
Coverless Image Steganography Based on Generative Adversarial Network
基于生成对抗网络的无载体图像隐写技术
摘要
- 传统图像隐写技术:修改/嵌入到载体图像来传输秘密信息—>隐写工具很容易检测到载体图像的失真—>秘密信息的泄露
- 无载体图像隐写技术:不修改载体图像就可以隐藏秘密信息。但存在容量低,质量差等问题。
本文提出了一种基于生成对抗网络的无载体图像隐写技术,通过将秘密信息编码到载体图像中,用对抗来优化隐写图像的质量,同时很好的避开隐写分析工具的检测。
介绍
传统的隐写技术容易被隐写分析工具检测出来,因此,2015年研究人员提出了无载体图像隐写术,它通过秘密信息的映射来实现,而不再对载体图像进行修改,因此称之为“无载体”。即便图像被截获,不知道映射规则,也很难检测出秘密信息。
目前,无载体图像隐写技术主要分为两类:基于映射规则的方法和基于合成的方法。
基于实例的纹理合成算法是当前纹理合成算法的一个热点,它通过对原始图像进行重采样来合成新的纹理图像。新图像大小可以是任意的,且局部外观与原始图像相似
随着深度学习的出现,基于深度学习的无载体技术逐渐发展起来,但是CNN需要空见相关性很强的图像,因此不能应用于任意数据。GANs的出现为图像隐写提供了新的途径。
我们提出了一种基于CNN和GAN的实现无载体隐写的方案:
- 提出了基于GAN的隐写方法,相对有效负载为2.36位/像素
- 提出了一种基于深度学习的隐写算法的图像质量评估方法
方法
一般而言,隐写术只需要两个操作:编码和解码,由三个模块组成:
- 编码器网络:接收无载体图像和二进制秘密信息串,生成隐写图像。
- 解码器网络:获得隐写图像通过解码器网络尝试恢复秘密信息。
- 鉴别器网络:用来评估矢量和隐写图像的质量。

编码器网络
首先将大小为3WH的载体图像和秘密信息M(DepthWH)输入到编码器网络中。M是DepthWH的数据张量。Depth是我们试图在载体图像的每个像素中隐藏的位数。W×H代表封面图像的大小。编码后的图像在视觉上应该与封面图像相似。我们对编码器网络进行两个操作:
- 用卷积块Conv对封面图像C进行处理,得到尺寸为(32×W×H)的张量a
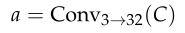
- 将消息M与a连接,然后用卷积块Conv处理张量b,b的大小为(32×W×H)
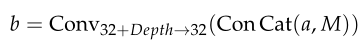
然后我们建立了两个编码器网络: - 基本模型:我们将两个卷积块Conv应用于张量b,生成隐写图像S。形式上:
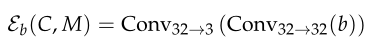
- 密集模型:我们使用跳跃连接[24]将前一个密集块生成的特征 f 映射到后一个密集块生成的特征 l ,如图1所示。我们假设使用跳转连接可以提高嵌入率。正式地:
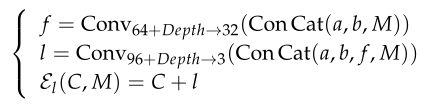
解码器网络
解码器网络G使用由编码器网络ε生成的隐写图像S。解码网络生成M0=G(S),并根据Reed-Solomon算法恢复秘密信息张量M。
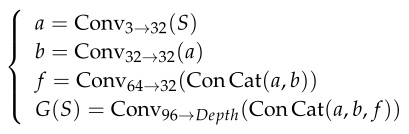
鉴别器网络
为了对编码器ε的性能提供反馈并生成更真实的图像,我们引入了一个鉴别器网络D,它可以区分隐写图像S和载体图像C。
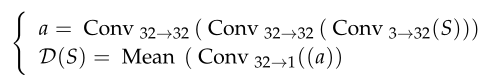
XuNet是一种基于CNN的图像隐写分析软件。为了改进统计建模:
- 在第一个卷积层中嵌入绝对激活(ABS)
- 在网络浅层应用TanH激活函数以防止过度拟合
- 在每个非线性激活层前添加批处理归一化(BN)
这种设计良好的CNN在隐写分析中具有良好的检测性能。据我们所知,它是性能最好的基于JPEG的数据驱动CNN隐写分析器。因此,我们设计了基于XuNet的隐写分析器,并对其进行了调整以适应我们的模型。
鉴别器网络D由五个卷积块和SPP块以及两个完全连接的标量输出层组成。为了生成标量分数,我们在卷积层的输出上使用了自适应均值池。此外,我们使用空间金字塔池(SPP)模块来代替全局平均池层。空间金字塔池(SPP)模块[22]及其变体在目标检测和语义分割模型中发挥着巨大的作用。它突破了全连通层的限制,使得任何尺寸的图像都可以输入到下一个完全连通的层。同时,SPP模块可以从不同的接受域中提取更多的特征,从而提高性能。我们的隐写分析器的详细架构如表1所示。

