莫烦Python:Scikit-learn (sklearn) 优雅地学会机器学习笔记(2)
cross-validation 交叉验证2
'''cross-validation (2)'''
from sklearn.model_selection import learning_curve # 可视化学习的过程,怎样降低误差的
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
'''载入数据'''
digits = load_digits()
X = digits.data
y = digits.target
'''学习曲线上显示学习的长度(就是在图上0.1..这些点上显示),训练和测试误差'''
train_sizes, train_loss, test_loss = learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring='neg_mean_squared_error',
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
train_loss_mean = -np.mean(train_loss, axis=1) # 因为loss一般是负的,所以用负号
test_loss_mean = -np.mean(test_loss, axis=1) # axis=1,表示按列表的列方向进行平均
'''display'''
plt.plot(train_sizes, train_loss_mean, 'o-', color="r", label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g", label="Cross-validation")
plt.xlabel("Training example")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
gamma = 0.001
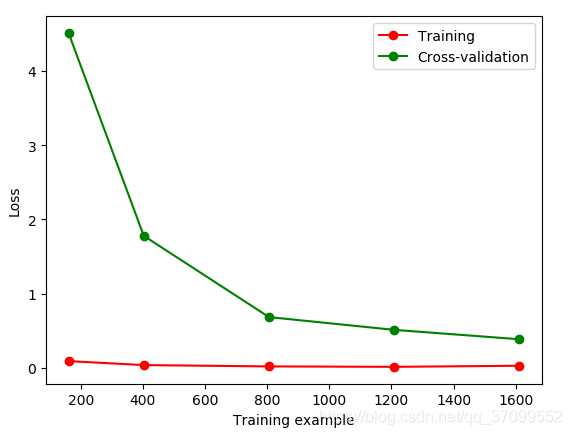
gamma = 0.01
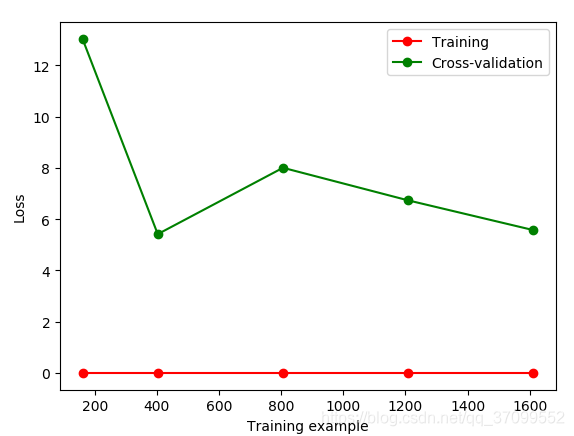
过拟合:对训练集可以很好的拟合效果,但是测试集的效果就会很差
怎样解决过拟合
如何选取合适的gamma,既不会出现过拟合,也不会出现欠拟合
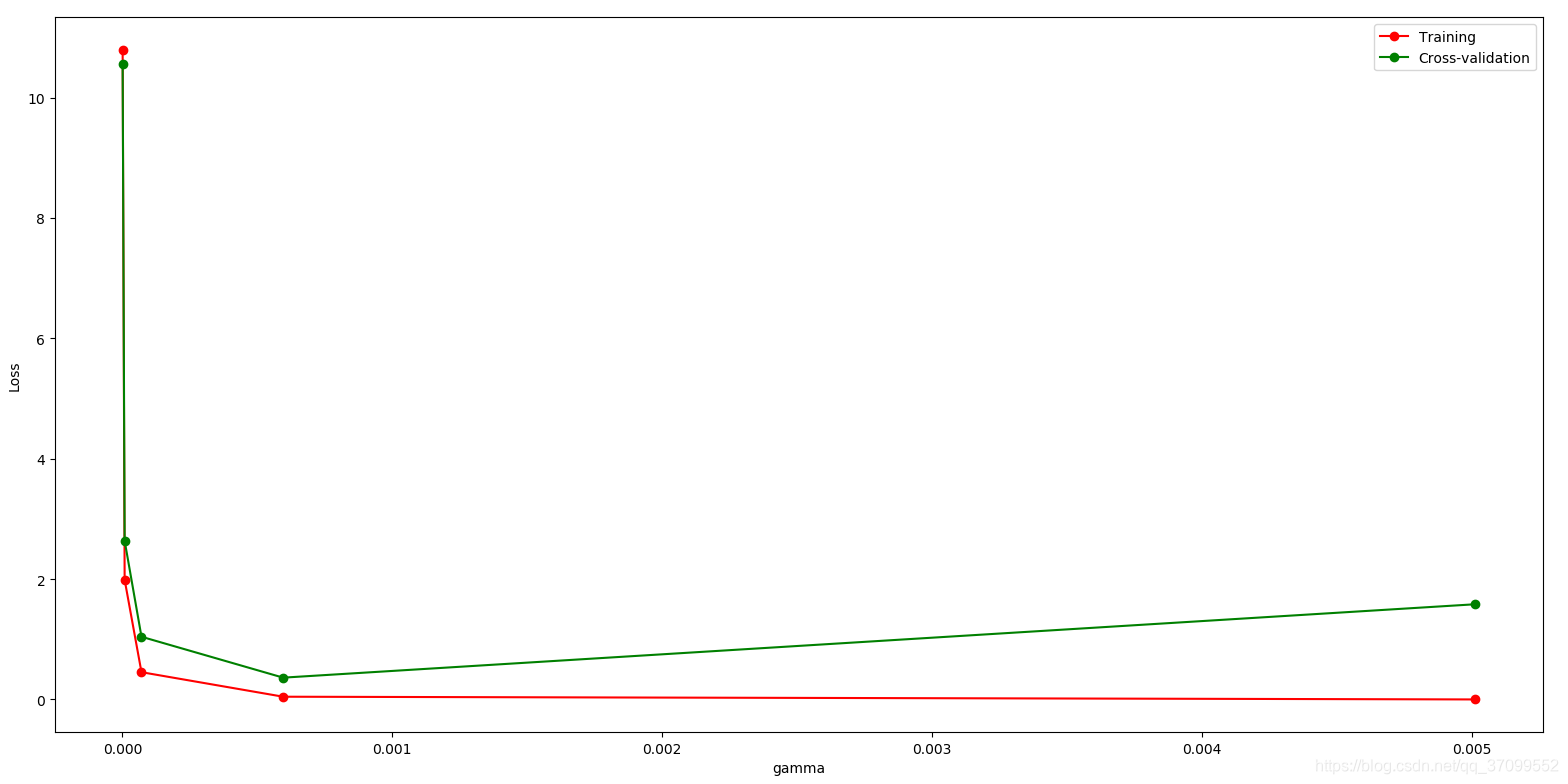
保存model
'''保存model'''
from sklearn import svm
from sklearn import datasets
import pickle
# clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
# clf.fit(X, y)
# method 1 : pickle
with open('save/clf.pickle', 'rb') as f:
clf2 = pickle.load(f)
print(clf2.predict(X[0:1]))
'''运行结果:[0]'''
from sklearn import svm
from sklearn import datasets
import pickle
#
clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X, y)
#
# # method 1 : pickle
# with open('save/clf.pickle', 'rb') as f:
# # clf2 = pickle.load(f)
# # print(clf2.predict(X[0:1]))
# #
# # '''运行结果:[0]'''
# method 2 : joblib
from sklearn.externals import joblib # sklearn 的外部模块
# Save
joblib.dump(clf, 'save/clf.pkl')
# restore
clf3 = joblib.load('save/clf.pkl')
print(clf3.predict(X[0:1]))
