redis主从复制
Redis 主从复制
Redis主从结构
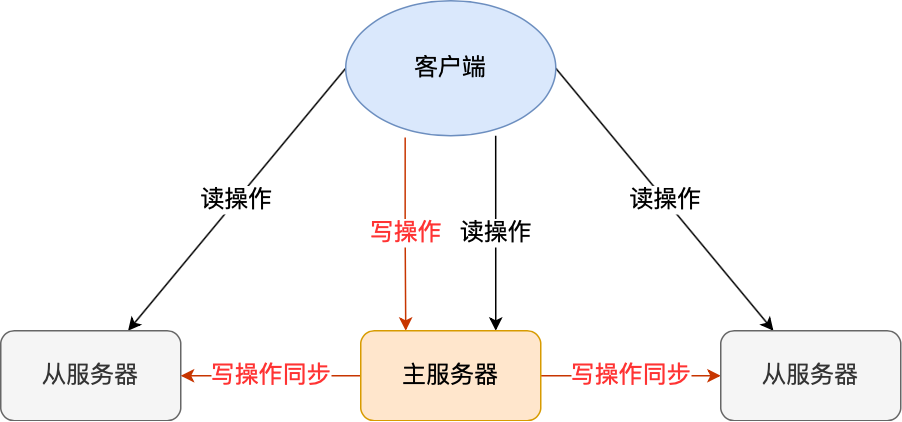
所有的数据修改只在主服务器上进行,然后将最新的数据同步给从服务器,这样就使得主从服务器的数据是一致的。
从连接主
从服务器请求连接主服务器
服务器 B 执行这条命令
replicaof <服务器 A 的 IP 地址> <服务器 A 的 Redis 端口号>
从服务器发送psync命令
psync runID offset
其中:
- runID: 每个 Redis 服务器在启动时都会自动生产一个随机的 ID 来唯一标识自己。当从服务器和主服务器第一次同步时,因为不知道主服务器的 run ID,所以将其设置为 "?"。
- offset: 表示复制进度,第一次连接为-1
主服务器返回复制请求
fullresync runID offset
- runID: 主服务器的 run ID
- offset: 主服务器的复制偏移量
从服务器接收到后会保存runID和offset
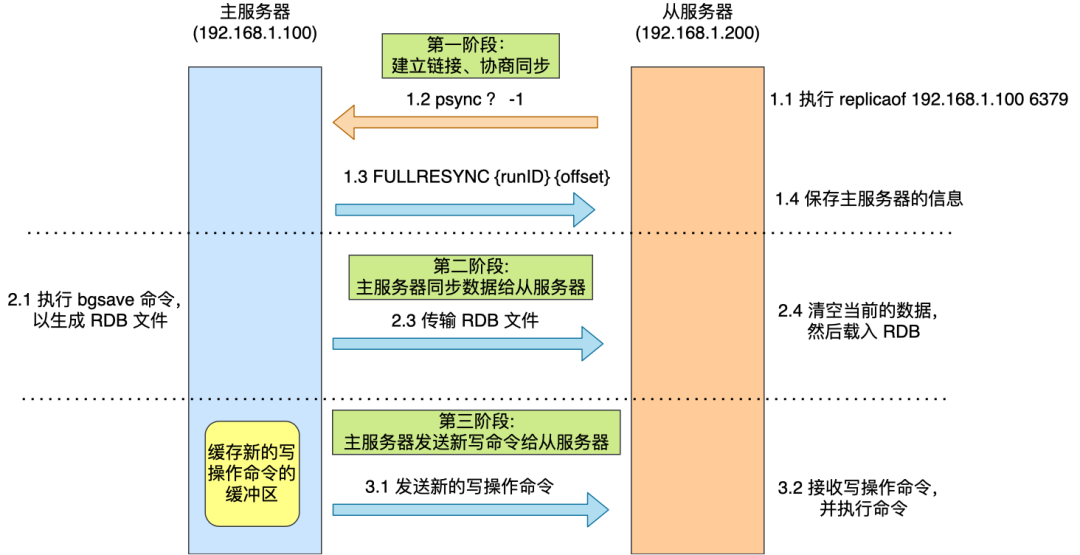
全量复制
全量复制出现在第一次连接和连接断开后重新连接时。
