
(笔记)第一章:零基础入门深度学习
人工智能、机器学习、深度学习的关系

机器学习
专门让计算机去模拟或实现人类的学习行为
机器学习的实现
机器学习的实现可以分成两步:训练和预测,类似于我们熟悉的归纳和演绎:
- 归纳:从具体案例中抽象一般规律。从大量样本中得到Y与X的关系
- 演绎:从一般规律推导出具体案例的结果。输入新的X到Y的式子中
确定模型参数
衡量模型预测值和真实值差距的评价函数也被称为损失函数(损失Loss)
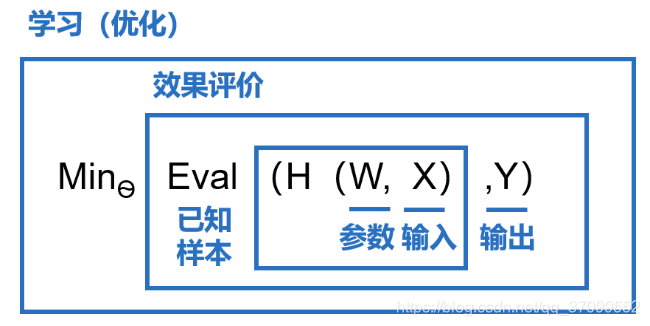
模型假设、评价函数(损失/优化目标)和优化算法是构成模型的三个部分
模型结构介绍
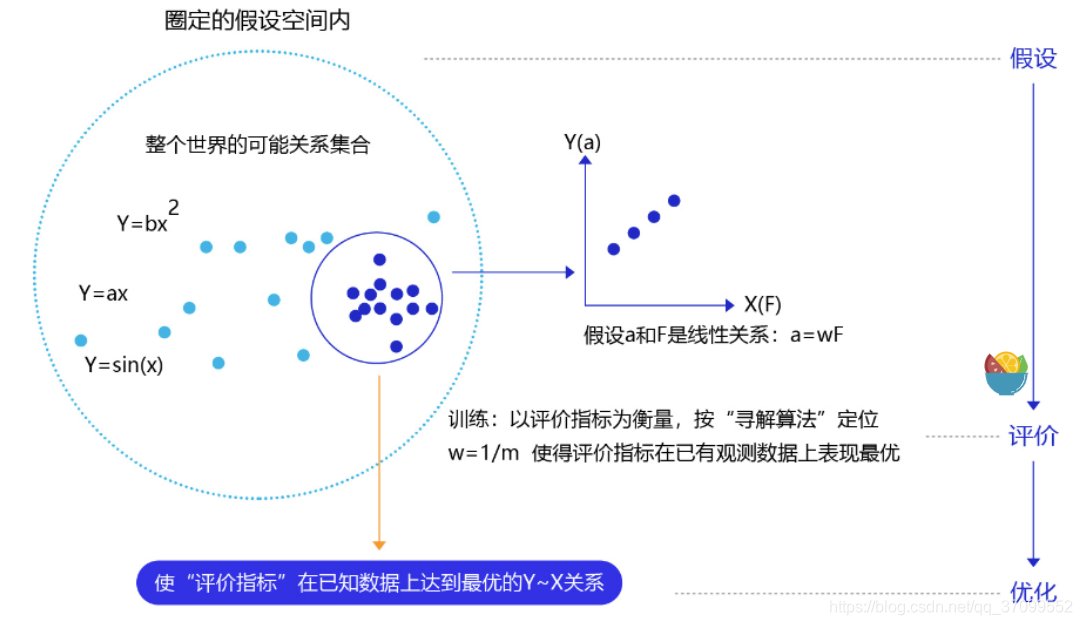
- 模型假设: 假设空间先圈定了一个模型能够表达的关系可能,机器还会进一步在假设圈定的圆圈内寻找最优的Y~X关系,即确定参数W。
- 评价函数: 寻找最优之前,我们需要先定义什么是最优,即评价一个Y~X关系的好坏的指标。通常衡量该关系是否能很好的拟合现有观测样本,将拟合的误差最小作为优化目标。
- 优化算法: 设置了评价指标后,就可以在假设圈定的范围内,将使得评价指标最优(损失函数最小/最拟合已有观测样本)的Y~X关系找出来,这个寻找的方法即为优化算法。最笨的优化算法即按照参数的可能,穷举每一个可能取值来计算损失函数,保留使得损失函数最小的参数作为最终结果。
深度学习
机器学习和深度学习在理论结构上是一致的,即:模型假设、评价函数和优化算法,其根本差别在于假设的复杂度。
