02_05、数据类型的内置方法
不同的数据类型有不同的功能,通过调用其功能,更加便捷高效实现代码目的,这些功能调用就是靠数据类型的内置方法实现的
一、整型 int
1、类型转换
1.纯数字转换为整型,且只有纯数字能转换成整型
浮点不能转换成整型,否则报错
其他类型不能转换成整型,否则报错
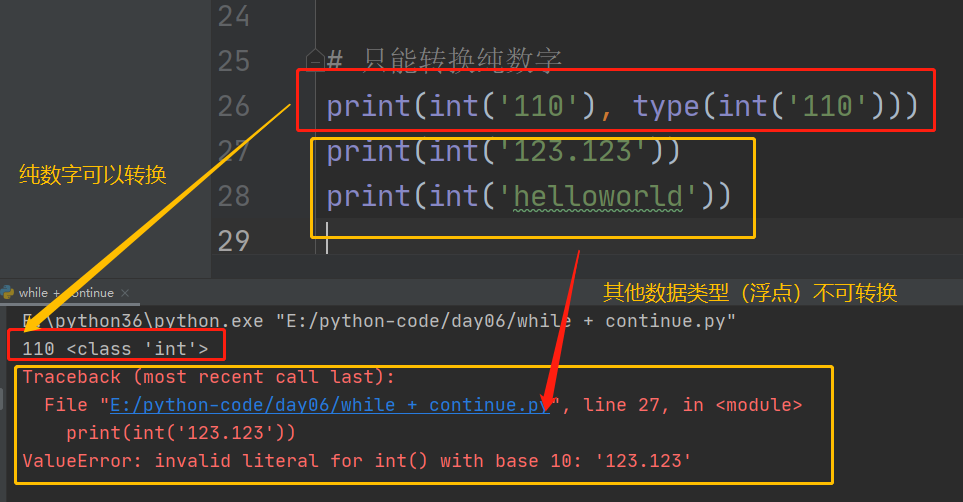
2.具体操作案例
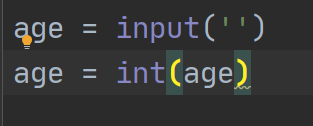
用户输入年龄为整型:
2、进制之间的转换
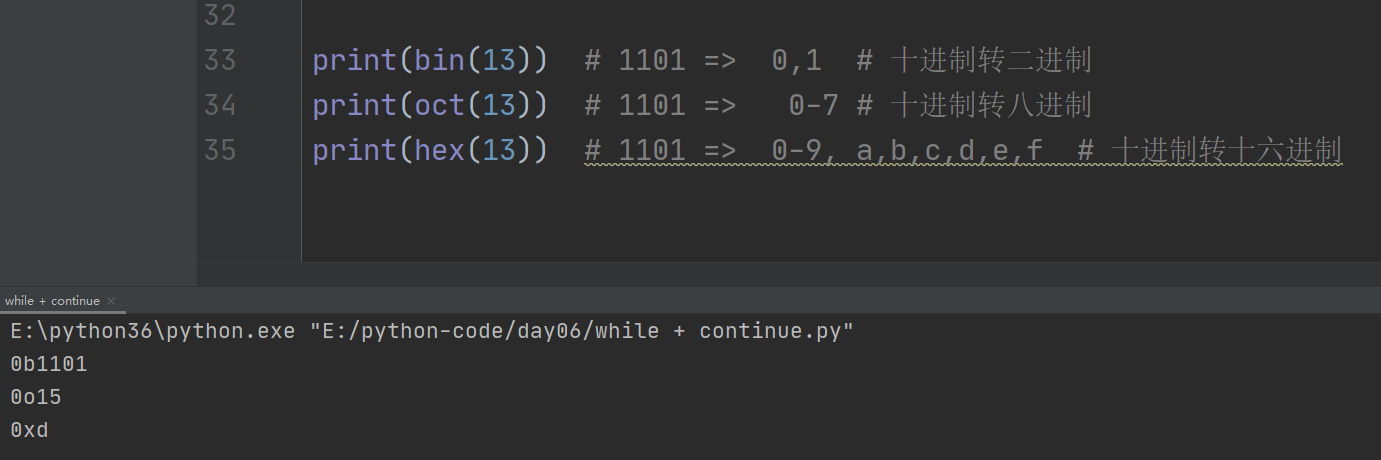
1、十进制转换成其他进制:
以十进制13为例
1.十进制转二进制:bin
print(bin(13)) 得出 0b1101
0b开头的代表二进制
2.十进制转八进制:oct
print(oct(13)) 得出 0o1101
0o开头的代表八进制
3.十进制转十六进制:hex
print(hex(13)) # 1101 => 0-9, a,b,c,d,e,f #
0x开头的代表十六进制
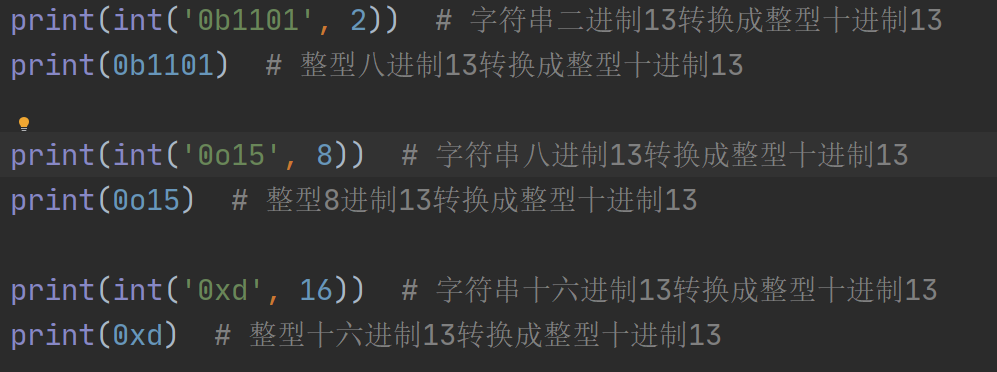
2.其他进制转十进制
3、扩展:
3.1 数学上十进制转二进制方法
除2取余,逆序排列
3.2 二进制转十进制
按权相加
二、浮点型
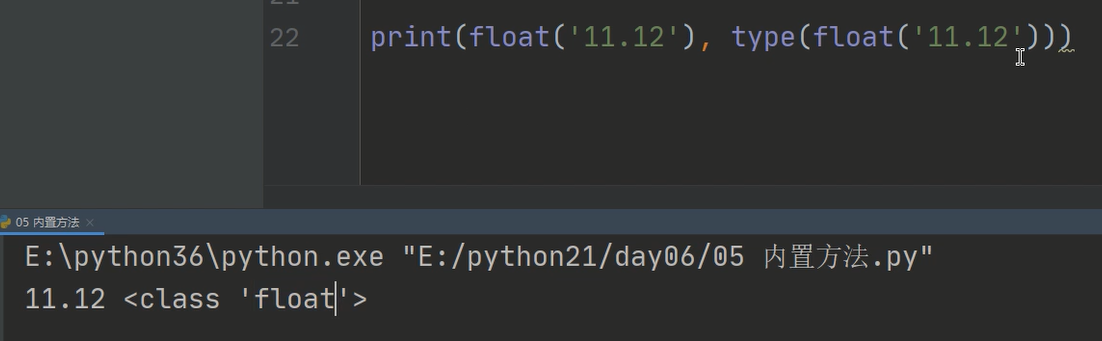
1、字符串类型转换成浮点类型
2、查看浮点类型
三、字符串
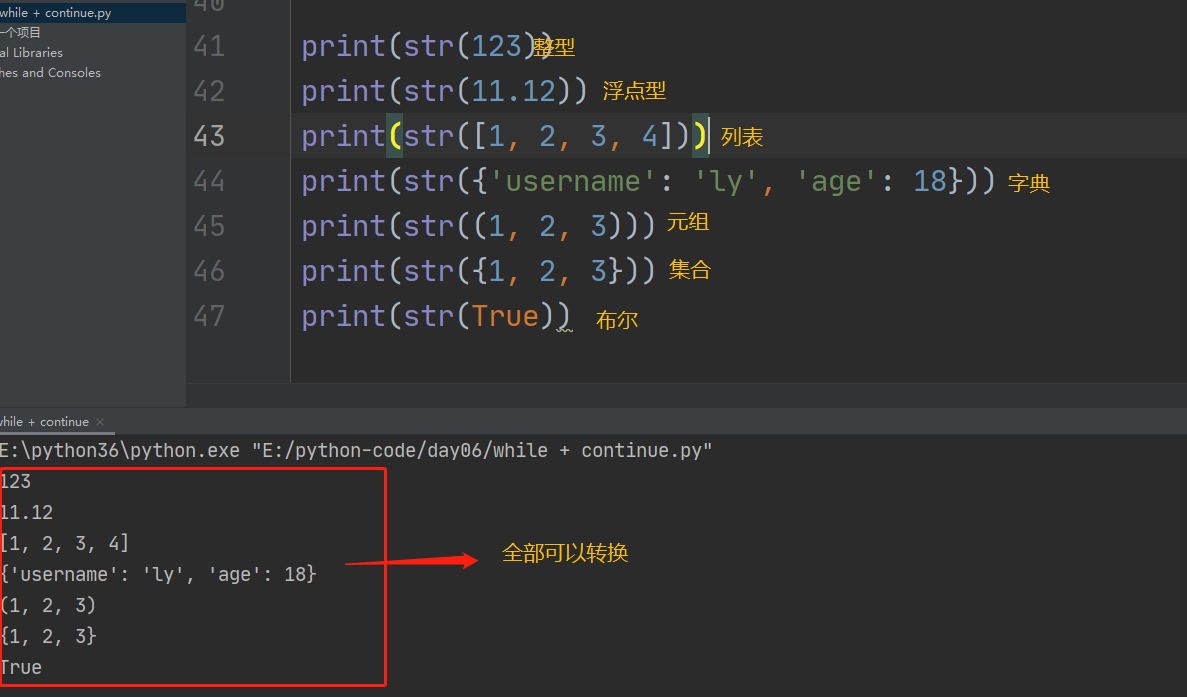
1、其他数据类型转为字符串
整型转换成字符串类型——值不变,数据类型转变
