
(笔记)第二章:一个案例吃透深度学习(中)
目录
一、【手写数字识别】之网络结构
之前我们用与房价预测相同的简单神经网络解决手写数字识别问题,但是效果并不理想。
原因:是手写数字识别的输入是28 × 28的像素值,输出是0-9的数字标签。而线性回归模型无法捕捉二维图像数据中蕴含的复杂信息,牛顿第二定律任务以及房价预测任务,输入特征和输出预测值之间的关系均可以使用“直线”刻画(使用线性方程来表达)。但手写数字识别任务的输入像素和输出数字标签之间的关系显然不是线性的,甚至这个关系复杂到我们靠人脑难以直观理解的程度。

主要介绍两种常见的网络结构:经典的多层全连接神经网络和卷积神经网络
数据处理
#数据处理部分之前的代码,保持不变
import os
import random
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import gzip
import json
# 定义数据集读取器
def load_data(mode='train'):
# 数据文件
datafile = './work/mnist.json.gz'
print('loading mnist dataset from {} ......'.format(datafile))
data = json.load(gzip.open(datafile))
train_set, val_set, eval_set = data
# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLS
IMG_ROWS = 28
IMG_COLS = 28
if mode == 'train':
imgs = train_set[0]
labels = train_set[1]
elif mode == 'valid':
imgs = val_set[0]
labels = val_set[1]
elif mode == 'eval':
imgs = eval_set[0]
labels = eval_set[1]
imgs_length = len(imgs)
assert len(imgs) == len(labels), \
"length of train_imgs({}) should be the same as train_labels({})".format(
len(imgs), len(labels))
index_list = list(range(imgs_length))
# 读入数据时用到的batchsize
BATCHSIZE = 100
# 定义数据生成器
def data_generator():
if mode == 'train':
random.shuffle(index_list)
imgs_list = []
labels_list = []
for i in index_list:
img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.reshape(labels[i], [1]).astype('float32')
imgs_list.append(img)
labels_list.append(label)
if len(imgs_list) == BATCHSIZE:
yield np.array(imgs_list), np.array(labels_list)
imgs_list = []
labels_list = []
# 如果剩余数据的数目小于BATCHSIZE,
# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batch
if len(imgs_list) > 0:
yield np.array(imgs_list), np.array(labels_list)
return data_generator
经典的全连接神经网络
经典的全连接神经网络来包含四层网络:输入层、两个隐含层和输出层

- 输入层:将数据输入给神经网络。在该任务中,输入层的尺度为28×28的像素值。
- 隐含层:增加网络深度和复杂度,隐含层的节点数是可以调整的,节点数越多,神经网络表示能力越强,参数量也会增加。在该任务中,中间的两个隐含层为10×10的结构,通常隐含层会比输入层的尺寸小,以便对关键信息做抽象,激活函数使用常见的
sigmoid函数。 - 输出层:输出网络计算结果,输出层的节点数是固定的。如果是回归问题,节点数量为需要回归的数字数量;如果是分类问题,则是分类标签的数量。在该任务中,模型的输出是回归一个数字,输出层的尺寸为1。
说明:
隐含层引入非线性激活函数sigmoid是为了增加神经网络的非线性能力。
举例来说,如果一个神经网络采用线性变换,有四个输入~,一个输出。假设第一层的变换是和,第二层的变换是,则将两层的变换展开后得到。也就是说,无论中间累积了多少层线性变换,原始输入和最终输出之间依然是线性关系。
Sigmoid是早期神经网络模型中常见的非线性变换函数,通过如下代码,绘制出Sigmoid的函数曲线。
def sigmoid(x):
# 直接返回sigmoid函数
return 1. / (1. + np.exp(-x))
# param:起点,终点,间距
x = np.arange(-8, 8, 0.2)
y = sigmoid(x)
plt.plot(x, y)
plt.show()

针对手写数字识别的任务,网络层的设计如下:
- 输入层的尺度为28×28,但批次计算的时候会统一加1个维度(大小为batchsize)。
- 中间的两个隐含层为10×10的结构,激活函数使用常见的
sigmoid函数。 - 与房价预测模型一样,模型的输出是回归一个数字,输出层的尺寸设置成1。
# 多层全连接神经网络实现
class MNIST(fluid.dygraph.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义两层全连接隐含层,输出维度是10,激活函数为sigmoid
self.fc1 = Linear(input_dim=784, output_dim=10, act='sigmoid') # 隐含层节点为10,可根据任务调整
self.fc2 = Linear(input_dim=10, output_dim=10, act='sigmoid')
# 定义一层全连接输出层,输出维度是1,不使用激活函数
self.fc3 = Linear(input_dim=10, output_dim=1, act=None)
# 定义网络的前向计算
def forward(self, inputs, label=None):
inputs = fluid.layers.reshape(inputs, [inputs.shape[0], 784])
outputs1 = self.fc1(inputs)
outputs2 = self.fc2(outputs1)
outputs_final = self.fc3(outputs2)
return outputs_final
#网络结构部分之后的代码,保持不变
with fluid.dygraph.guard():
model = MNIST()
model.train()
#调用加载数据的函数,获得MNIST训练数据集
train_loader = load_data('train')
# 使用SGD优化器,learning_rate设置为0.01
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())
# 训练5轮
EPOCH_NUM = 5
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
#前向计算的过程
predict = model(image)
#计算损失,取一个批次样本损失的平均值
loss = fluid.layers.square_error_cost(predict, label)
avg_loss = fluid.layers.mean(loss)
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.minimize(avg_loss)
model.clear_gradients()
#保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')
loading mnist dataset from ./work/mnist.json.gz ......
