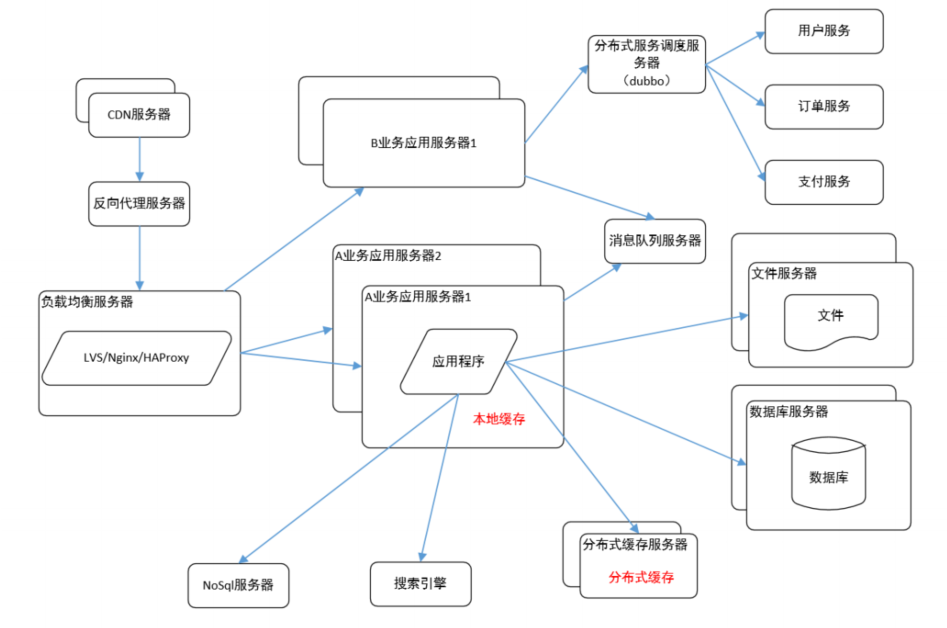
常用中间件分享
一、最开始的网站架构 最初的架构,应用程序、数据库、文件都部署在一台服务器上,
如图:

二、应用、数据、文件分离 随着业务的扩展,一台服务器已经不能满足性能需求,故将应
用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,
达到最佳的性能效果。

三、利用缓存改善网站性能 在硬件优化性能的同时,同时也通过软件进行性能优化,在大
部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,
大部分网站访问都遵循 28 原则(即 80%的访问请求,最终落在 20%的数据上),所以我们可以对
热点数据进行缓存,减少这些数据的访问路径,提高用户体验。

缓存实现常见的方式是本地缓存、分布式缓存。当然还有 CDN、反向代理等。本地缓存,
顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,OSCache 就是
常用的本地缓存组件。本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。
分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,
速度按理没有本地缓存快,常用的分布式缓存是 Memcached、Redis。缓存的主要作用,提高服务响应速度,减少数据库的访问压力,从而提高服务的性能提升。
有关redis常见问题:
1、缓存与数据库双写一致性问题是指在并发场景下,缓存和数据库之间的数据同步出现问题,导致数据的不一致性。解决这一问题,通常有以下几种策略:
- 先更新数据库,再更新缓存。这种策略简单,但在并发更新场景下可能导致脏数据被写入缓存,即数据库中的新数据还未写入缓存时,其他线程已经读取并可能使用了旧的缓存数据。
- 先删除缓存,再更新数据库。这种策略可以避免脏数据的产生,但在删除缓存和更新数据库之间,如果其他线程读取数据,可能会读取到旧数据并写入缓存。此外,如果删除缓存失败,也会导致数据不一致。
- 先更新数据库,再删除缓存。这种策略可以确保数据库的更新优先于缓存的更新,避免了脏数据的产生。但是,如果删除缓存失败,仍然可能导致数据不一致。
- 延时双删策略。即在删除缓存后,休眠一定时间(如1秒或200ms),再次删除缓存。这样可以确保在读请求结束前,写请求可以删除读请求造成的缓存脏数据。但这种方法会影响系统的吞吐量。
此外,还有基于消息队列的解决方案,通过将读请求和写请求串行化,可以保证数据的一致性,但这样做会大幅降低系统的吞吐量。在实际应用中,需要根据具体的业务场景和性能需求来选择合适的解决方案。
2、缓存击穿是指当缓存中某个热点数据过期了,在该热点数据重新载入缓存之前,有大量的查询请求穿过缓存,直接查询数据库。这种情况会导致数据库压力瞬间骤增,造成大量请求阻塞,甚至直接挂掉。
解决缓存击穿的方法也有两种,第一种是设置key永不过期;第二种是使用分布式锁,保证同一时刻只能有一个查询请求重新加载热点数据到缓存中,这样,其他的线程只需等待该线程运行完毕,即可重新从Redis中获取数据。
3、缓存雪崩是指当缓存中有大量的key在同一时刻过期,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉。针对大量key同时过期的情况,解决起来比较简单,只需要将每个key的过期时间打散即可,使它们的失效点尽可能均匀分布。
常用场景:
比如网站的用户个人设置信息、商品详情、热搜榜单这些都会使用 redis缓存数据
综合系统中使用redis的场景觉少,比如用户的主题设置信息是缓存在redis中的。
四、使用集群改善应用服务器性能 应用服务器作为网站的入口,会承担大量的请求,我
们往往通过应用服务器集群来分担请求数。应用服务器前面部署负载均衡服务器调度用户请求,
根据分发策略将请求分发到多个应用服务器节点。
目前常用的是Nginx,分发机制有下面几种:
1、轮询机制,即有10个服务器,第一个请求过来会分发到服务器1,第二个请求会分发到服务器2,10个服务器依次接受请求,通常对服务器性能差不多的服务会使用轮询机制;
2、针对多个服务器性能不一致的情况会采用权重的分发机制来处理,即硬件性能较高的服务器来处理更多的请求;
3、根据请求访问的ip,固定访问同一个服务器;
4、最少连接:下一个请求会被分配到连接数最少的服务器上。