浮点型转换成字符串类型——值不变,数据类型转变
列表转换成字符串类型——值不变,数据类型转变
元组转换成字符串类型——值不变,数据类型转变
集合转换成字符串类型——值不变,数据类型转变
字典转换成字符串类型——值不变,数据类型转变
布尔转换成字符串类型——值不变,数据类型转变
2、支持索引取值 []
[]中括号内为索引值

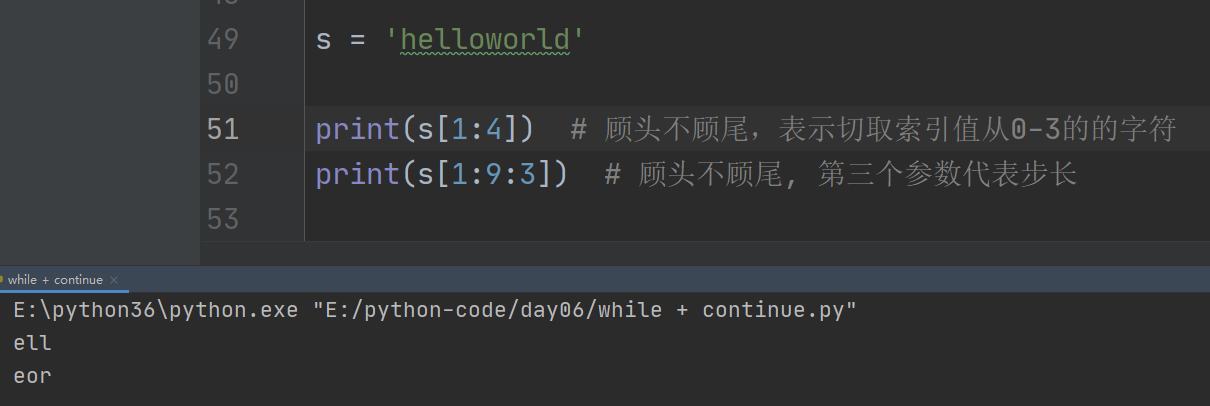
3、支持切片操作 []取值
[a:b]表示切取索引值为从a到(b-1)的字符,顾头不顾尾
[a:b:c]表示切取索引值为从a到(b-1)的字符,c表示步长,顾头不顾尾
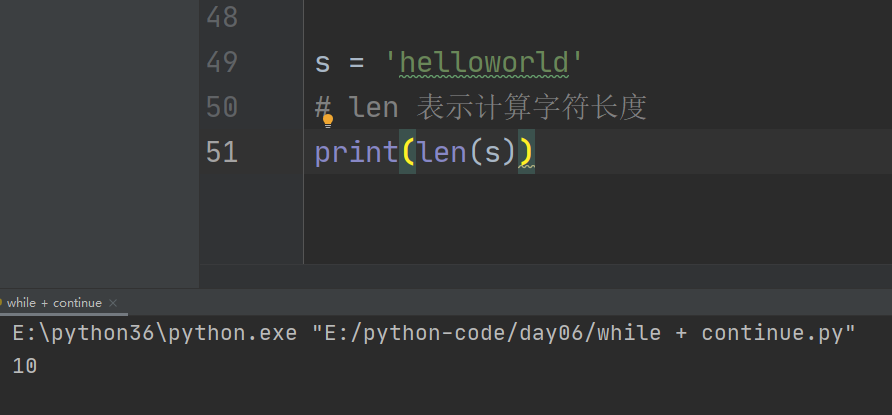
4、计算字符串的字符长度 len
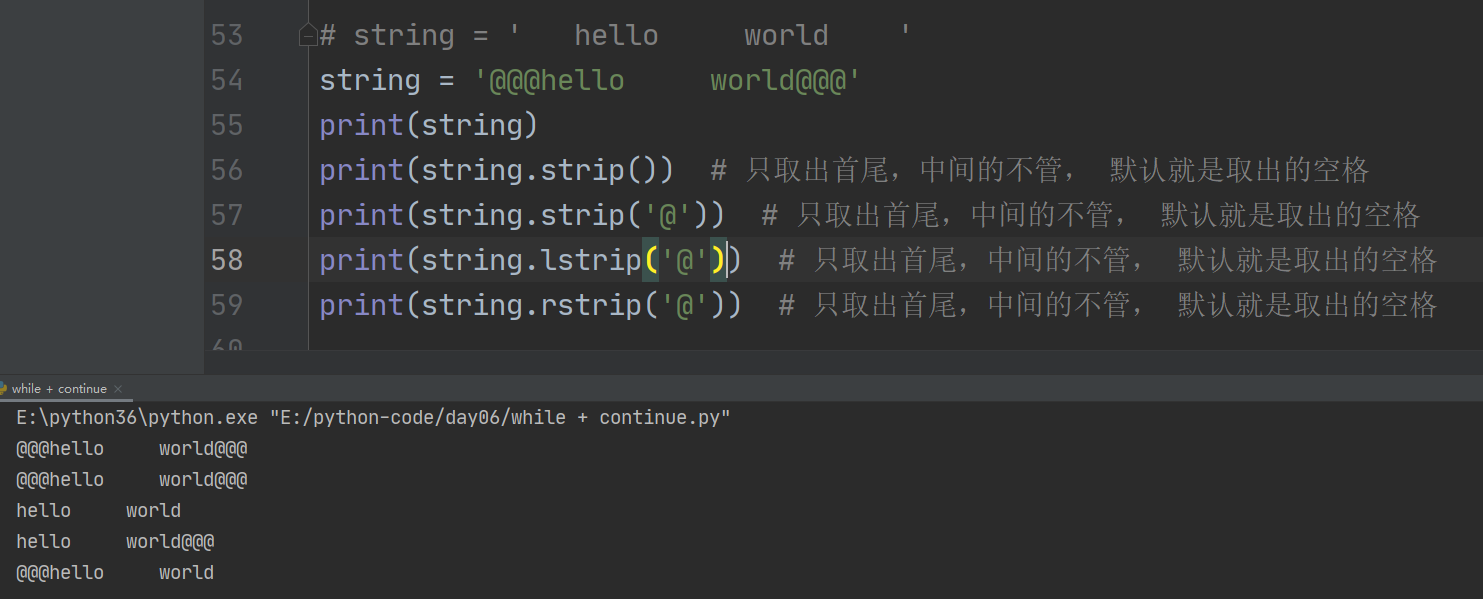
5、strip 去除左右两边指定字符
1、 字符串.strip() 只取出首尾,中间的不管, 默认就是取出的空格,否则去左边的括号内值
字符串.lstrip() 只取出左边,中间的不管, 默认就是取出的空格,否则去左边的括号内值
字符串.rstrip() 只取出右边,中间的不管, 默认就是取出的空格,否则去右边的括号内值
注意:()内必须是字符串类型或者None
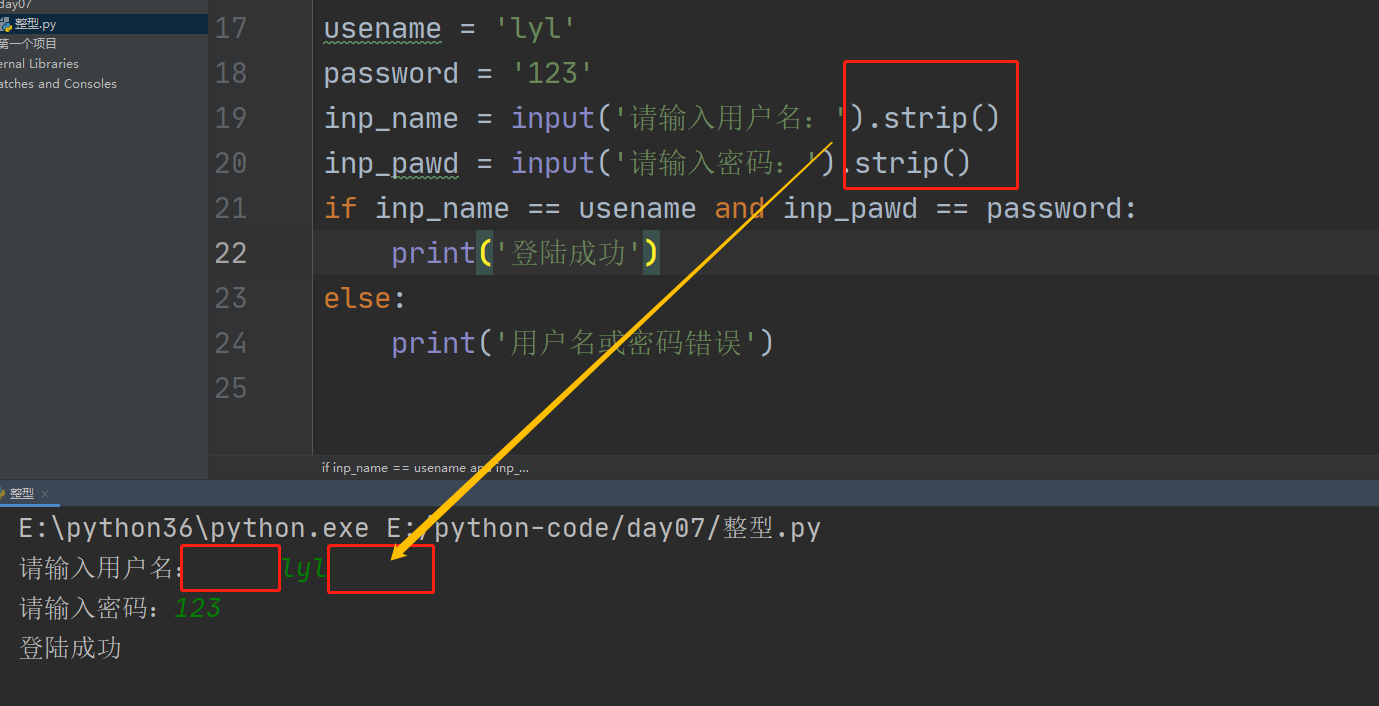
2、实际应用:防止用户在输入用户名或密码的时候误加空格,导致用户名或密码输入错误
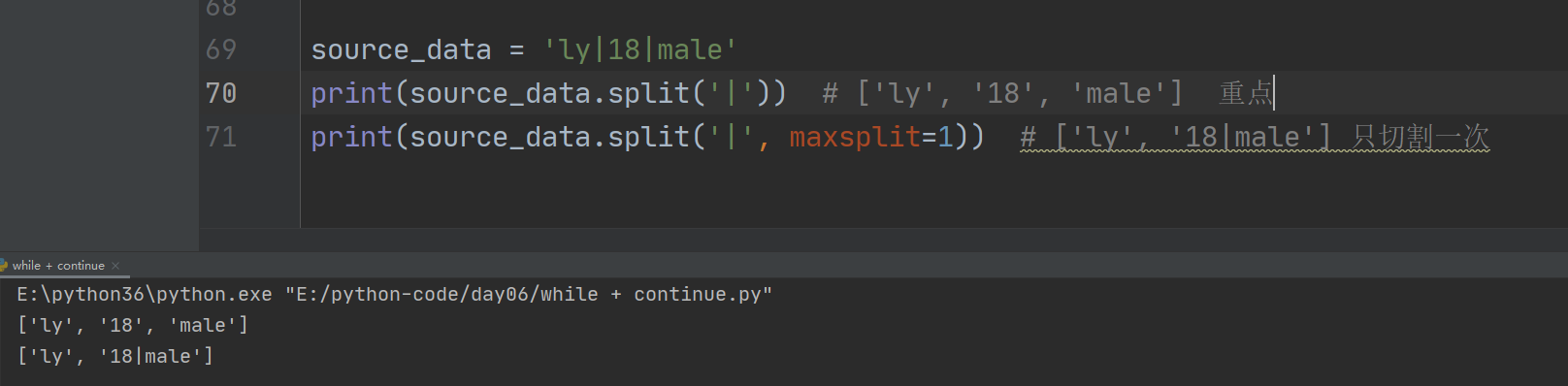
6、split 切割
字符串.split(''),把字符串自动从左往右切割成列表,以方便存取,默认按空格切
maxsplit=1) 只切割一次