epoch: 0, batch: 0, loss is: [20.577711]
epoch: 0, batch: 200, loss is: [6.238881]
epoch: 0, batch: 400, loss is: [4.0118523]
epoch: 1, batch: 0, loss is: [4.115336]
epoch: 1, batch: 200, loss is: [3.618446]
epoch: 1, batch: 400, loss is: [2.9577625]
epoch: 2, batch: 0, loss is: [3.0763488]
epoch: 2, batch: 200, loss is: [2.8786504]
epoch: 2, batch: 400, loss is: [2.62011]
epoch: 3, batch: 0, loss is: [2.8786814]
epoch: 3, batch: 200, loss is: [2.98603]
epoch: 3, batch: 400, loss is: [1.5560942]
epoch: 4, batch: 0, loss is: [2.467195]
epoch: 4, batch: 200, loss is: [2.6384313]
epoch: 4, batch: 400, loss is: [2.914253]
卷积神经网络
虽然使用经典的全连接神经网络可以提升一定的准确率,但对于计算机视觉问题,效果最好的模型仍然是卷积神经网络。卷积神经网络针对视觉问题的特点进行了网络结构优化,更适合处理视觉问题。
卷积神经网络由多个卷积层和池化层组成。
- 卷积层负责对输入进行扫描,以生成更抽象的特征表示
- 池化层对这些特征表示进行过滤,保留最关键的特征信息
# 多层卷积神经网络实现
class MNIST(fluid.dygraph.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义卷积层,输出特征通道num_filters设置为20,卷积核的大小filter_size为5,卷积步长stride=1,padding=2
# 激活函数使用relu
self.conv1 = Conv2D(num_channels=1, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')
# 定义池化层,池化核pool_size=2,池化步长为2,选择最大池化方式
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 定义卷积层,输出特征通道num_filters设置为20,卷积核的大小filter_size为5,卷积步长stride=1,padding=2
self.conv2 = Conv2D(num_channels=20, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')
# 定义池化层,池化核pool_size=2,池化步长为2,选择最大池化方式
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 定义一层全连接层,输出维度是1,不使用激活函数
self.fc = Linear(input_dim=980, output_dim=1, act=None)
# 定义网络前向计算过程,卷积后紧接着使用池化层,最后使用全连接层计算最终输出
def forward(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc(x)
return x
训练定义好的卷积神经网络
#网络结构部分之后的代码,保持不变
with fluid.dygraph.guard():
model = MNIST()
model.train()
#调用加载数据的函数
train_loader = load_data('train')
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())
EPOCH_NUM = 5
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
#前向计算的过程
predict = model(image)
#计算损失,取一个批次样本损失的平均值
loss = fluid.layers.square_error_cost(predict, label)
avg_loss = fluid.layers.mean(loss)
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.minimize(avg_loss)
model.clear_gradients()
#保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')
loading mnist dataset from ./work/mnist.json.gz ......