五、随着用户量的增加,数据库成为最大的瓶颈,改善数据库性能常用的手段是进行读写分离以及分库分表。
读写分离顾名思义就是将数据库分为读库和写库,通过主备功能实现数据同步,主从数据不同步是读写分离常见问题,主从库之间需要通过日志的方式进行数据同步,如果此时用户的读请求交给从库去处理,一旦数据同步操作未完成,则用户此时读到的数据是旧数据,会导致用户获取数据不可靠,影响业务的正常运行和用户体验。链接是常见的解决思路,有兴趣的可以了解下https://blog.csdn.net/u013247401/article/details/113929942
分库分表则分为水平切分和垂直切分,水平切分则是对一个数据库特大的表进行拆分(比如bi中每日产生的bi数据量过大,会根据月份分表每月一张表),例如用户表。垂直切分则是根据业务不同来切分,如用户业务、商品业务相关的表放在不同的数据库中(比如车辆数据,会将车辆主要数据放在一张表中,其他次要信息存储在另一张表中)。

六、使用 CDN 和反向代理提高网站性能 假如我们的服务器都部署在成都的机房,对于四川
的用户来说访问是较快的,而对于北京的用户访问是较慢的,这是由于四川和北京分别属于电
信和联通的不同发达地区,北京用户访问需要通过互联路由器经过较长的路径才能访问到成都
的服务器,返回路径也一样,所以数据传输时间比较长。对于这种情况,常常使用 CDN 解决,
CDN 将数据内容缓存到运营商的机房,用户访问时先从最近的运营商获取数据,这样大大减少
了网络访问的路径。比较专业的 CDN 运营商有蓝汛、网宿。

而反向代理,则是部署在网站的机房,当用户请求达到时首先访问反向代理服务器,反向
代理服务器将缓存的数据返回给用户,如果没有没有缓存数据才会继续走应用服务器获取,也
减少了获取数据的成本,静态资源服务器、反向代理、负载均衡都可使用nginx。
正向代理:
正向代理是代理用户客户端,为客户端发送请求,对服务器隐藏自己的真实客户端。我们常接触的正向代理场景使用vpn访问内网、、使用抓包工具抓包。

反向代理:
是指以代理服务器来接收客户端的请求,然后将请求转发给内部网络上的服务器,将从服务器上得到的结果返回给客户端。

七、使用分布式文件系统 用户一天天增加,业务量越来越大,产生的文件越来越多,单
台的文件服务器已经不能满足需求。需要分布式的文件系统支撑。常用的分布式文件系统有
NFS。

八、使用 NoSql 和搜索引擎 对于海量数据的查询,我们使用 nosql 数据库加上搜索引擎可
以达到更好的性能。并不是所有的数据都要放在关系型数据库中。常用的 NOSQL 有 mongodb 和
redis,搜索引擎有 lucene。