rsplit ,把字符串自动从左往右切割成列表
实际应用:
把字符串按指定字符切割成列表/把字符串按指定分隔符转换成列表

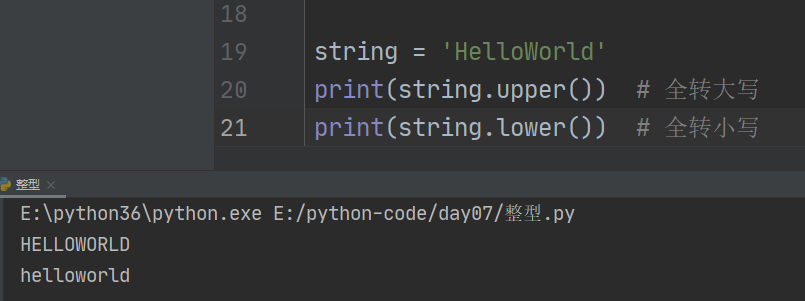
7、upper和lower
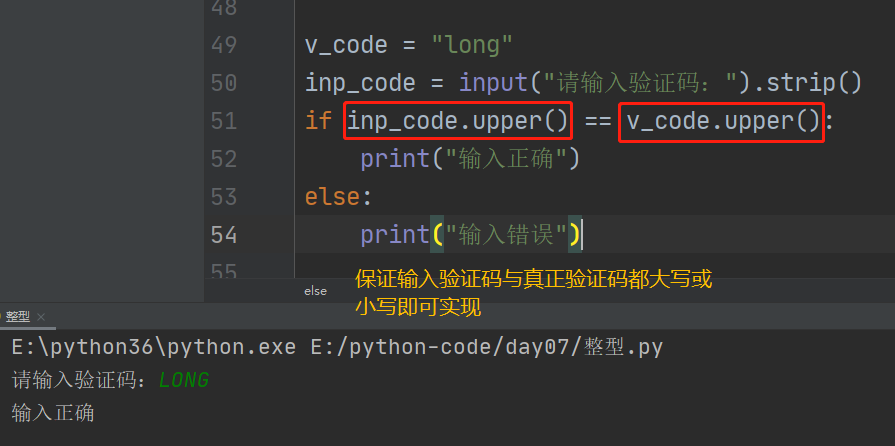
1、.upper() 字符串转为全大写
2、.lower() 字符串转为全小写
3.实际应用:验证码输入(大小写均可验证成功)
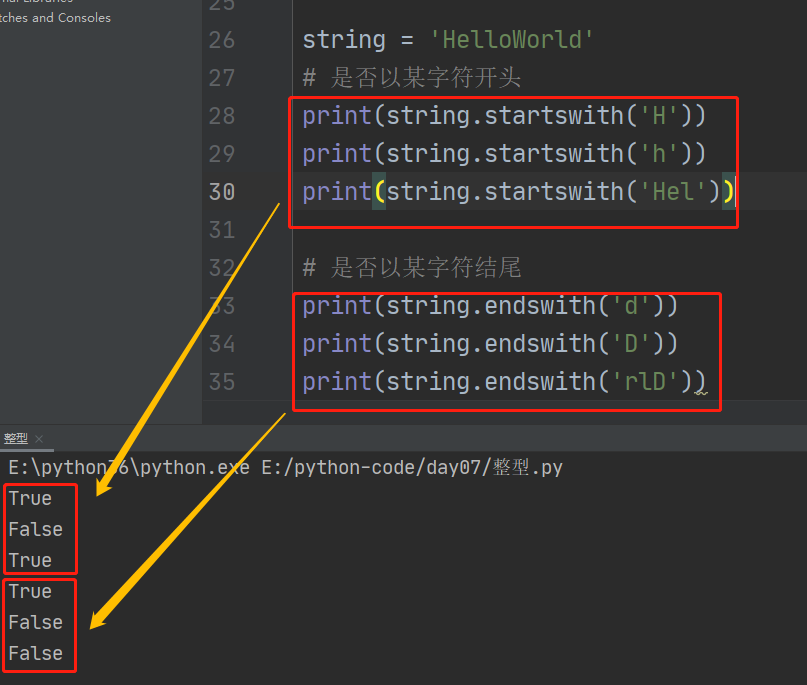
8、startswith和endswith
1、.startswith() 判断是否以指定字符开头,返回值为True或False
2、.endswith() 判断是否以指定字符结尾,返回值为True或False
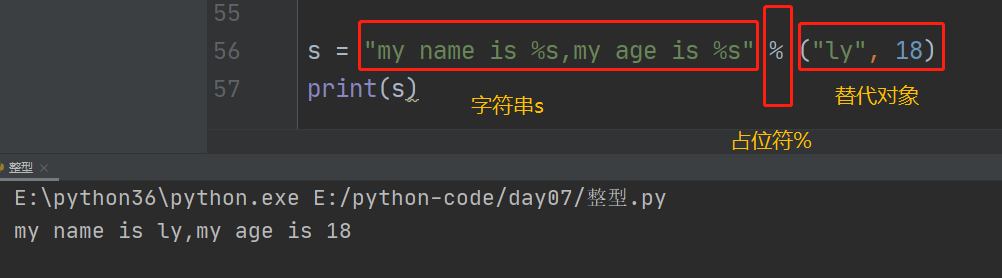
9、 格式化输出:format 和 占位符%s
9.1 占位符%s
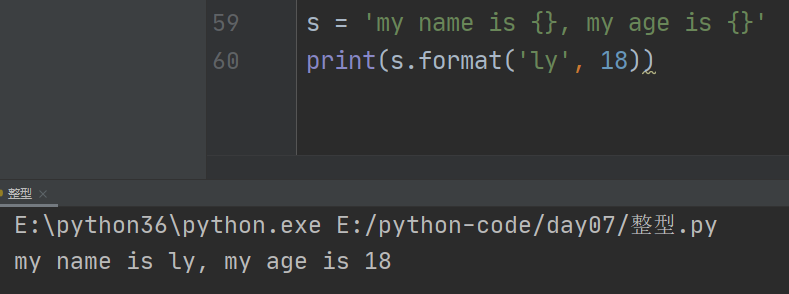
9.2 format
用法1:
类似于%s的用法,传入的值会按照位置与{}一一对应
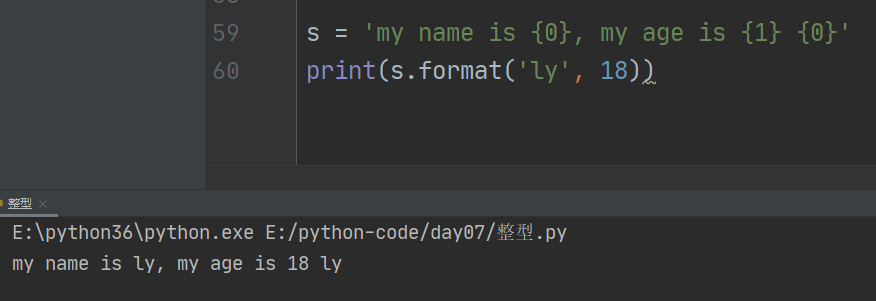
用法2:
把format传入的多个值当作一个列表,然后用{索引}取值
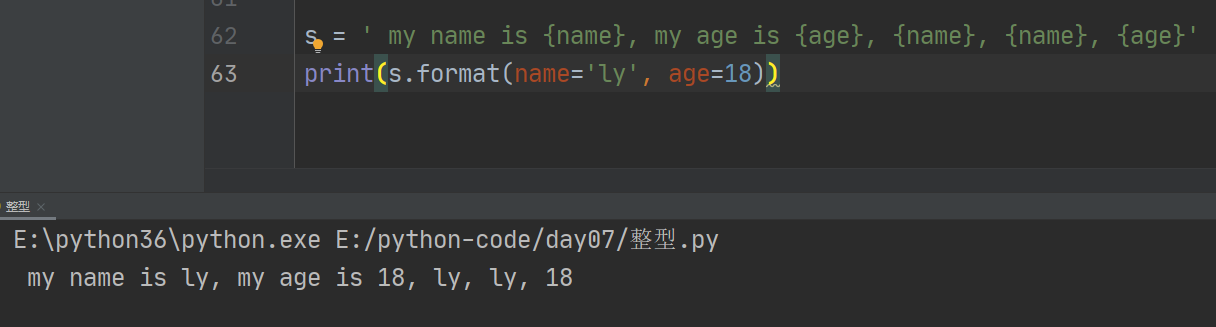
用法3:
{里面}写变量名,然后在format里给变量名赋值
10、字符串拼接 + 和 join
只能拼接字符串,如果有其他类型(整型、浮点等),务必转成字符串类型,否则报错
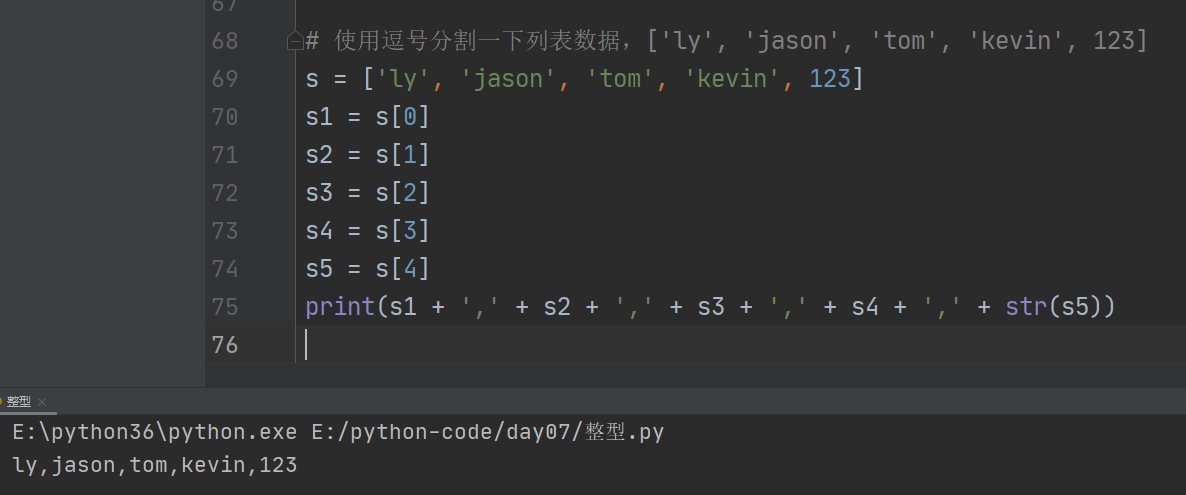