epoch: 0, batch: 0, loss is: [16.622307]
epoch: 0, batch: 200, loss is: [9.118264]
epoch: 0, batch: 400, loss is: [3.0645652]
epoch: 1, batch: 0, loss is: [3.457281]
epoch: 1, batch: 200, loss is: [2.7692409]
epoch: 1, batch: 400, loss is: [3.4607027]
epoch: 2, batch: 0, loss is: [2.5049503]
epoch: 2, batch: 200, loss is: [2.5498424]
epoch: 2, batch: 400, loss is: [2.0046785]
epoch: 3, batch: 0, loss is: [2.6352122]
epoch: 3, batch: 200, loss is: [2.4676642]
epoch: 3, batch: 400, loss is: [2.8928246]
epoch: 4, batch: 0, loss is: [1.9499339]
epoch: 4, batch: 200, loss is: [2.311511]
epoch: 4, batch: 400, loss is: [2.3005846]
二、【手写数字识别】之损失函数
损失函数是模型优化的目标,用于在众多的参数取值中,识别最理想的取值。损失函数的计算在训练过程的代码中,每一轮模型训练的过程都相同,分如下三步:
- 先根据输入数据正向计算预测输出。
- 再根据预测值和真实值计算损失。
- 最后根据损失反向传播梯度并更新参数。
那么,什么是分类任务的合理输出呢?分类任务本质上是“某种特征组合下的分类概率”,下面以一个简单案例说明,如 图2 所示。
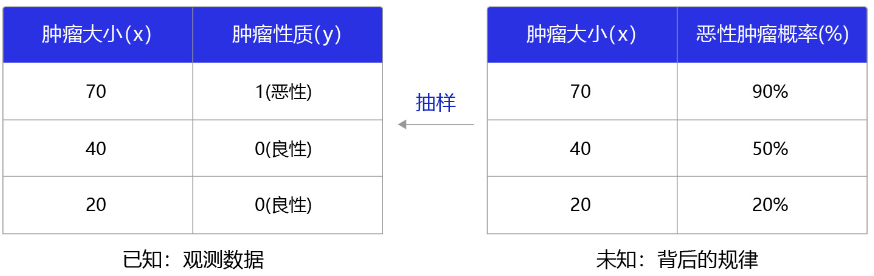
图2:观测数据和背后规律之间的关系
在本案例中,医生根据肿瘤大小作为肿瘤性质的参考判断(判断的因素有很多,肿瘤大小只是其中之一),那么我们观测到该模型判断的结果是和的标签(1为恶性,0为良性)。而这个数据背后的规律是不同大小的肿瘤,属于恶性肿瘤的概率。观测数据是真实规律抽样下的结果,分类模型应该拟合这个真实规律,输出属于该分类标签的概率。
Softmax函数
如果模型能输出10个标签的概率,对应真实标签的概率输出尽可能接近100%,而其他标签的概率输出尽可能接近0%,且所有输出概率之和为1。这是一种更合理的假设!与此对应,真实的标签值可以转变成一个10维度的one-hot向量,在对应数字的位置上为1,其余位置为0,比如标签“6”可以转变成[0,0,0,0,0,0,1,0,0,0]。
为了实现上述思路,需要引入Softmax函数,它可以将原始输出转变成对应标签的概率,公式如下,其中是标签类别个数。
