基于Confluent Mysql Binlog 数据遇到的问题以及解决方式
技术架构
Debezium + Confluent + Kafka + OSS/S3
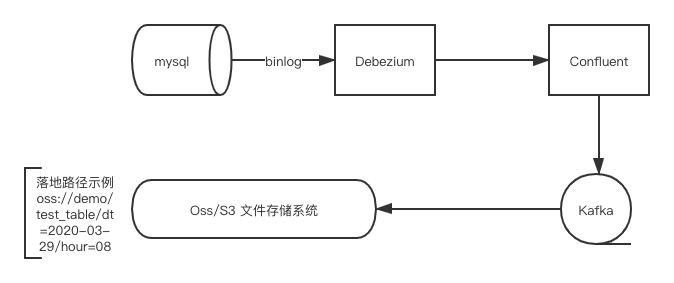
整体设计预期实现效果
Debezium 采集binlog 数据,通过Confluent Source 写入Kafka , 通过 Confluent S3 Sink / Oss Sink 写入相应文件存储系统,
按照小时级分区拆分文件夹做数据落地,hive 建立外部表映射相应时间分区实现数据读取以及后续数据ETL操作。
问题以及解决方法
问题描述:
需要考虑在数据采集过程中如果出现任意异常情况,数据采集会出现延迟。因此,写入文件存储依赖的时间戳相应的就不可以使用数据采集服务器时间。
如果使用会造成数据挤压阻塞,甚至前一天的数据落地到后一天的情况。
然而对于采集的数据表,并非所有数据表都会存在 create_time 与 update_time 两个重要的表记录时间戳。
Q:
如果保证相应真实时间产生的binlog数据落地到对应的分区,并且不受数据延迟的影响?
A:
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个transform 算子,可以抽取出binlog 中的元数据。
对于 0.10 版本的配置,可以抽取 table,version,connector,name,ts_ms,db,server_id,file,pos,row 等信息。
需要注意的是,不同版本之前的配置参数可能是不一样的,要去官网文档上确认写入和自己安装相对应版本的参数。
在 sink 端配置,需要把选择时间戳类型设置为
"timestamp.field" : "__ts_ms",
"timestamp.extractor":"RecordField"
参考文档地址:
https://debezium.io/documentation/reference/0.10/configuration/event-flattening.html
https://github.com/aliyun/kafka-connect-oss
https://docs.confluent.io/current/connect/kafka-connect-s3/index.html
问题描述:
对于数据表,会存在列删减增加的情况。
在sqoop 导入的情况下,存储数据格式为parquet格式,hive 建立外部映射表获取字段值依赖于字段顺序。
如果数据表操作列没有在尾部操作或者删除现有列,就会造成hive 查询结果列数据不对齐的问题。
Q:
如何保证在数据库表任意操作列的情况下保证 hive 最终读取的数据不会受到影响?
A:
binlog 数据采集数据格式采用json格式进行进行落地,hive 映射表使用json格式读取解决此问题。
在Kafka数据传输中,可以选择Arvo 格式或者Json 格式进行传输,可以自行选择,Debezium采集产出的数据格式支持json格式,使用Avro 格式需要另外启动Schema Register 服务。
参考文档地址:
https://www.infoq.cn/article/LOf0ukcu*dMtNaJdTxd5
https://github.com/rcongiu/Hive-JSON-Serde
问题描述:
业务数据库可能存在分库分表操作,如果每张表单独采集进行落地,每个分立的数据很繁琐并且使用上非常不方便。
Q:
如何把分库分表的事实表在数据采集传输中进行数据合并?
A:
基于Debezium的架构,一个Source 端只能对应一个mysql实例进行采集,对于同一实例上的分表情况,可以使用 Debezium Topic Routing 功能,
在采集过滤binlog时把相应需要采集的表按照正则匹配写入一个指定的topic中。
在分库的情况下,还需要在 sink 端 增加 RegexRouter transform算子进行topic 间的合并写入操作。
参考文档地址:
https://debezium.io/documentation/reference/0.10/configuration/topic-routing.html
https://docs.confluent.io/current/connect/transforms/regexrouter.html
sink端 merge topic 例子:
curl -X PUT http://localhost:8083/connectors/sqlserver-TEST-sink/config -H 'Content-Type: application/json' -H 'Accept: application/json' -d '{
"topics": "SQLSERVER-TEST-TABLE_TEST",
"topics.dir": "TABLE_TEST",
"s3.part.size": 5242880,
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"tasks.max": 3,
"schema.compatibility": "NONE",
"s3.region": "us-east-1",
"schema.generator.class": "io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator",
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
"format.class": "io.confluent.connect.s3.format.avro.AvroFormat",
"s3.bucket.name": "datalake",
"store.url": "http://smtproblem-minio:9000",
"flush.size": 1,
"transforms":"dropPrefix",
"transforms.dropPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.dropPrefix.regex":"SQLSERVER-TEST-(.*)",
"transforms.dropPrefix.replacement":"$1"
}'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号