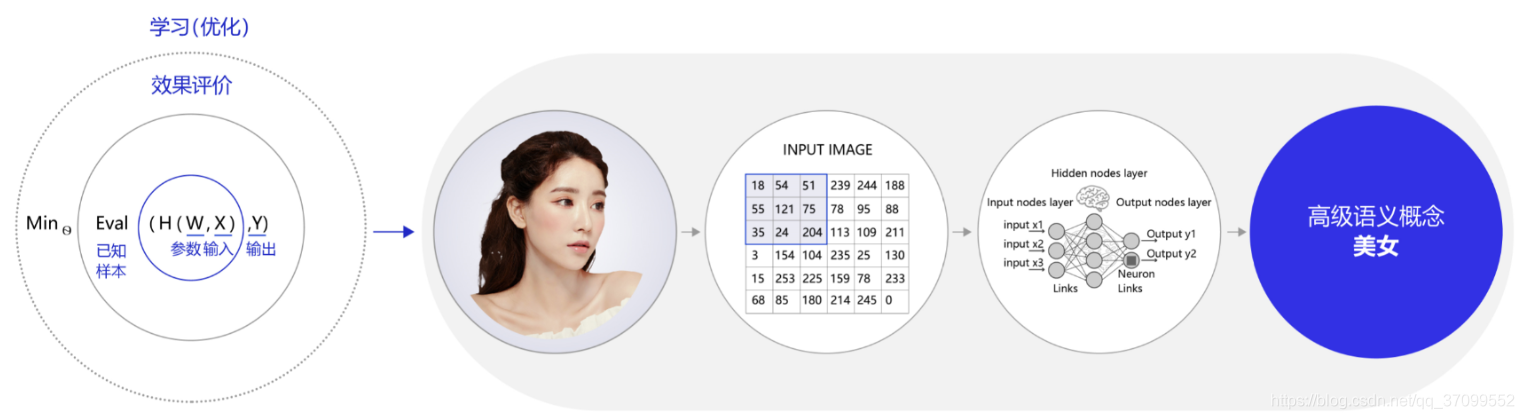
人脑可极快的反应出这是一位美女。但对计算机而言,只能接收到一个数字矩阵,对于美女这种高级的语义概念,从像素到高级语义概念中间要经历的信息变换的复杂性是难以想象的!这种变换已经无法用数学公式表达,因此研究者们借鉴了人脑神经元的结构,设计出神经网络的模型。
神经网络的基本概念
人工神经网络包括多个神经网络层,如卷积层、全连接层、LSTM等,每一层又包括很多神经元,超过三层的非线性神经网络都可以被称为深度神经网络。通俗的讲,深度学习的模型可以视为是输入到输出的映射函数,如图像到高级语义(美女)的映射,足够深的神经网络理论上可以拟合任何复杂的函数。因此神经网络非常适合学习样本数据的内在规律和表示层次,对文字、图像和语音任务有很好的适用性。因为这几个领域的任务是人工智能的基础模块,所以深度学习被称为实现人工智能的基础也就不足为奇了。
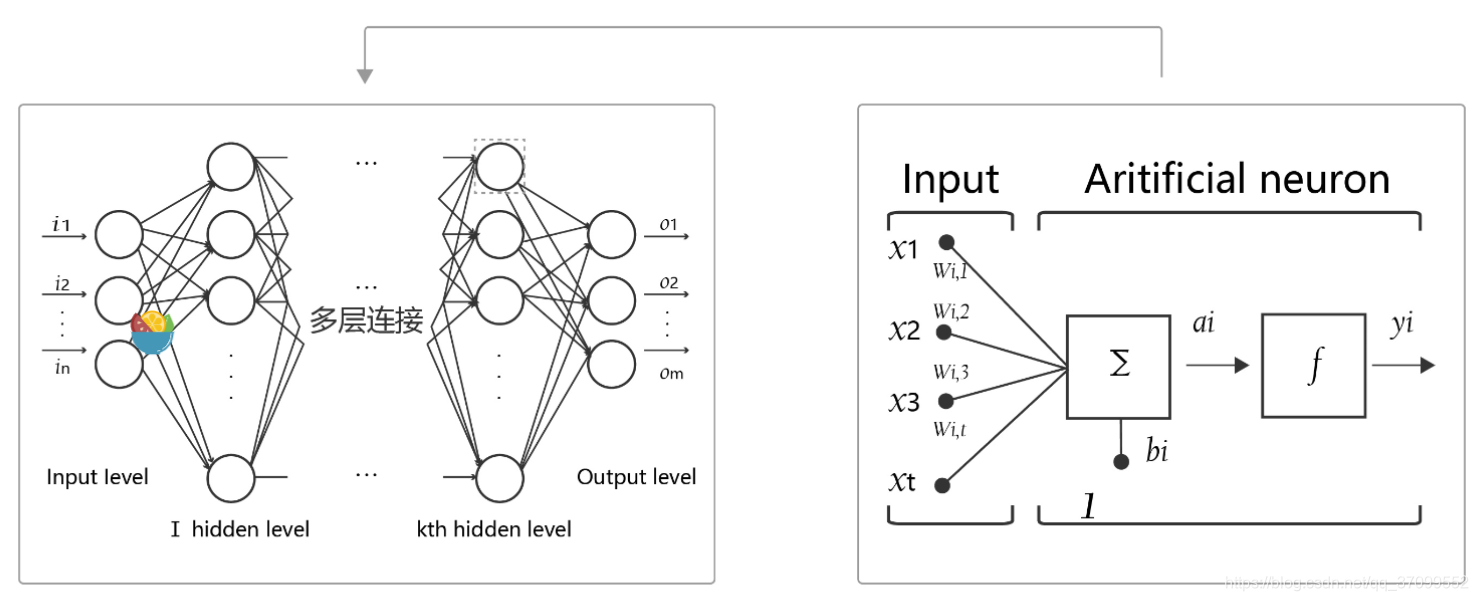
- 神经元: 神经网络中每个节点称为神经元,由两部分组成:
- 加权和:将所有输入加权求和。
- 非线性变换(激活函数):加权和的结果经过一个非线性函数变换,让神经元计算具备非线性的能力。
- 多层连接: 大量这样的节点按照不同的层次排布,形成多层的结构连接起来,即称为神经网络。
- 前向计算: 从输入计算输出的过程,顺序从网络前至后。