从公式的形式可见,每个输出的范围均在0~1之间,且所有输出之和等于1,这是变换后可被解释成概率的基本前提。对应到代码上,我们需要在网络定义部分修改输出层:self.fc = Linear(input_dim=10, output_dim=1, act='softmax'),即是对全连接层的输出加一个softmax运算。
图3 是一个三个标签的分类模型(三分类)使用的softmax输出层,从中可见原始输出的三个数字3、1、-3,经过softmax层后转变成加和为1的三个概率值0.88、0.12、0。
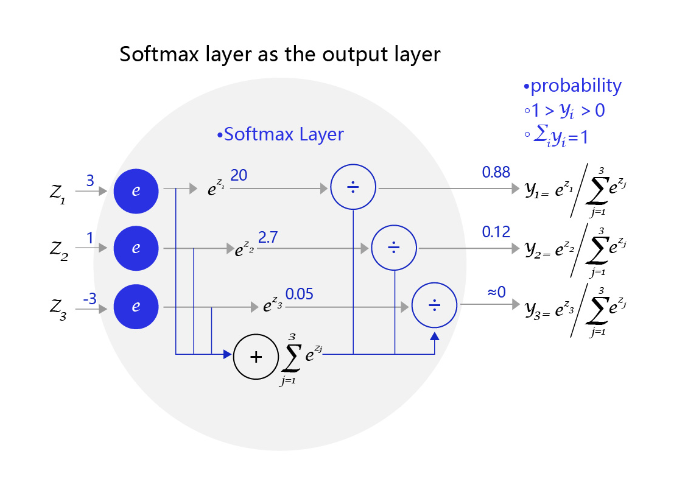
图3:网络输出层为softmax函数
上文解释了为何让分类模型的输出拟合概率的原因,但为何偏偏用softmax函数完成这个职能? 下面以二分类问题(只输出两个标签)进行探讨。
对于二分类问题,使用两个输出接入softmax作为输出层,等价于使用单一输出接入Sigmoid函数。如 图4 所示,利用两个标签的输出概率之和为1的条件,softmax输出0.6和0.4两个标签概率,从数学上等价于输出一个标签的概率0.6。
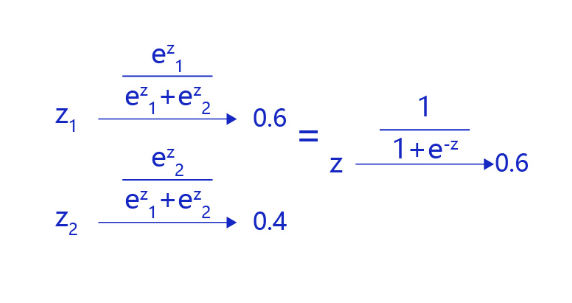
图4:对于二分类问题,等价于单一输出接入Sigmoid函数
在这种情况下,只有一层的模型为,为Sigmoid函数。模型预测为1的概率为,模型预测为0的概率为。
图5 是肿瘤大小和肿瘤性质的数据图。从图中可发现,往往尺寸越大的肿瘤几乎全部是恶性,尺寸极小的肿瘤几乎全部是良性。只有在中间区域,肿瘤的恶性概率会从0逐渐到1(绿色区域),这种数据的分布是符合多数现实问题的规律。如果我们直接线性拟合,相当于红色的直线,会发现直线的纵轴0-1的区域会拉的很长,而我们期望拟合曲线0-1的区域与真实的分类边界区域重合。那么,观察下Sigmoid的曲线趋势可以满足我们对这个问题的一切期望,它的概率变化会集中在一个边界区域,有助于模型提升边界区域的分辨率。
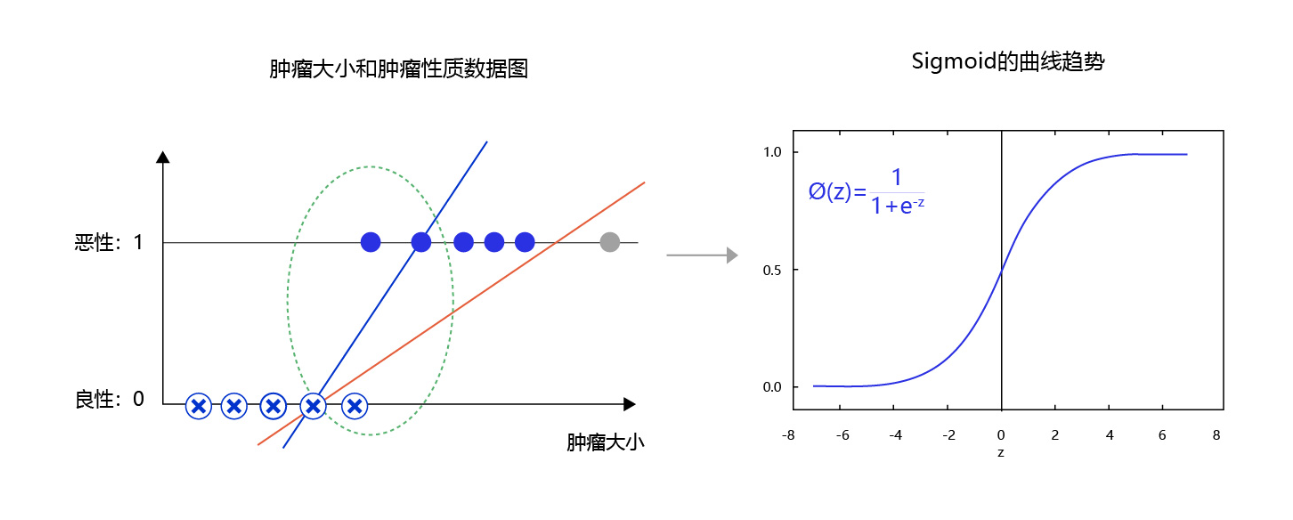
图5:使用sigmoid拟合输出可提高分类模型对边界的分辨率
这就类似于公共区域使用的带有恒温装置的热水器温度阀门,如 图6 所示。由于人体适应的水温在34度-42度之间,我们更期望阀门的水温条件集中在这个区域,而不是在0-100度之间线性分布。
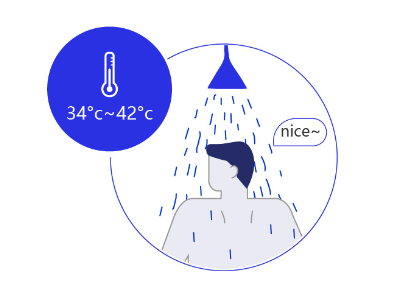
图6:热水器水温控制
交叉熵
在模型输出为分类标签的概率时,直接以标签和概率做比较也不够合理,人们更习惯使用交叉熵误差作为分类问题的损失衡量。
交叉熵损失函数的设计是基于最大似然思想:最大概率得到观察结果的假设是真的。如何理解呢?举个例子来说,如 图7 所示。有两个外形相同的盒子,甲盒中有99个白球,1个蓝球;乙盒中有99个蓝球,1个白球。一次试验取出了一个蓝球,请问这个球应该是从哪个盒子中取出的?