主服务器执行bgsave命令,fork一个子进程,将内存数据以rdb文件格式进行保存,然后发送给从服务器
注意三个时间间隙:
- 主服务器生成rdb文件时
- 主服务器发送rdb文件时
- 从服务器加载rdb文件时
在这三个时间段,写请求会记录到 replication buffer中,直到从服务器完成加载rdb文件到内存中,主服务器会将replication buffer缓存的写命令发送给从服务器,这样就保证了主从服务器的数据一致性。
命令传播
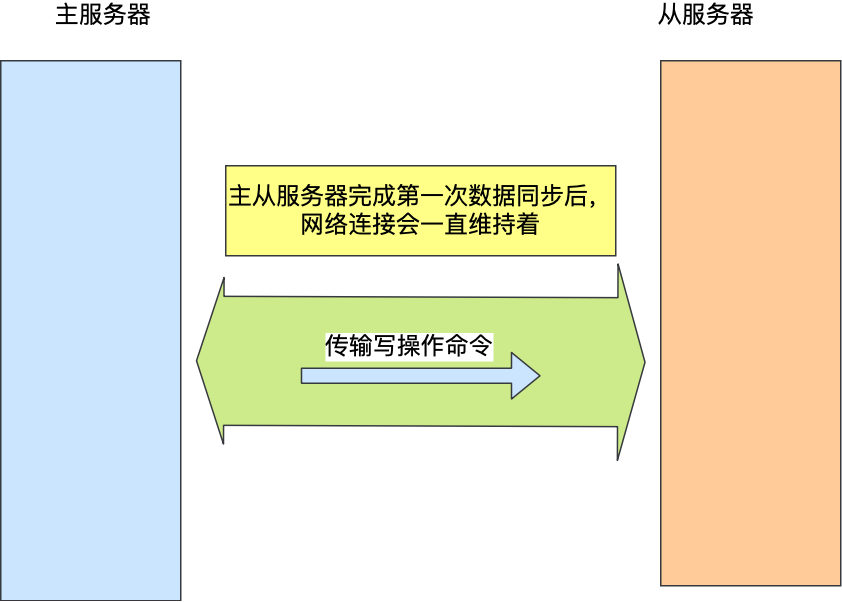
主从服务器连接会一直keep,用于发送写操作,属于长连接,叫做基于长连接的命令传播
目的是为了避免重复tcp连接造成的性能开销
增量复制
增量复制适用于主从连接建立后,网络波动导致断开,二者重新连接并进行数据同步
在2.8版本添加
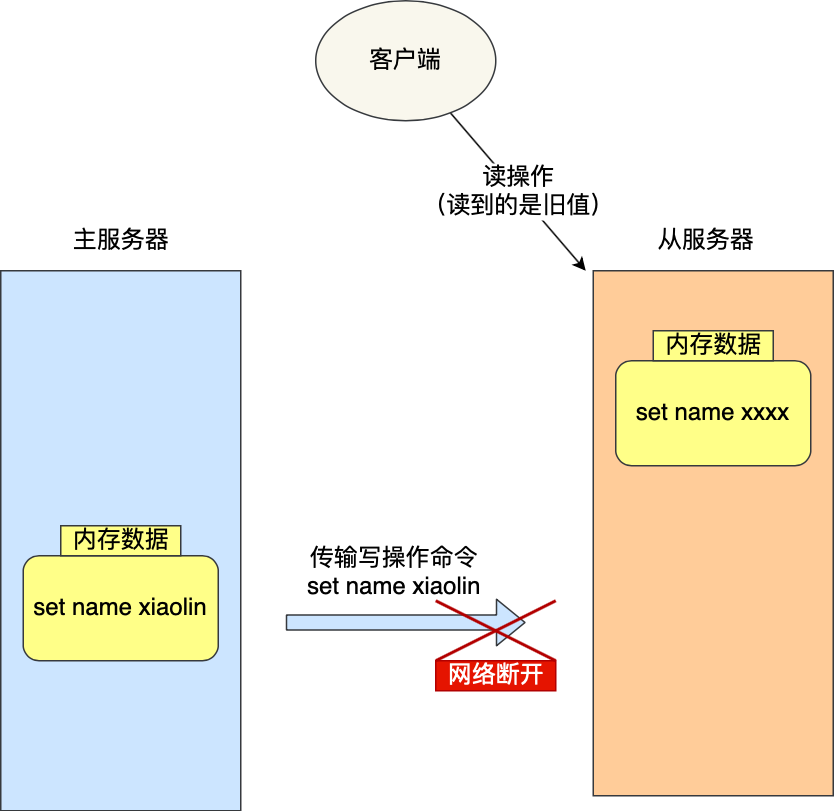
从服务器重新连接到主服务器后,会再次发送psync命令,但这次发送,runID和offset是已知的
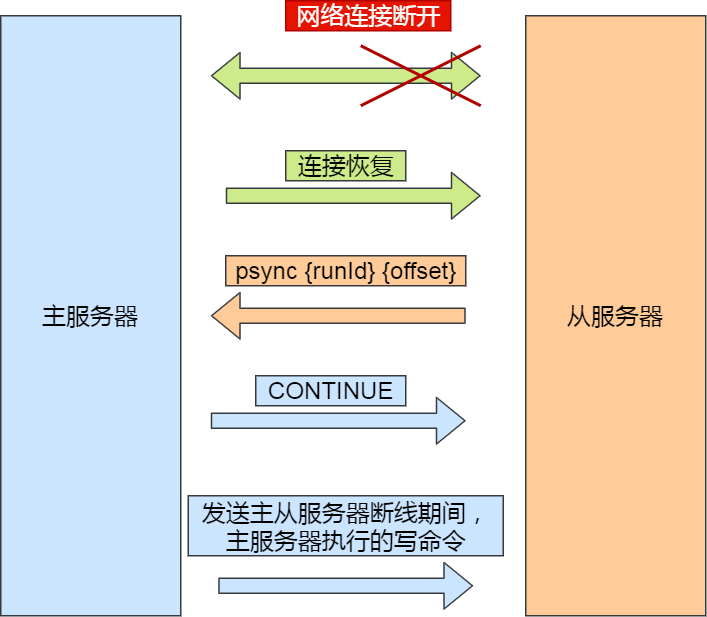