- 计算图: 以图形化的方式展现神经网络的计算逻辑又称为计算图。我们也可以将神经网络的计算图以公式的方式表达如下:
深度学习的发展历程
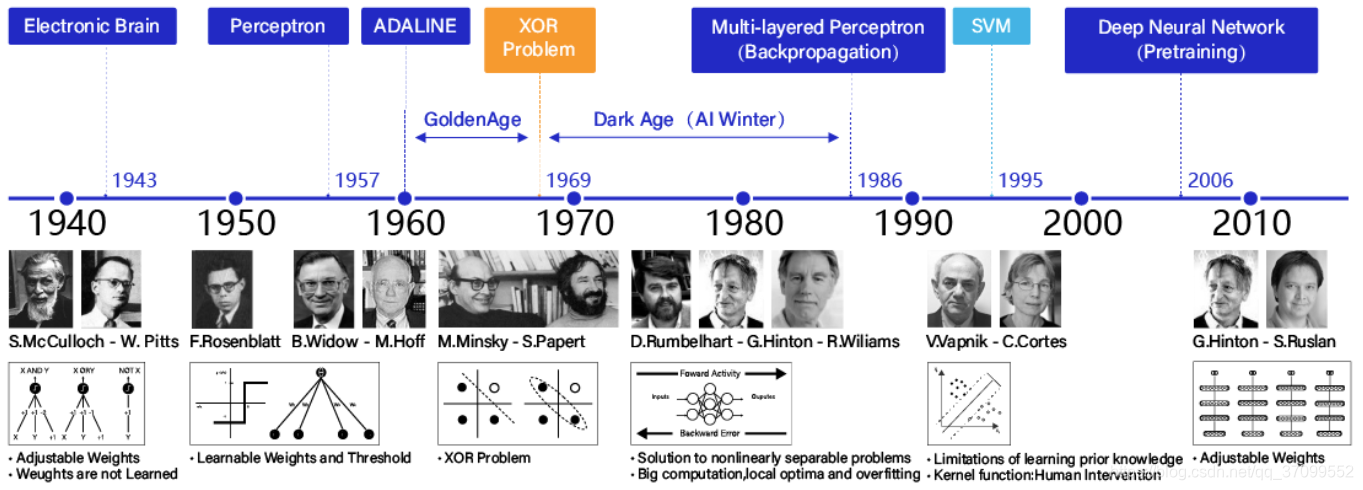
- 1940年代:首次提出神经元的结构,但权重是不可学的。
- 1950-60年代:提出权重学习理论,神经元结构趋于完善,开启了神经网络的第一个黄金时代。
- 1969年:提出异或问题(人们惊奇的发现神经网络模型连简单的异或问题也无法解决,对其的期望从云端跌落到谷底),神经网络模型进入了被束之高阁的黑暗时代。
- 1986年:新提出的多层神经网络解决了异或问题,但随着90年代后理论更完备并且实践效果更好的SVM等机器学习模型的兴起,神经网络并未得到重视。
- 2010年左右:深度学习进入真正兴起时期。随着神经网络模型改进的技术在语音和计算机视觉任务上大放异彩,也逐渐被证明在更多的任务,如自然语言处理以及海量数据的任务上更加有效。至此,神经网络模型重新焕发生机,并有了一个更加响亮的名字:深度学习。
为何神经网络到2010年后才焕发生机呢?这与深度学习成功所依赖的先决条件:大数据涌现、硬件发展和算法优化有关。
- 大数据是神经网络发展的有效前提。神经网络和深度学习是非常强大的模型,需要足够量级的训练数据。时至今日,之所以很多传统机器学习算法和人工特征依然是足够有效的方案,原因在于很多场景下没有足够的标记数据来支撑深度学习这样强大的模型。深度学习的能力特别像科学家托罗密的豪言壮语:“给我一根足够长的杠杆,我能撬动地球!”