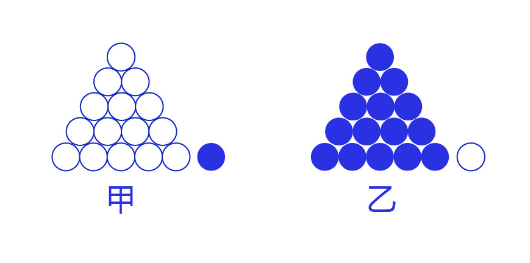
图7:体会最大似然的思想
相信大家简单思考后均会得出更可能是从乙盒中取出的,因为从乙盒中取出一个蓝球的概率更高,所以观察到一个蓝球更可能是从乙盒中取出的。是观测的数据,即蓝球白球;是模型,即甲盒乙盒。这就是贝叶斯公式所表达的思想:
依据贝叶斯公式,某二分类模型“生成”个训练样本的概率:
说明:
对于二分类问题,模型为,为Sigmoid函数。当=1,概率为;当=0,概率为。
经过公式推导,使得上述概率最大等价于最小化交叉熵,得到交叉熵的损失函数。交叉熵的公式如下:
其中,表示以为底数的自然对数。代表模型输出,代表各个标签。中只有正确解的标签为1,其余均为0(one-hot表示)。
因此,交叉熵只计算对应着“正确解”标签的输出的自然对数。比如,假设正确标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差是;若“2”对应的输出是0.1,则交叉熵误差为。由此可见,交叉熵误差的值是由正确标签所对应的输出结果决定的。
自然对数的函数曲线可由如下代码实现。
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0.01,1,0.01)
y = np.log(x)
plt.title("y=log(x)")
plt.xlabel("x")
plt.ylabel("y")
plt.plot(x,y)
plt.show()
plt.figure()

如自然对数的图形所示,当等于1时,为0;随着向0靠近,逐渐变小。因此,“正确解”标签对应的输出越大,交叉熵的值越接近0;当输出为1时,交叉熵误差为0。反之,如果“正确解”标签对应的输出越小,则交叉熵的值越大。
交叉熵的代码实现
在手写数字识别任务中,仅改动三行代码,就可以将在现有模型的损失函数替换成交叉熵(cross_entropy)。
- 在读取数据部分,将标签的类型设置成
int,体现它是一个标签而不是实数值(飞桨默认将标签处理成“int64”)。 - 在网络定义部分,将输出层改成“输出十个标签的概率”的模式。
- 在训练过程部分,将损失函数从均方误差换成交叉熵。
在数据处理部分,需要修改标签变量Label的格式,代码如下所示。
- 从:label = np.reshape(labels[i], [1]).astype(‘float32’)
- 到:label = np.reshape(labels[i], [1]).astype(‘int64’)
#修改标签数据的格式,从float32到int64
import os
import random
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear
import numpy as np
from PIL import Image
import gzip
import json
# 定义数据集读取器
def load_data(mode='train'):
# 数据文件
datafile = './work/mnist.json.gz'
print('loading mnist dataset from {} ......'.format(datafile))
data = json.load(gzip.open(datafile))
train_set, val_set, eval_set = data
# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLS
IMG_ROWS = 28
IMG_COLS = 28
if mode == 'train':
imgs = train_set[0]
labels = train_set[1]
elif mode == 'valid':
imgs = val_set[0]
labels = val_set[1]
elif mode == 'eval':
imgs = eval_set[0]
labels = eval_set[1]
imgs_length = len(imgs)
assert len(imgs) == len(labels), \
"length of train_imgs({}) should be the same as train_labels({})".format(
len(imgs), len(labels))
index_list = list(range(imgs_length))
# 读入数据时用到的batchsize
BATCHSIZE = 100
# 定义数据生成器
def data_generator():
if mode == 'train':
random.shuffle(index_list)
imgs_list = []
labels_list = []
for i in index_list:
img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.reshape(labels[i], [1]).astype('int64')
imgs_list.append(img)
labels_list.append(label)
if len(imgs_list) == BATCHSIZE:
yield np.array(imgs_list), np.array(labels_list)
imgs_list = []
labels_list = []
