

如何设计一个关系型数据库
程序实例
存储管理 缓存机制 SQL解析 日志管理
权限划分 容灾机制 索引管理 锁模块
存储(文件系统)
索引模块
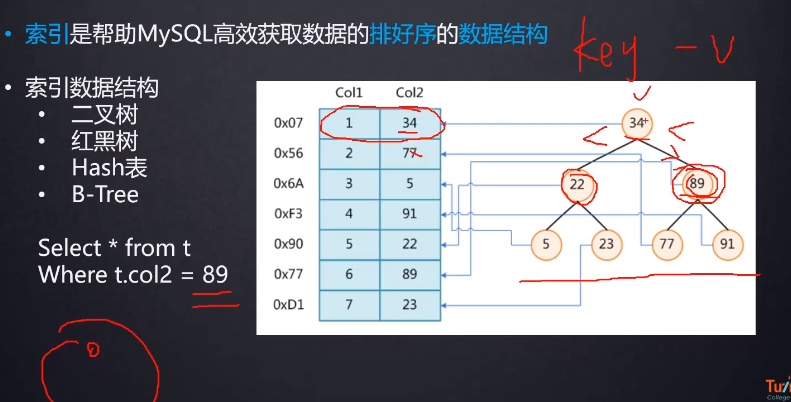
帮助MySQL高效获取数据的排好序的数据结构
表的数据存储在磁盘上 每一行记录在磁盘上随机分布的
索引结构为二叉查找树时,节点存放的是k-v对 k是存储的索引字段,v存放索引所在行的磁盘文件地址指针
常见问题
为什么要使用索引
什么样的信息能成为索引
索引的数据结构 二叉查找树 左孩子小于父节点,右孩子大于父节点 B树 B+树
密集索引和稀疏索引的区别
平衡二叉树:任意一个节点的左子树的高度均不超过1
JDK1.8以后HashMap底层链表优化成红黑树
红黑树:二叉平衡树 自动平衡
节点中存储更多的元素(索引) mysql设置16k
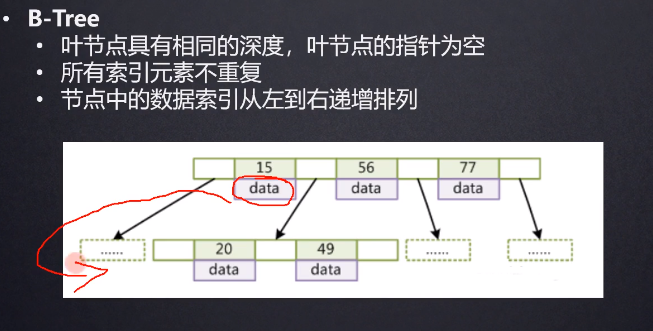
先将根节点一次性load到内存中
B-Tree:根节点至少包括两个孩子,树中每个节点最多含有m个孩子 m>=2,除根节点和叶节点外,其他每个节点至少有ceil(m/2)取上限个孩子,所有叶子节点位于同一层
让每个索引块尽可能地存储更多的信息 减少IO
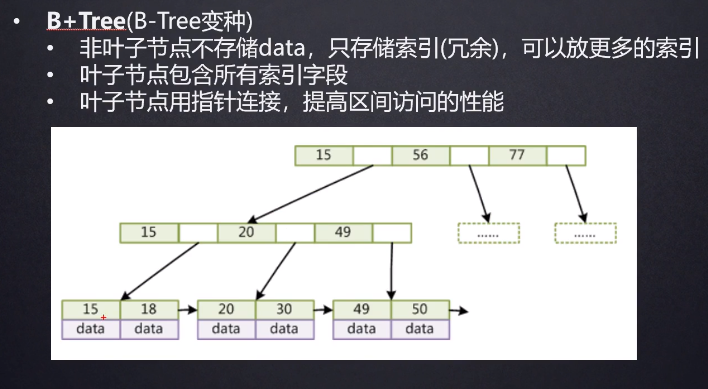
B+树的磁盘读写代价更低 内部结构没有指向关键字具体信息的指针,不存放数据只存放索引信息,其内部节点相对B树更小
B+树的查询效率更稳定
有利于对数据库的扫描
慢sql查询的优化
加索引
存储引擎形容数据表
MyISAM索引文件和数据文件是分离的
MYD存数据 MYI存索引
InnoDB存储引擎索引和数据在一起存储 聚集索引 叶节点包含了完整的数据记录 表数据文件本身就是按B+树组织的一个索引结构文件
InnoDB表为什么必须有主键,并且推荐使用整型的自增主键? 字符串比较大小比整型慢 整型存储空间小
RR事务隔离级别下,快照读有可能读到数据的历史版本
事务首次调用快照读 创建快照的时机决定了数据读取的版本
执行快照读select时 针对查询的数据创造read view来决定当前事务能看到哪个版本的数据
可见性算法:将要修改的数据的DB_TRX_ID取出与系统其他活跃事务ID对比,大于等于时取处undolock
转载-----
按照可重复读的定义,一个事务启动的时候,能够看到所有已经提交的事务结果。但是之后,这个事务执行期间,其他事务的更新对它不可见。因此,一个事务只需要在启动的时候声明说,“以我启动的时刻为准,如果一个数据版本是在我启动之前生成的,就认;如果是我启动以后才生成的,我就不认,我必须要找到它的上一个版本”。当然,如果“上一个版本”也不可见,那就得继续往前找。还有,如果是这个事务自己更新的数据,它自己还是要认的。
在实现上, InnoDB 为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在“活跃”的所有事务 ID。活跃”指的就是,启动了但还没提交。 数组里面事务ID的最小值记为低水位,当前系统里面已经创建过的事务ID的最大值加1记为高水位。这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。
数据版本的可见性规则,就是基于数据的row trx_id和这个一致性视图的对比结果得到的。这个视图数组把所有的 row trx_id 分成了几种不同的情况。
简单总结一下,一个数据版本,对于一个事务视图来说,除了自己的更新总是可见以外,还有以下三种情况:
a) 版本未提交,不可见
b) 版本已提交,但是在视图创建后提交的,不可见
c) 版本已提交,并且是在视图创建之前提交的,可见
————————————————
版权声明:本文为CSDN博主「Heiky0214」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_32573109/article/details/98610368

 浙公网安备 33010602011771号
浙公网安备 33010602011771号