。深度学习也可以发出类似的豪言:“给我足够多的数据,我能够学习任何复杂的关系”。但在现实中,足够长的杠杆与足够多的数据一样,往往只能是一种美好的愿景。直到近些年,各行业IT化程度提高,累积的数据量爆发式地增长,才使得应用深度学习模型成为可能。
- 依靠硬件的发展和算法的优化。现阶段依靠更强大的计算机、GPU、Autoencoder预训练和并行计算等技术,深度网络在训练上的困难已经被逐渐克服。其中,数据量和硬件是更主要的原因。没有前两者,科学家们想优化算法都无从进行。
深度学习的研究和应用蓬勃发展
- 1998年使用神经网络模型识别手写数字图像
- 兴起是在2012年ImageNet比赛上使用AlexNet做图像分类
- 比较1998年和2012年的模型两者在网络结构上非常类似,仅在细节上有所优化
- 在这十四年间计算性能的大幅提升和数据量的爆发式增长,促使模型完成了从“简单的数字识别”到“复杂的图像分类”的跨越。
虽然历史悠久,但深度学习在今天依然在蓬勃发展,一方面基础研究快速进展,另一方面工业实践层出不穷。
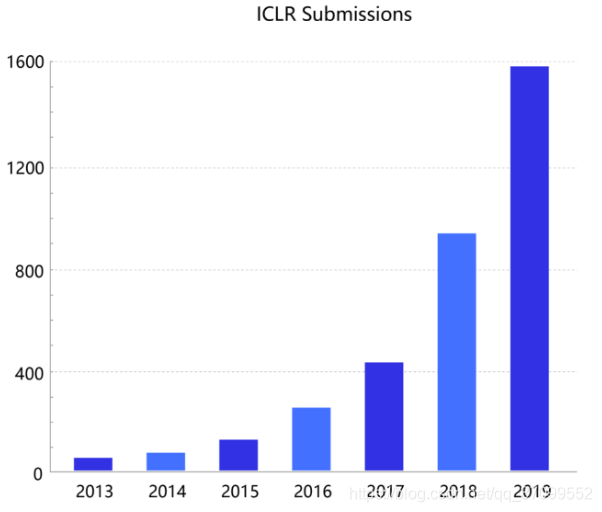
基于深度学习的顶级会议ICLR(international conference on learning representations)统计,深度学习相关的论文数量呈逐年递增的状态。同时,不仅仅是深度学习会议,与数据和模型技术相关的会议ICML和KDD,专注视觉的CVPR和专注自然语言处理的EMNLP等国际会议的大量论文均涉及着深度学习技术。该领域和相关领域的研究方兴未艾,技术仍在不断创新突破中。