# 如果剩余数据的数目小于BATCHSIZE,
# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batch
if len(imgs_list) > 0:
yield np.array(imgs_list), np.array(labels_list)
return data_generator
在网络定义部分,需要修改输出层结构,代码如下所示。
- 从:self.fc = Linear(input_dim=980, output_dim=1, act=None)
- 到:self.fc = Linear(input_dim=980, output_dim=10, act=‘softmax’)
# 定义模型结构
class MNIST(fluid.dygraph.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义一个卷积层,使用relu激活函数
self.conv1 = Conv2D(num_channels=1, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')
# 定义一个池化层,池化核为2,步长为2,使用最大池化方式
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 定义一个卷积层,使用relu激活函数
self.conv2 = Conv2D(num_channels=20, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')
# 定义一个池化层,池化核为2,步长为2,使用最大池化方式
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 定义一个全连接层,输出节点数为10
self.fc = Linear(input_dim=980, output_dim=10, act='softmax')
# 定义网络的前向计算过程
def forward(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = fluid.layers.reshape(x, [x.shape[0], 980])
x = self.fc(x)
return x
修改计算损失的函数,从均方误差(常用于回归问题)到交叉熵误差(常用于分类问题),代码如下所示。
- 从:loss = fluid.layers.square_error_cost(predict, label)
- 到:loss = fluid.layers.cross_entropy(predict, label)
#仅修改计算损失的函数,从均方误差(常用于回归问题)到交叉熵误差(常用于分类问题)
with fluid.dygraph.guard():
model = MNIST()
model.train()
#调用加载数据的函数
train_loader = load_data('train')
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())
EPOCH_NUM = 5
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据,变得更加简洁
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
#前向计算的过程
predict = model(image)
#计算损失,使用交叉熵损失函数,取一个批次样本损失的平均值
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss)
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.minimize(avg_loss)
model.clear_gradients()
#保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')
loading mnist dataset from ./work/mnist.json.gz ......
epoch: 0, batch: 0, loss is: [2.3634984]
epoch: 0, batch: 200, loss is: [0.38027003]
epoch: 0, batch: 400, loss is: [0.30602008]
epoch: 1, batch: 0, loss is: [0.1570825]
epoch: 1, batch: 200, loss is: [0.24927774]
epoch: 1, batch: 400, loss is: [0.28396288]
epoch: 2, batch: 0, loss is: [0.11362638]
epoch: 2, batch: 200, loss is: [0.24342634]
epoch: 2, batch: 400, loss is: [0.10399125]
epoch: 3, batch: 0, loss is: [0.15782693]
epoch: 3, batch: 200, loss is: [0.20173627]
epoch: 3, batch: 400, loss is: [0.18618341]
epoch: 4, batch: 0, loss is: [0.13703655]