1、基本拼接 +
字符串 + 字符串
2、join拼接
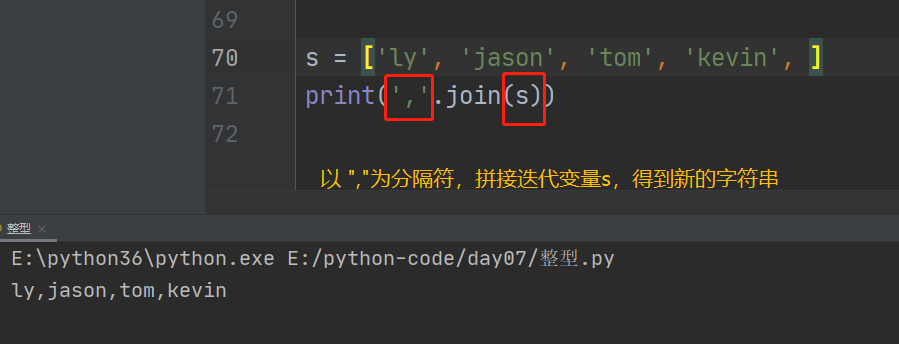
1、定义
从可迭代对象中取出多个字符串,然后按照指定的分隔符进行拼接
拼接的结果为字符串
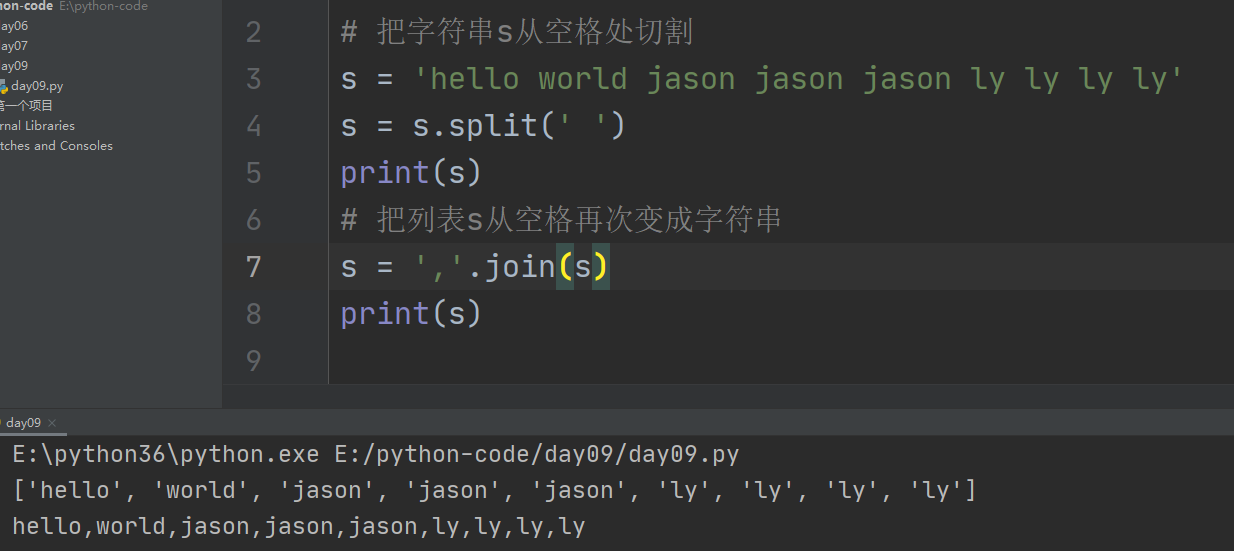
2.实际应用:
把列表按特定字符切割成字符串
11、replace 替换字符串
1、用新的字符替换字符串中旧的字符
语法:replace('旧内容', '新内容')
2、可以指定修改的个数
语法:replace('旧内容', '新内容',要修改的个数 )
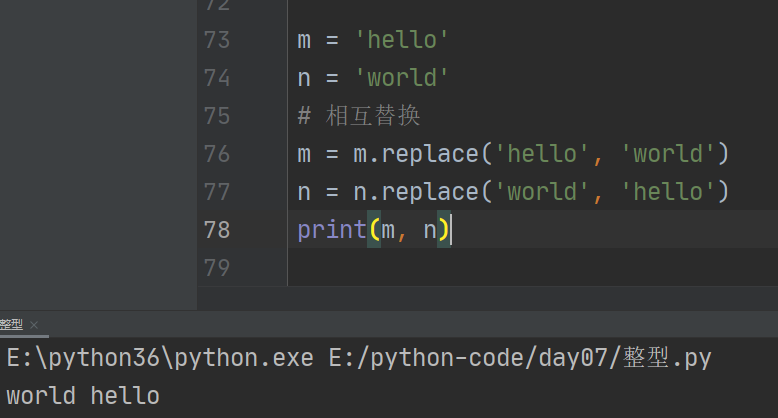
3、交换两个变量的三种方法
1.引入第三个变量
2.解压赋值(交叉赋值)
3.replace相互替代
12、isdigit
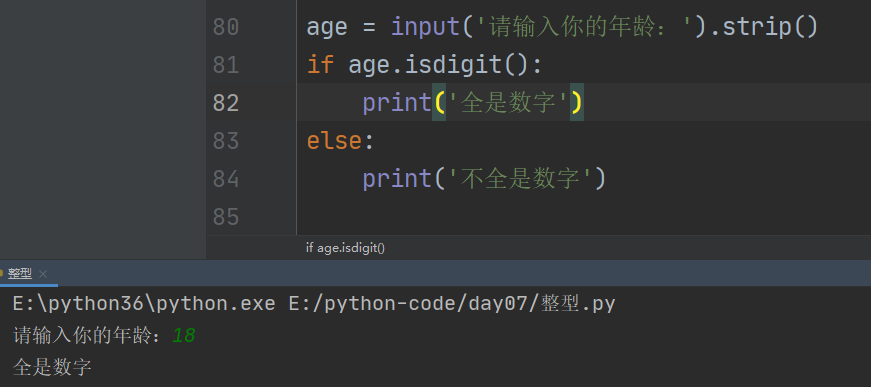
1、判断是否是数字,输出为True或false
2、实际应用:判断用户输入的年龄是否是数字
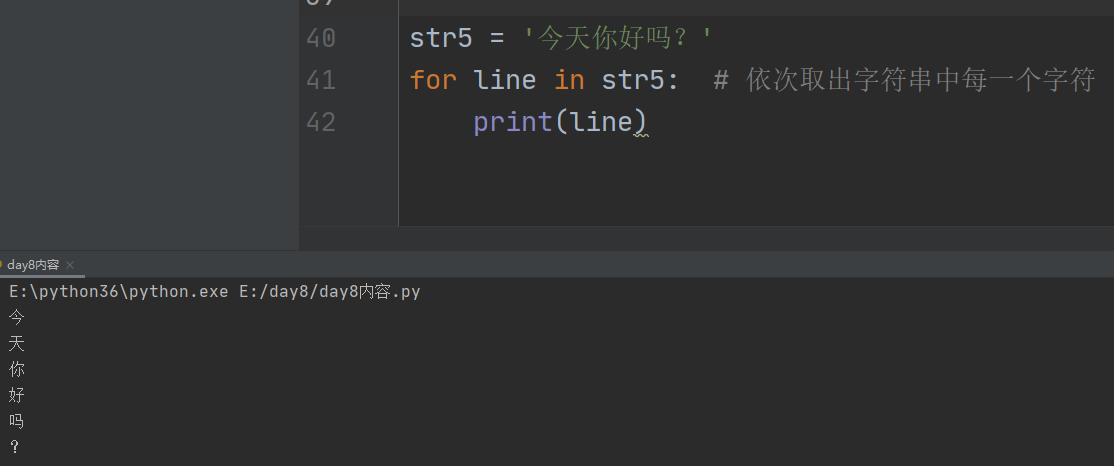
13、循环
1、主要用法:依次取出字符串中的每个字符
14、需要了解的内置方法
1、find:
从指定范围内查找子字符串的起始索引,找得到则返回数字1,找不到则返回-1
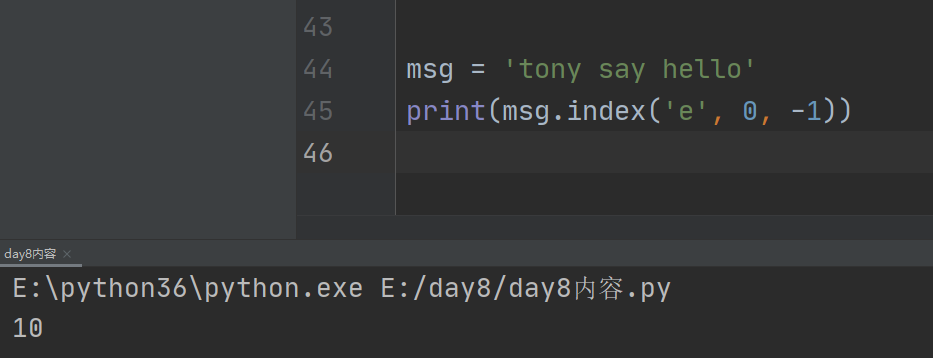
2、index:
同find,从指定范围内查找子字符串的起始索引,找得到则索引值,但在找不到时会报错
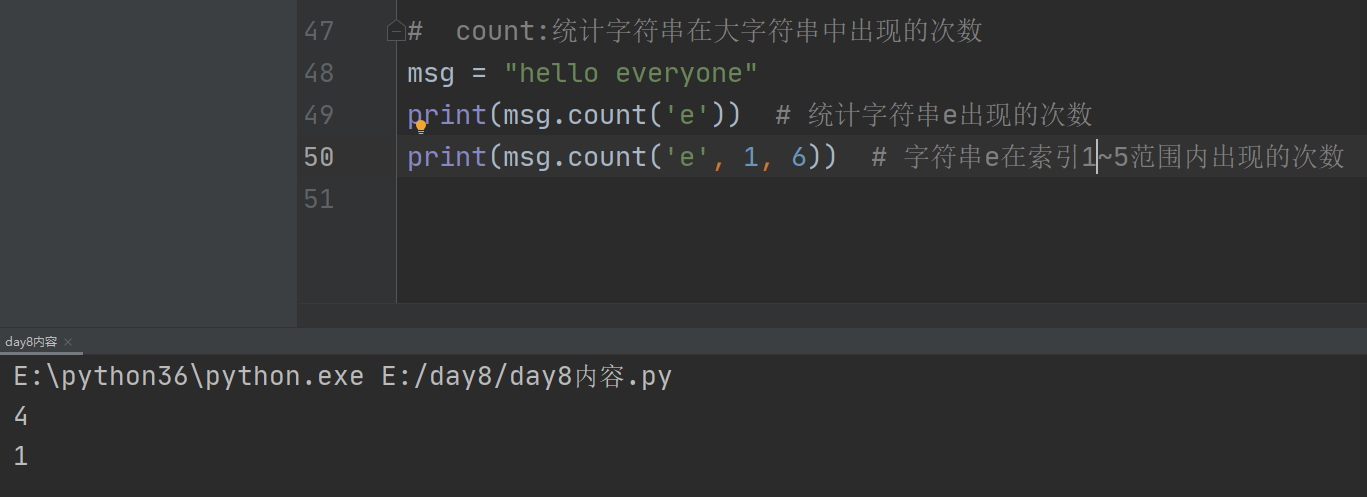
3、count:
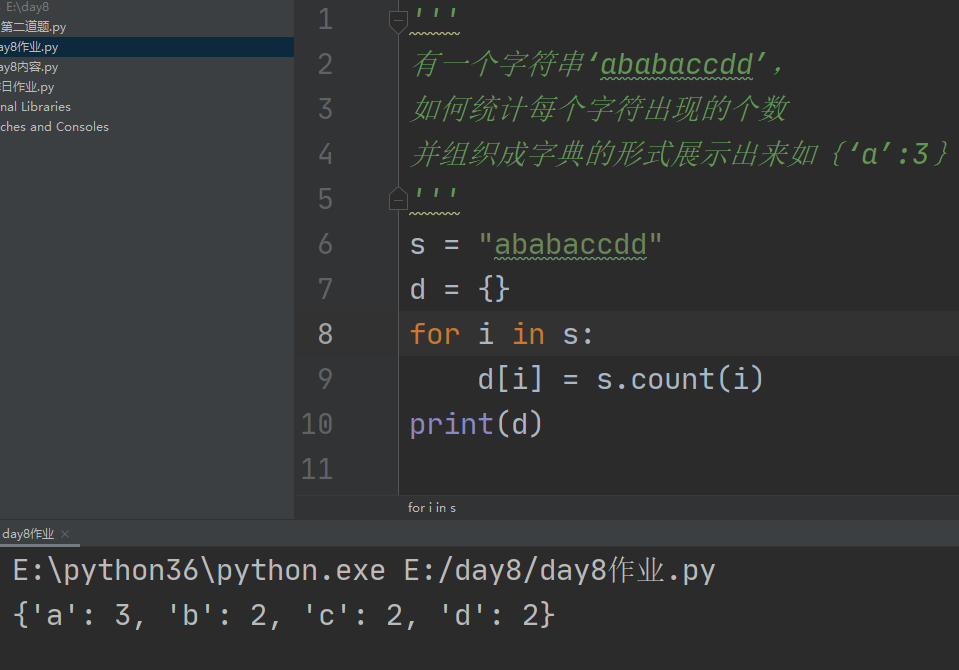
统计字符串在大字符串中出现的次数
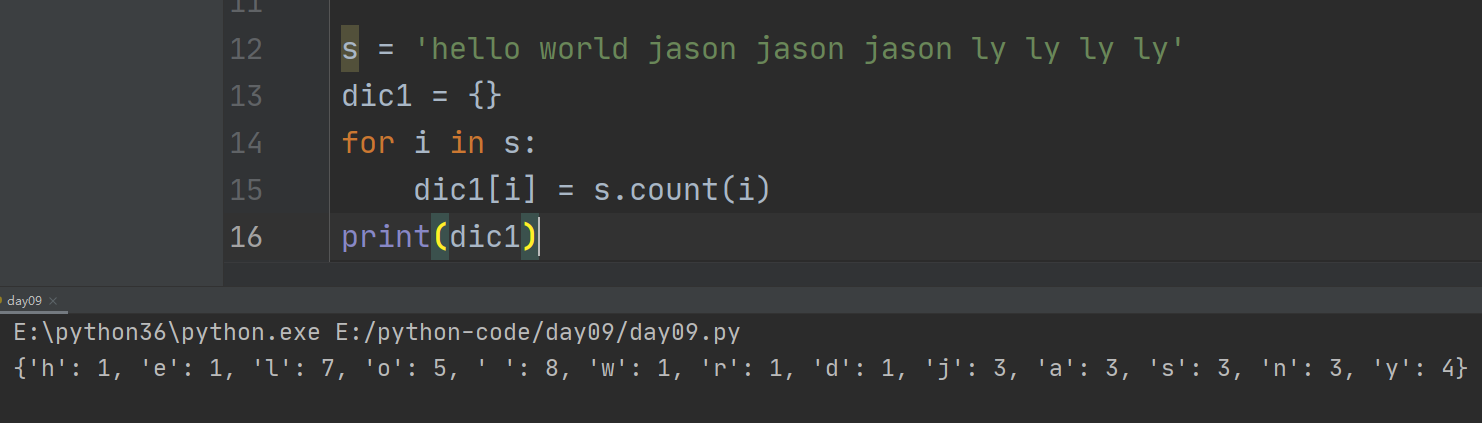
实际应用:统计字符串中每个字符的个数,并用字典表示
4、center,ljust,rjust,zfill
name = 'tony'
1.name.center(30, '-')
# 总宽度为30,字符串居中显示,不够用-填充
-------------tony - ------------
2.name.ljust(30, '*')
# 总宽度为30,字符串左对齐显示,不够用*填充
** ** ** ** ** ** ** ** ** ** ** ** ** tony
3.name.rjust(30, '*')
# 总宽度为30,字符串右对齐显示,不够用*填充
** ** ** ** ** ** ** ** ** ** ** ** ** tony
4.name.zfill(50)
# 总宽度为50,字符串右对齐显示,不够用0填充
0000000000000000000000000000000000000000000000tony

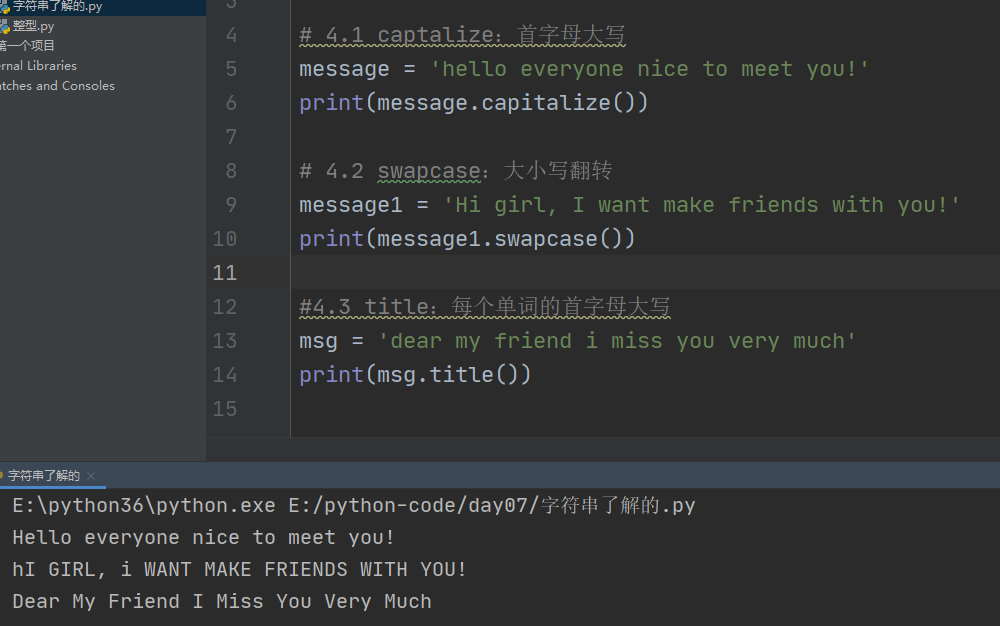
5、captalize:
首字母大写
6、swapcase:
大小写翻转
7、title:
每个单词的首字母大写
四、列表
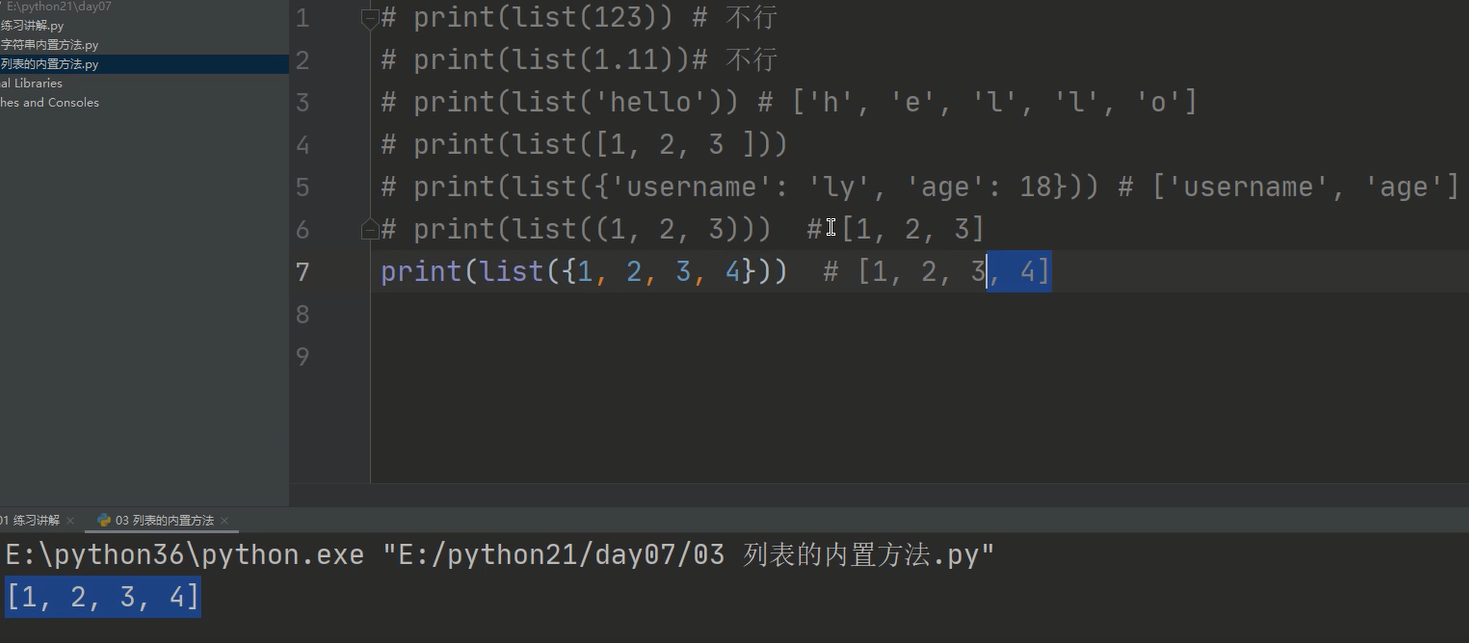
1、类型转换
整数和浮点类型不能转换成列表
字符串、列表、字典、集合、元组可以转换成列表
但凡能被for循环遍历的数据类型都可以传给list()转换成列表类型,list()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到列表中