目标函数
c被称为载体图像C中的一个,可以用概率分布函数P来表示,我们让载体图像c跟随P,并嵌入秘密消息M,统计散度(KL)也可由公式(7)中的概率散度(KL)来量化,
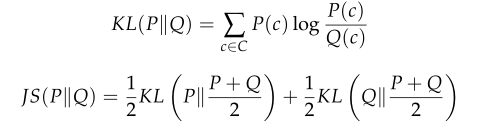
KL散度和JS散度是非常基本的量,它们建立了最佳的概率隐写分析。最初GAN的目标是最小化JS散度或KL散度[31]。带噪声z的编码器网络ε尝试生成与覆盖图像C相似的图像,鉴别器网络D接收生成的图像并判断它们是真样本还是假样本。鉴别器网络D和编码器140网络ε使用代价函数(9)来玩minimax博弈。它训练D使训练样本和ε样本的正确标签分配概率最大化。因此,GAN可以用来解决隐写问题:
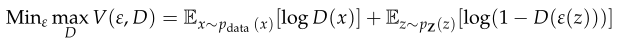
编码器解码器损失:
为了优化编解码网络,本部分联合优化了三个损耗函数
- 采用交叉熵损失函数来评价译码器网络的译码精度,即:
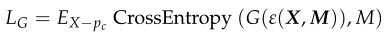
- 利用均方误差来分析隐写图像与封面图像的相似性,其中W是图像的宽度,H是图像的长度,也就是说:
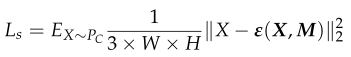
- 以及使用鉴别器的隐写图像的真实性,即

综上:所以,训练的目标是:
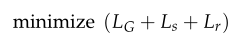
结构相似性指数
Baluja[14]使用封面图像像素和生成的图像像素之间的均方误差(MSE)作为损失函数。然而,MSE只对两幅图像对应像素的较大误差进行惩罚,而忽略了图像的底层结构。人类视觉系统(HVS)对无文本区域的亮度和颜色的变化更为敏感,因此在损失函数中引入了结构相似性指数SSIM及其变体MS-SSIM[29]。
SSIM指标从亮度δ、对比度e和结构ρ三个方面对相似性度量任务进行比较。两幅图像的相似度分别用公式(14)、(15)和(16)来衡量,其中µx和µy是图像x和图像y的像素平均值,θx和θy是图像x和图像y的像素偏差,θxy是图像x和y的标准方差。此外,c1、c2和c3是防止分母移动的三个常数使公式变得毫无意义。SSIM的一般计算方法如(17)所示,其中l>0,m>0,n>0,它们是用来调整三个分量相对重要性的参数。SSIM索引的值范围为[0,1]。索引越高,两幅图像越相似。因此,隐写GAN使用1-SSIM(x,y)作为损失函数来度量两幅图像之间的差异。MS-SSIM[29]是SSIM索引的增强变体,因此它还引入了隐写术GAN的损耗函数。

考虑到像素值和结构的差异,我们将MSE、SSIM和MS-SSIM结合起来。因此,其混合损耗函数LD为:
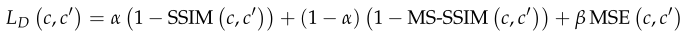
其中c代表封面图像,c0代表隐写图像。M是秘密信息,m0是从隐写图像中提取出来的。α和β是衡量隐写图像和覆盖图像质量的超级参数。我们将损失函数的α和β分别设为0.5、0.3