epoch: 4, batch: 200, loss is: [0.11431722]
epoch: 4, batch: 400, loss is: [0.09789195]
虽然上述训练过程的损失明显比使用均方误差算法要小,但因为损失函数量纲的变化,我们无法从比较两个不同的Loss得出谁更加优秀。怎么解决这个问题呢?我们可以回归到问题的本质,谁的分类准确率更高来判断。在后面介绍完计算准确率和作图的内容后,读者可以自行测试采用不同损失函数下,模型准确率的高低。
至此,大家阅读论文中常见的一些分类任务模型图就清晰明了,如全连接神经网络、卷积神经网络,在模型的最后阶段,都是使用Softmax进行处理。
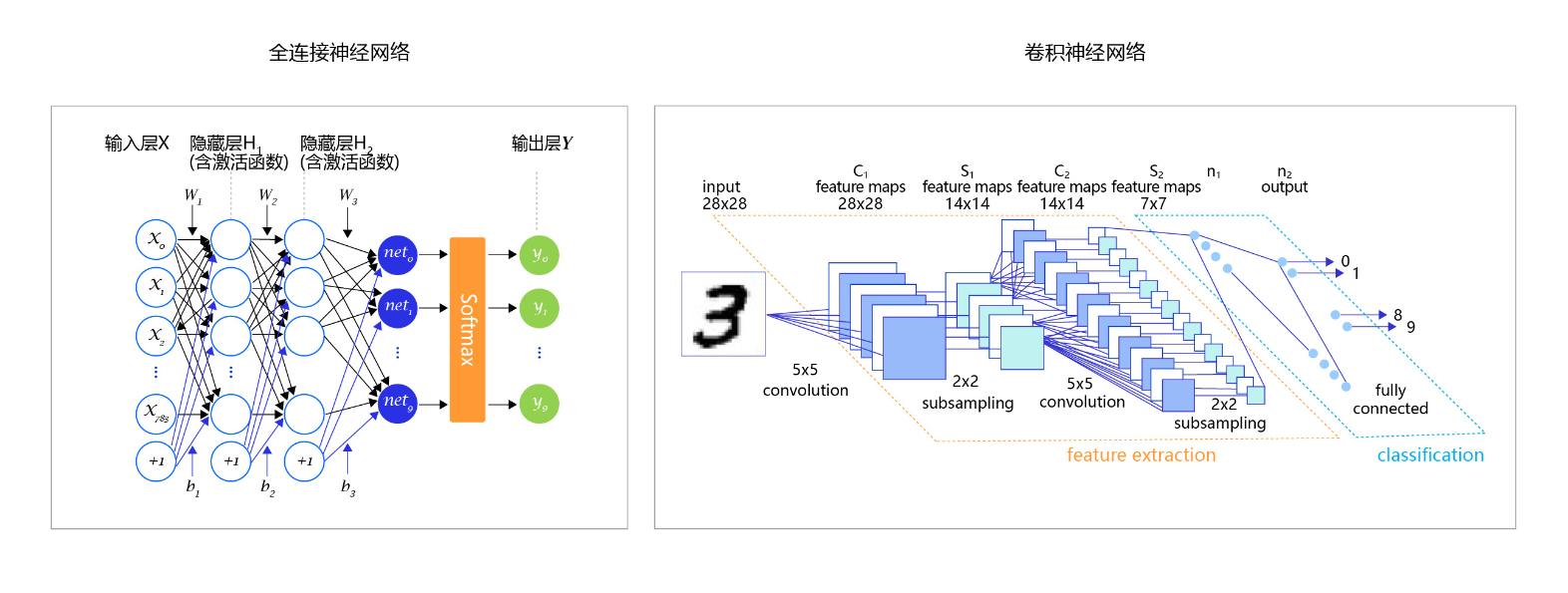
图8:常见的分类任务模型图
由于我们修改了模型的输出格式,因此使用模型做预测时的代码也需要做相应的调整。从模型输出10个标签的概率中选择最大的,将其标签编号输出。
# 读取一张本地的样例图片,转变成模型输入的格式
def load_image(img_path):
# 从img_path中读取图像,并转为灰度图
im = Image.open(img_path).convert('L')
im.show()
im = im.resize((28, 28), Image.ANTIALIAS)
im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)
# 图像归一化
im = 1.0 - im / 255.
return im
# 定义预测过程
with fluid.dygraph.guard():
model = MNIST()
params_file_path = 'mnist'
img_path = './work/example_0.jpg'
# 加载模型参数
model_dict, _ = fluid.load_dygraph("mnist")
model.load_dict(model_dict)
model.eval()
tensor_img = load_image(img_path)
#模型反馈10个分类标签的对应概率
results = model(fluid.dygraph.to_variable(tensor_img))
#取概率最大的标签作为预测输出
lab = np.argsort(results.numpy())
print("本次预测的数字是: ", lab[0][-1])
本次预测的数字是: 0
三、【手写数字识别】之优化算法
探讨在手写数字识别任务中,使得损失达到最小的参数取值的实现方法
设置学习率
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。学习率和深度学习任务类型有关,合适的学习率往往需要大量的实验和调参经验。探索学习率最优值时需要注意如下两点:
- 学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如 图2 左图所示。
- 学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,如 图2 右图所示。
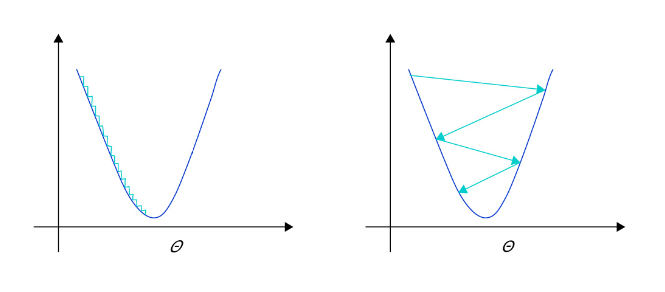
图2: 不同学习率(步长过小/过大)的示意图
在训练前,我们往往不清楚一个特定问题设置成怎样的学习率是合理的,因此在训练时可以尝试调小或调大,通过观察Loss下降的情况判断合理的学习率,设置学习率的代码如下所示。
#仅优化算法的设置有所差别
with fluid.dygraph.guard():
model = MNIST()
model.train()
#调用加载数据的函数
train_loader = load_data('train')
#设置不同初始学习率
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())
# optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001, parameter_list=model.parameters())
# optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.1, parameter_list=model.parameters())
EPOCH_NUM = 5
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据,变得更加简洁
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
#前向计算的过程
predict = model(image)
#计算损失,取一个批次样本损失的平均值
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss)
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.minimize(avg_loss)
model.clear_gradients()
#保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')
loading mnist dataset from ./work/mnist.json.gz ......