以深度学习为基础的人工智能技术,在升级改造众多的传统行业领域,存在极其广阔的应用场景

深度学习改变了AI应用的研发模式
实现了端到端的学习
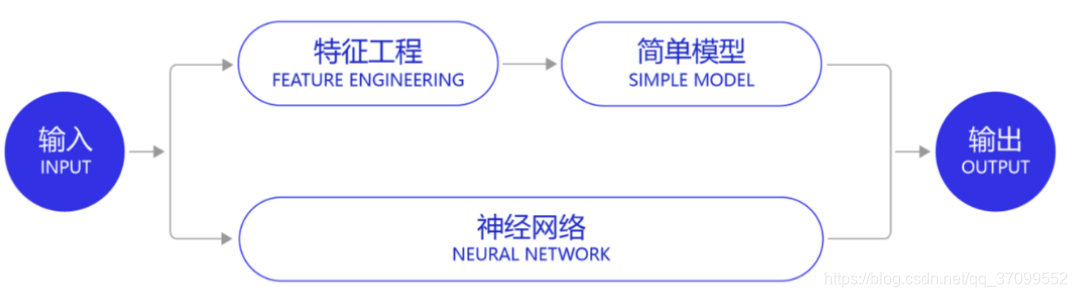
深度学习改变了很多领域算法的实现模式:
- 在深度学习兴起之前,很多领域建模的思路是投入大量精力做特征工程,将专家对某个领域的“人工”理解沉淀成特征表达,然后使用简单模型完成任务(如分类或回归)
- 而在数据充足的情况下,深度学习模型可以实现端到端的学习,即不需要专门做特征工程,将原始的特征输入模型中,模型可同时完成特征提取和分类任务
作业1-1
1.类比牛顿第二定律的案例,在你的工作和生活中还有哪些问题可以用监督学习的框架来解决?模型假设和参数是什么?评价函数(损失)是什么?
答:
犯罪嫌疑人的行为和所解触犯的刑法条文。
假设:刑法条文=f(犯罪嫌疑人的行为)。参数:主体、主观方面、客体、客观方面。
优化目标:法律面前人人平等,同罪同罚。
2.为什么说AI工程师有发展前景?怎样从经济学(市场供需)的角度做出解读?
答:
因为AI工程师是先进生产力的代表,生产力的发展决定了AI工程师的前景。
从经济学角度,先进生产力催生出了巨大的AI市场,但AI工程师人数较少,无法满足人力资源市场的需求,
AI工程师供不应求,因此AI工程师将很有发展前景。