九、将应用服务器进行业务拆分 随着业务进一步扩展,应用程序变得非常臃肿,这时我们
需要将应用程序进行业务拆分,如百度分为新闻、网页、图片等业务。每个业务应用负责相对
独立的业务运作。业务之间通过消息队列进行通信或者同享数据库来实现。

mq主要作用:异步、解耦、削峰
1. 流量削峰
举个例子,这里有一个订单系统处理用户下单的业务逻辑。这个系统的服务能力假设为 1S 处理1万次订单,那么正常来说,不超过1万次对它来说都没问题。但是,如果到了用户下单的高峰期,这时候的单量可能就要超过系统服务能力。
这时候可以加入 MQ,把1s内下的订单进行排队,分散在一段时间内处理,虽然说会导致有些用户会在几秒之后才能收到下单成功,但是比起不能下单还是要好很多了。
2. 应用解耦
现在有个电商应用,里面包含了好多个子系统:订单系统、库存系统、物流系统、支付系统等。
先看下耦合在一起的情况,当用户创建订单后,如果后面任何一个子系统出现了故障,都会造成用户的下单操作异常。
加上 MQ 后,订单系统的工作完成后,接下来的事情就转交给MQ了。MQ 会分配消息给其他的3个系统,直到3个系统执行完成。如果存在其中有不能完成的系统,队列会监督它继续完成。比如物流系统坏了,但是订单系统不受影响,用户感觉不出来有异常,依旧可以看到成功下单的提示。当物流系统恢复正常以后,继续处理订单信息即可,从而提升了整个系统的可用性。
3. 异步处理
在生产中,有些服务间的调用是异步的。A 调用 B,但是 B 需要花费一段时间来处理。没有 MQ 的时候通常这样处理:
-
A 轮询的调用 B的查询,看看结果是不是处理好了。
-
A 提供一个callback 回调接口,B 执行好了调用这个api接口通知 A。
加入 MQ 后,这时 A 再调用 B 后,只需要监听 B 处理完成的消息即可。当 B 处理完成后,会发送一条消息给 MQ,然后 MQ 会把消息转发给 A。所以,现在 A 既不用轮询 B,也不用提供回调api)
MQ 的组成
1. 角色
-
Broker:消息服务器,提供消息核心服务
-
Producer:消息生产者,业务的发起方,负责生产消息传输给broker。
-
Consumer:消息消费者,业务的处理方,负责从broker获取消息并进行业务逻辑处理。
-
Topic:主题,发布订阅模式下的消息统一汇集地,不同生产者向topic发送消息,由MQ服务器分发到不同的订阅者,实现消息的广播。
-
Queue:队列,点对点模式下,特定生产者向特定queue发送消息,消费者订阅特定的queue完成指定消息的接收。
-
Message:消息体,根据不同通信协议定义的固定格式进行编码的数据包,来封装业务数据,实现消息的传输。
2. MQ 消息模式
1)点对点模式
使用 queue 作为通信载体,消息生产者生产消息发送到 队列中,然后消息消费者从 队列 中取出并且消费消息。
-
消息被消费以后,队列中不再存储,所以消息消费者不可能消费到已经被消费的消息。
-
队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2)发布订阅模式
使用topic作为通信载体,1个生产者可以对应多个消费者。消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
就像你发了个朋友圈,你的朋友们都可以看到一样。
3.MQ 测试需要的关注点
对于生产者
-
生成的数据格式是否跟定义的一致
-
数据是否有成功推送到队列里
-
数据是否有成功推动到对应的 topic
-
推送失败时如何处理
-
重复推送同一条数据,如何处理
-
不同顺序推送消息,注意队列优先级
-
推消息耗时,队列容量达到上限,无法推送后如何处理
对于消费者
-
消费的消息是否来自订阅的 topic
-
消息被消费了,是否有清除
-
生产者推送过快,消费速度过慢(堵塞),会如何
-
无法消费没订阅的 topic 消息
-
生产者推送消息后,消费者接受到的消息内容跟生产者推的一致
-
如何处理重复消息,比如幂等
-
处理超时
-
消息处理失败
-
消费消息的优先级是否跟推的一致
-
消费消息耗时
-
消费者宕机,消息堆积,无人处理,会如何处理
-
是否能正常消费消息
对于队列
-
宕机恢复后,消息是否丢失
-
宕机预案,多久能恢复,如果无法恢复的预案
-
不同的消息格式,是否能正常识别及转发
十、搭建分布式服务 这时我们发现各个业务应用都会使用到一些基本的业务服务,例如用
户服务、订单服务、支付服务、安全服务,这些服务是支撑各业务应用的基本要素。我们将这
些服务抽取出来利用分布式服务框架搭建分布式服务。淘宝的 Dubbo 是一个不错的选择。
分布式是将一种业务拆分成多个子业务部署在多台服务器上,而集群就是将多台服务器组合在一起提供同一种服务