epoch: 0, batch: 0, loss is: [2.5479224]
epoch: 0, batch: 200, loss is: [0.51583934]
epoch: 0, batch: 400, loss is: [0.3206303]
epoch: 1, batch: 0, loss is: [0.2574886]
epoch: 1, batch: 200, loss is: [0.33207777]
epoch: 1, batch: 400, loss is: [0.2047088]
epoch: 2, batch: 0, loss is: [0.10459759]
epoch: 2, batch: 200, loss is: [0.14488357]
epoch: 2, batch: 400, loss is: [0.16438884]
epoch: 3, batch: 0, loss is: [0.22483312]
epoch: 3, batch: 200, loss is: [0.11302722]
epoch: 3, batch: 400, loss is: [0.11553524]
epoch: 4, batch: 0, loss is: [0.12319741]
epoch: 4, batch: 200, loss is: [0.07355891]
epoch: 4, batch: 400, loss is: [0.08584274]
学习率的主流优化算法
学习率是优化器的一个参数,调整学习率看似是一件非常麻烦的事情,需要不断的调整步长,观察训练时间和Loss的变化。经过研究员的不断的实验,当前已经形成了四种比较成熟的优化算法:SGD、Momentum、AdaGrad和Adam,效果如 图3 所示。
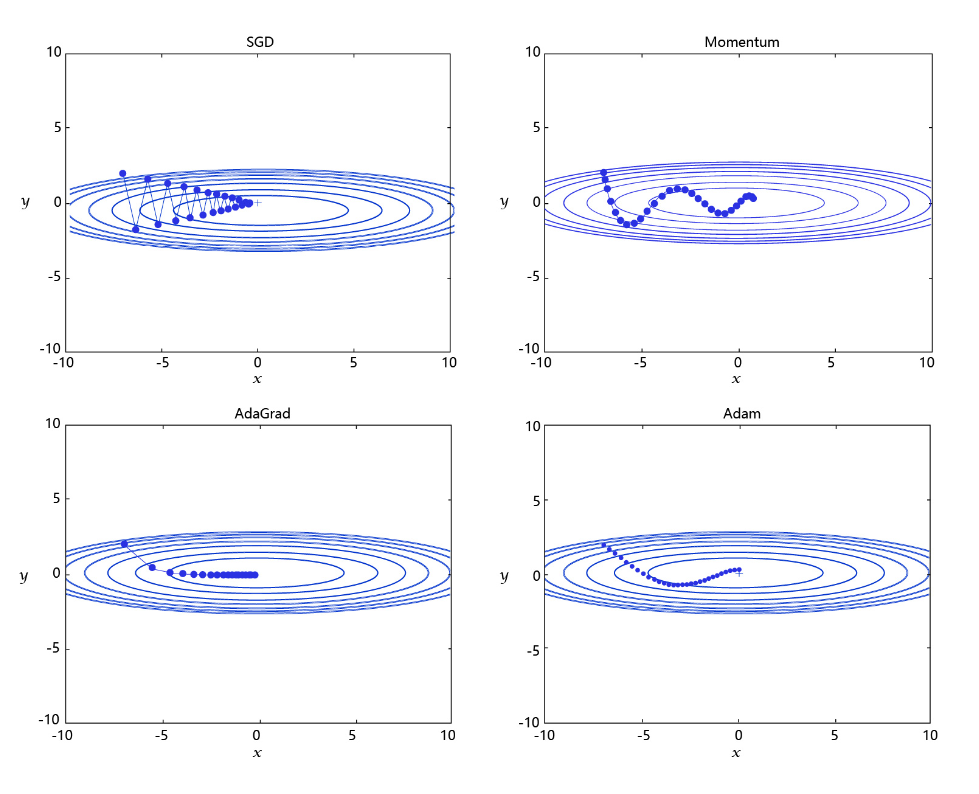
图3: 不同学习率算法效果示意图
每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
- AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。RMSProp是在AdaGrad基础上的改进,AdaGrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的梯度平均值,因而可以解决AdaGrad学习率急剧下降的问题。
- Adam: 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
说明:
每种优化算法均有更多的参数设置,详情可查阅飞桨的官方API文档。理论最合理的未必在具体案例中最有效,所以模型调参是很有必要的,最优的模型配置往往是在一定“理论”和“经验”的指导下实验出来的。
我们可以尝试选择不同的优化算法训练模型,观察训练时间和损失变化的情况,代码实现如下。
#仅优化算法的设置有所差别
with fluid.dygraph.guard():
model = MNIST()
model.train()
#调用加载数据的函数
train_loader = load_data('train')
#四种优化算法的设置方案,可以逐一尝试效果
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())
#optimizer = fluid.optimizer.MomentumOptimizer(learning_rate=0.01, momentum=0.9, parameter_list=model.parameters())
#optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.01, parameter_list=model.parameters())
#optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.01, parameter_list=model.parameters())
EPOCH_NUM = 5
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据,变得更加简洁
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
#前向计算的过程
predict = model(image)
#计算损失,取一个批次样本损失的平均值
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss)
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.minimize(avg_loss)
model.clear_gradients()
#保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')