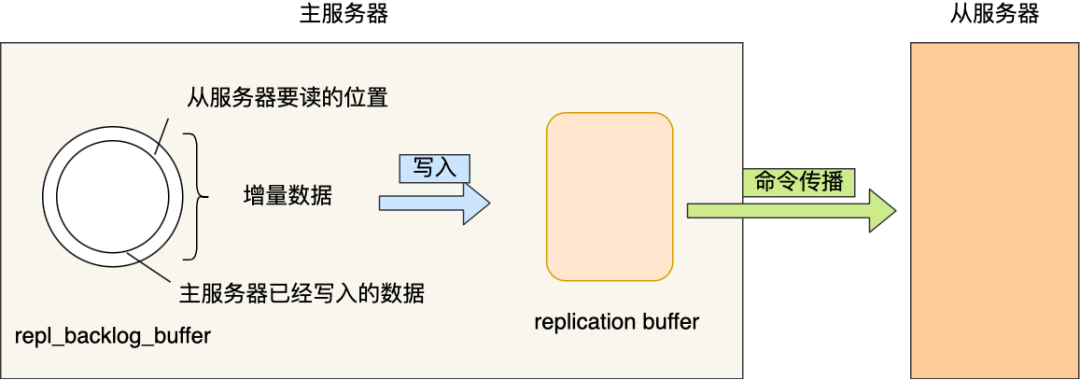
这里涉及到replication buffer,repl_backlog_buffer,replication offset
-
repl_backlog_buffer:这是一个环形缓冲区,一个主服务器只存在一个
repl_backlog_buffer,写命令在执行结束后会记录在repl_backlog_buffer
在buffer满时,会重新头部命令,保证最新的命令在buffer中 -
replication buffer: 在全量复制阶段和增量复制阶段都会出现,主节点会给每个新连接的从节点,分配一个 replication buffer,满了,会导致连接断开,删除缓存,从节点重新连接,重新开始全量复制
-
replication offset: 用于
repl_backlog_buffer偏移量记录
主服务器使用master_repl_offset来记录自己「写」到的位置,从服务器使用slave_repl_offset来记录自己「读」到的位置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号