(X_train, y_train) # 进行训练
print(clf.score(X_test, y_test)) # 输出预测结果的准确性分值
'''实验结果:0.9222222222222223'''
'''当没有归一化的时候,实验结果:0.43333333333333335'''
cross-validation交叉验证
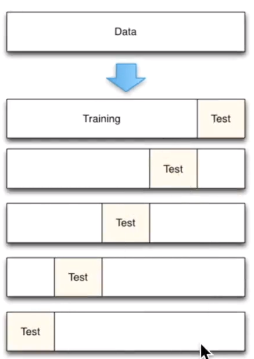
'''cross-validation交叉验证'''
'''通过不同参数之间或者其他属性之间的结果来判断模型的好坏'''
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4) # 这里的默认划分比例时0.3
knn = KNeighborsClassifier(n_neighbors=5) # 这里表示选取某个点附近的5个点进行预测
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print(knn.score(X_test, y_test))
'''运行结果:0.9736842105263158'''
cross-validation
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4) # 这里的默认划分比例时0.3
knn = KNeighborsClassifier(n_neighbors=5) # 这里表示选取某个点附近的5个点进行预测
knn.fit(X_train, y_train)
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy') # 使用的模型是knn,cv=5是把X,y自动分成5组不同的训练和测试
print(scores.mean()) # 5组平均的得分0.9733333333333334
当不同的k值时:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
iris = load_iris()
X = iris.data
y = iris.target
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') # for classification
k_scores.append(scores.mean()) # 不同的k生成的10组预测结果的平均值,罗列出来
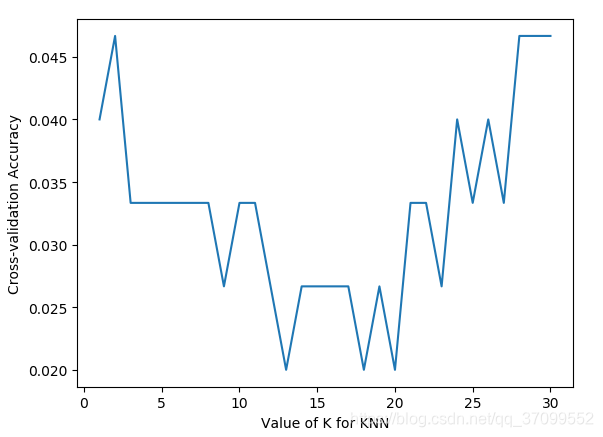
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-validation Accuracy')
plt.show()
结果:
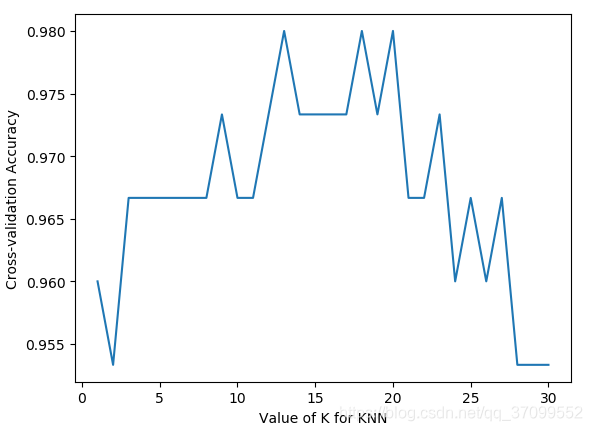
k越小过拟合,k越大欠拟合
loss:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics.scorer import make_scorer
import matplotlib.pyplot as plt
iris = load_iris()
X = iris.data
y = iris.target
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
# scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') # for classification
loss = -cross_val_score(knn, X, y, cv=10, scoring='neg_mean_squared_error') # for regression,均方差回归损失
# k_scores.append(scores.mean()) # 不同的k生成的10组预测结果的平均值,罗列出来
k_scores.append(loss.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-validation Accuracy')
plt.show()