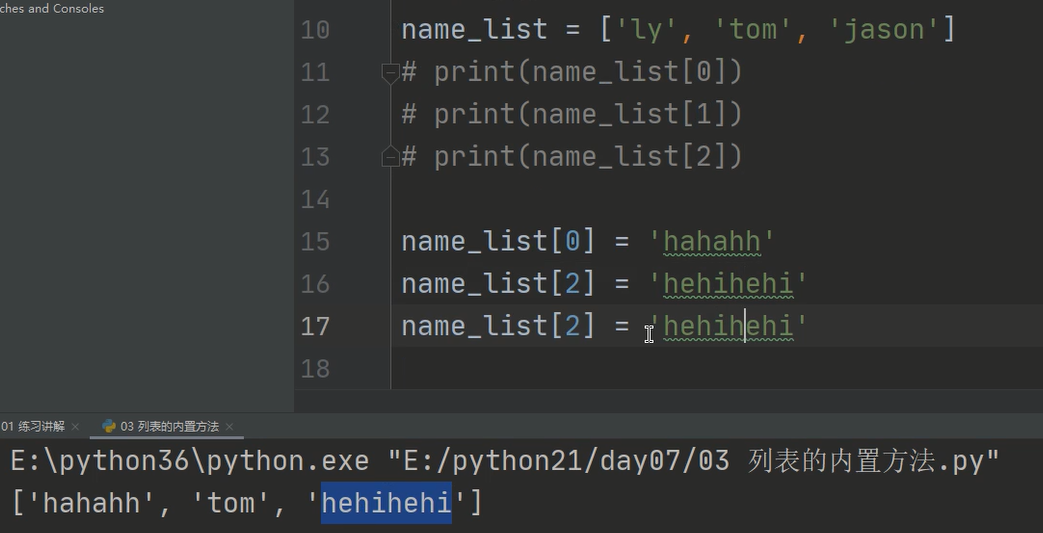
2、列表的修改
通过索引[]值,重新赋值,即可实现修改
如果列表索引超出范围,则报错
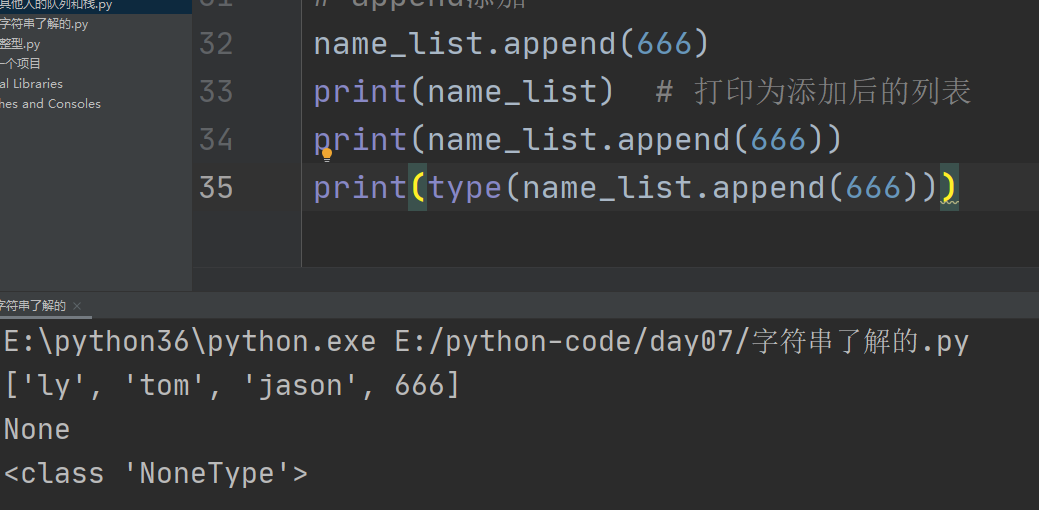
3、列表的添加
1、末尾添加.append()
一次只能添加一个参数,
如果这个参数是一个列表,最后可以作为一个嵌套的列表
注意:
列表中的内置方法不能再直接赋值给原列表,否则输出为None
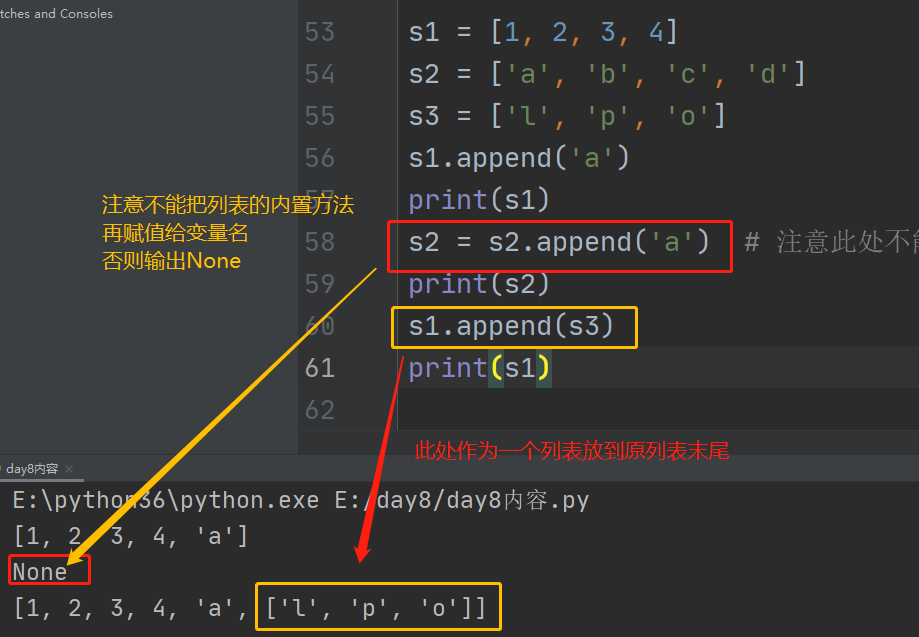
2、末尾添加多个元素 .extend()
一次性在列表尾部添加多个元素
如果这个参数是一个列表,最后输出的是一个列表(非嵌套),两个列表合并

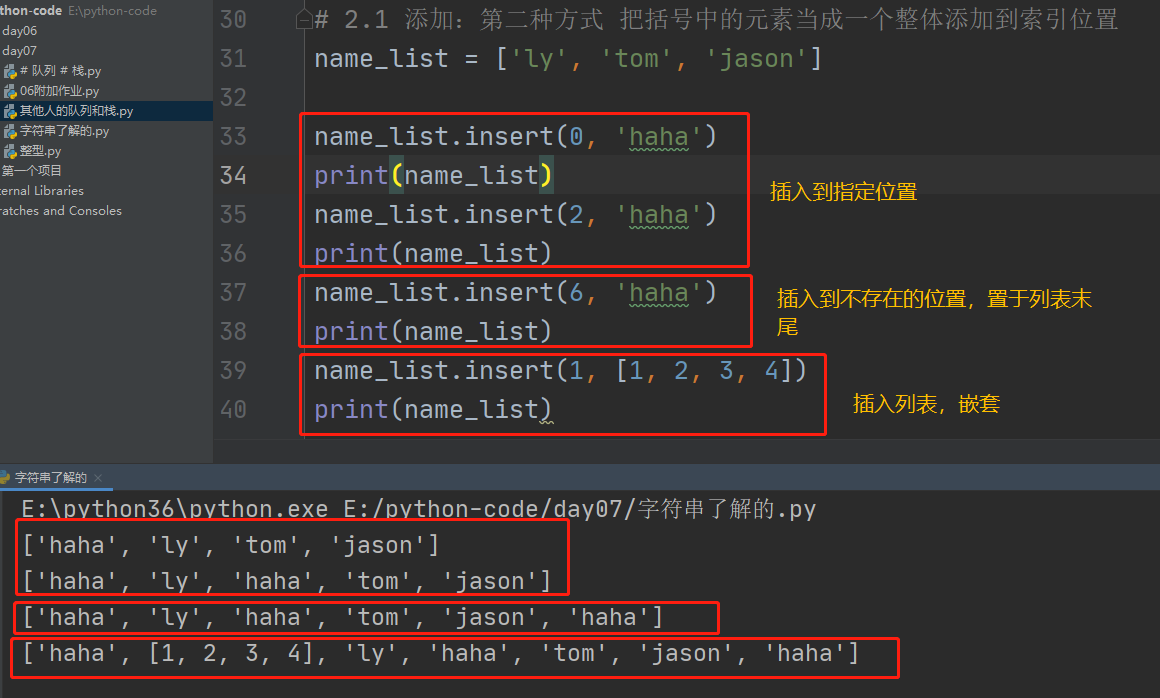
3、在指定位置插入元素 .insert
可以通过索引把新元素插入到列表的指定位置
insert把所有元素作为一个整体插入(嵌套)
4、列表的删除
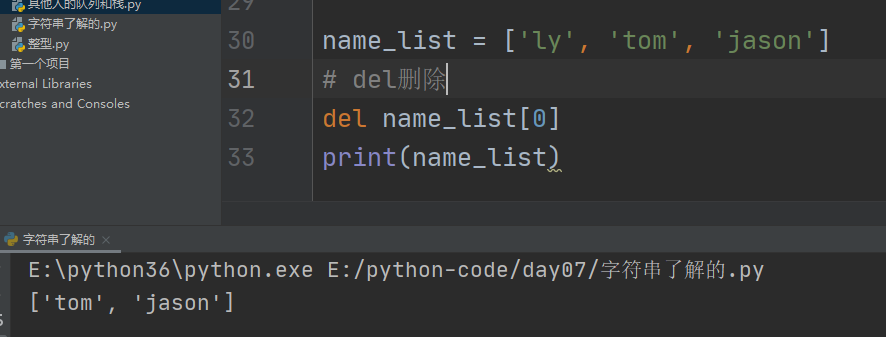
1、del删除
通过del索引删除
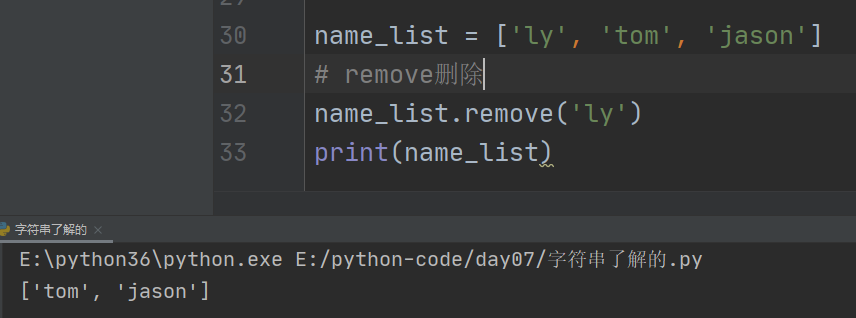
2、remove删除
通过.remove(),括号内直接写值删除
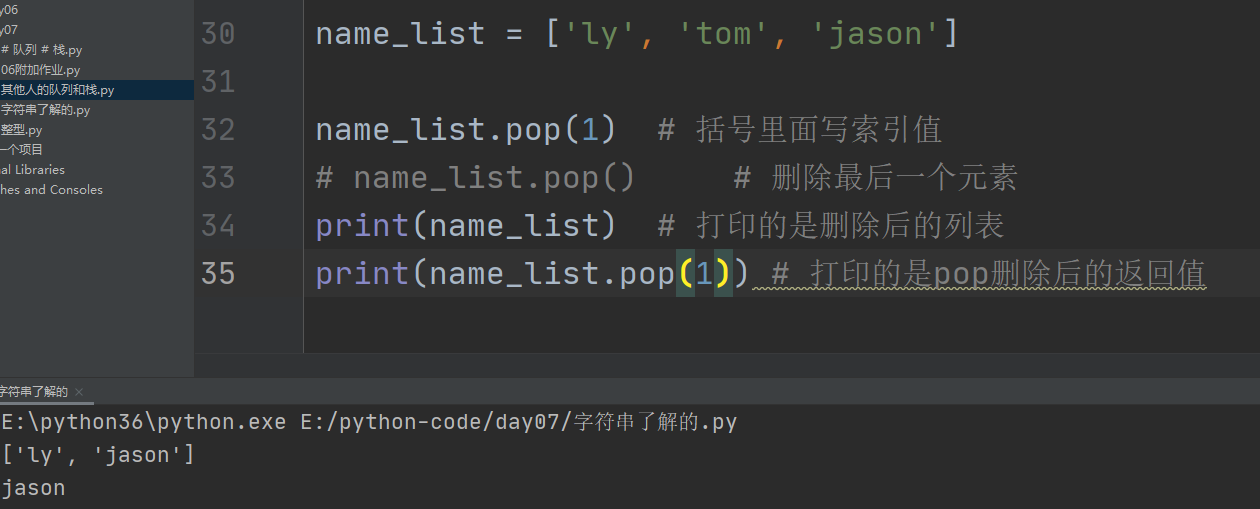
3、pop删除
.pop()默认删除列表最后一个元素,并将删除的值返回,括号内可以通过加索引值来指定删除元素
4、可变类型与不可变类型(理论补充)
可变类型:
值改变,内存地址不变
列表
不可变类型:
原值不变,内存地址改变
元组
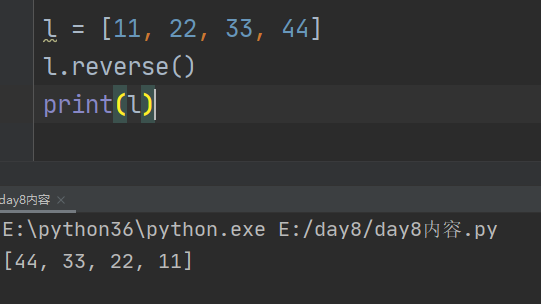
5、reverse
颠倒列表内元素顺序
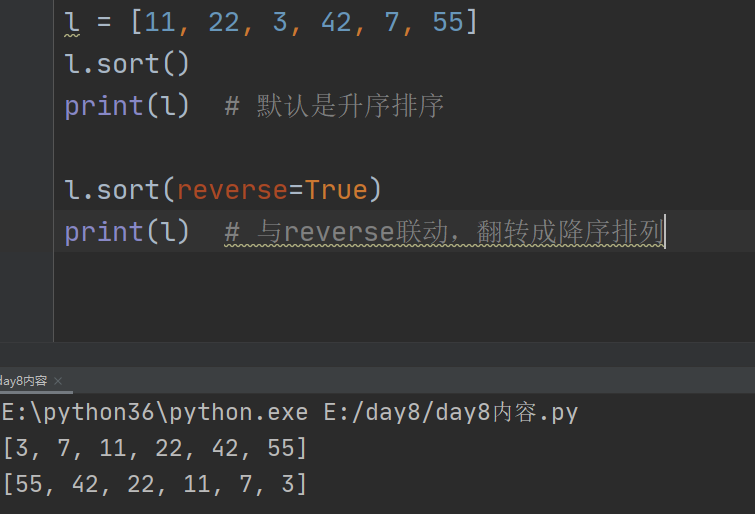
6、sort
.sort()给列表内所有元素排序
默认是升序排列
通过sort.(reverse=True)
reverse用来指定是否跌倒排序,默认为False
排序时列表元素之间必须是相同数据类型,不可混搭,否则报错
7、列表比较
> < ==
我们常用的数字类型直接比较大小,但其实,字符串、列表等都可以比较大小,原理相同:都是依次比较对应位置的元素的大小,如果分出大小,则无需比较下一个元素
字符之间的大小取决于它们在ASCII表中的先后顺序,越往后越大
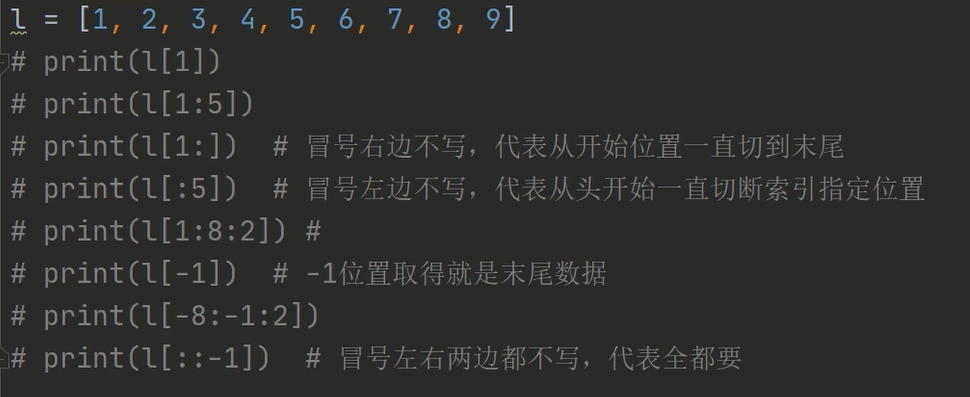
8、列表切片
1、方法:
与字符串切片一样
[]中一个值为取值
[]中两个为切取范围区间,顾头不顾尾
[]中三个为步长,顾头不顾尾
2、注意:
[1:] # 冒号右边不写,代表从开始位置一直切到末尾
[:5] # 冒号左边不写,代表从头开始一直切断索引指定位置
[1:8:2] #从1到7,步长为2
[-1] # -1位置取得就是末尾数据
[-8:-1:2] #从-8到末尾
[::-1] #冒号左右两边都不写,代表全都要
3、用切片操作颠倒字符串和列表顺序
[::-1]
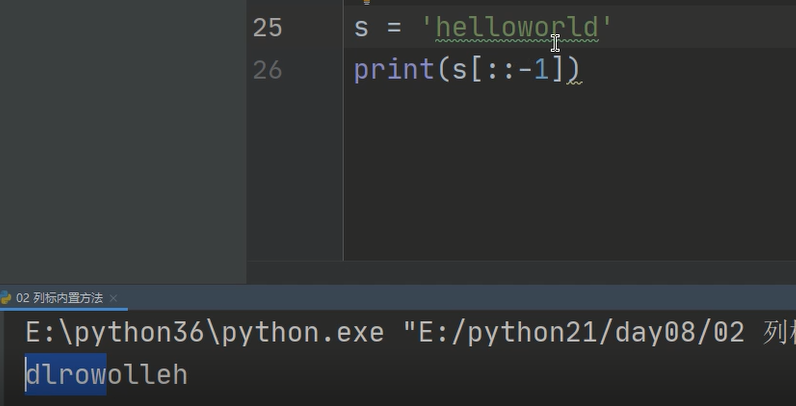
用.sort(reserve=True)也可以实现列表元素翻转
sort为升序,.sort(reserve=True)自然为降序
五、字典
1、定义字典
1、方式一:

2、方式二:
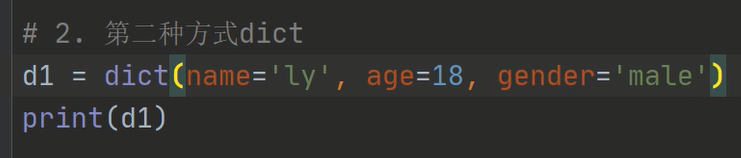
3、方式三:(认识即可)
元组、列表均可以定义字典

2、字典的取值
1、通过k:v关键字中的k取值
没有则报错

2、get取值
1、.get(k)
有则取字典内k的v值
没有则返回None
2、.get(k:v1)
如果k在字典内,但是v1为其他值,还是取出字典内的kv关键值对,v1在此处没有意义
如果k不在字典内,取出v1值
3、修改和添加
1、实现方式
字典的修改和添加都是通过索引看实现的
通过对k重新赋值可以实现字典的修改和添加
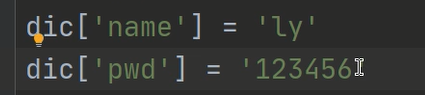
k值 存在,直接进行修改操作
k值不存在,会往字典末尾中添加一个k:v
注意:列表中不可以直接添加一个不存在的索引用来修改列表,否则报错
2、应用:
4、求长度
len
5、成员运算
in 和 not in
判断是否存在于字典中
6、删除
1、方式一:del
del删除k值
2、方式二:.pop(k)
注意:字典中pop(),括号内必须有字典k值
7、字典三剑客
1、dic.keys() 取k
返回一个列表,内容是所有key的值
2、dic.values() 取v
返回一个列表,内容是所有value的值
3、dic.items() 取k:v
返回一个列表,内容是所有k:v键值对的值
8、循环
1、方式一:k循环
for i in dic:
print(i)
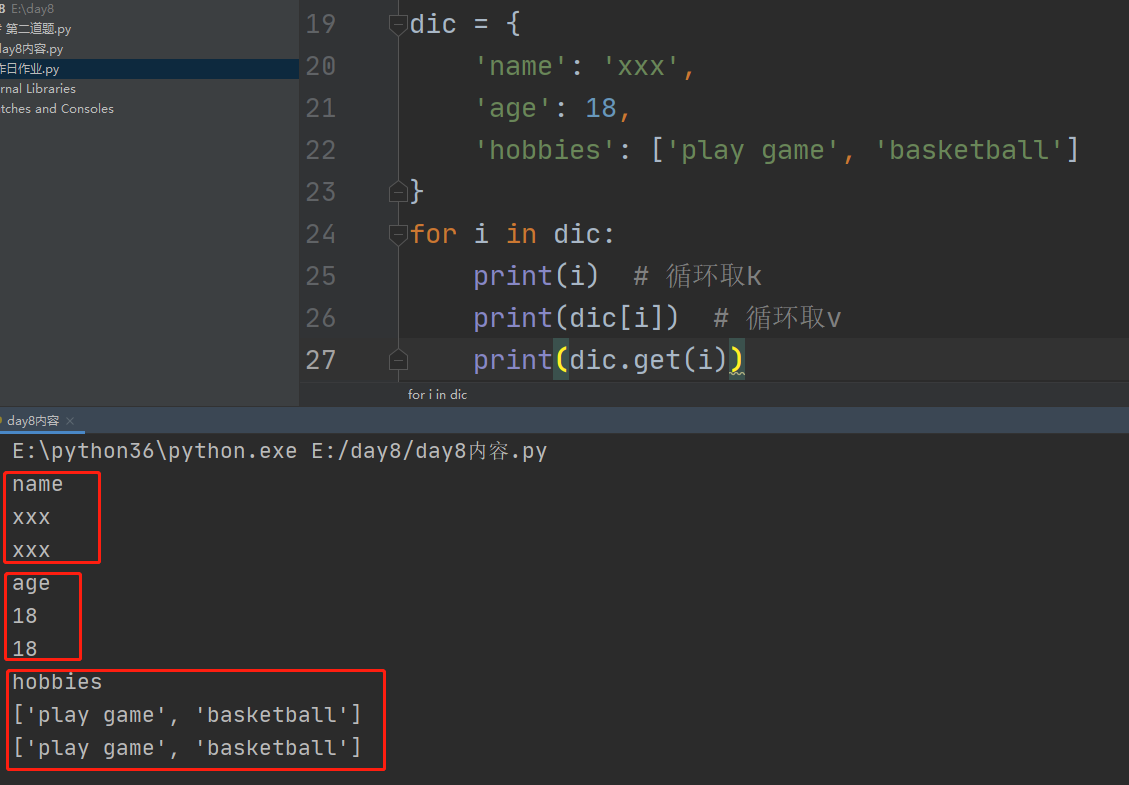
2、方式2:k:v循环
for k,v in dic.items:
print(k,v)
注意:dic.keys和dic.values同理

9、字典需要了解的内置方法
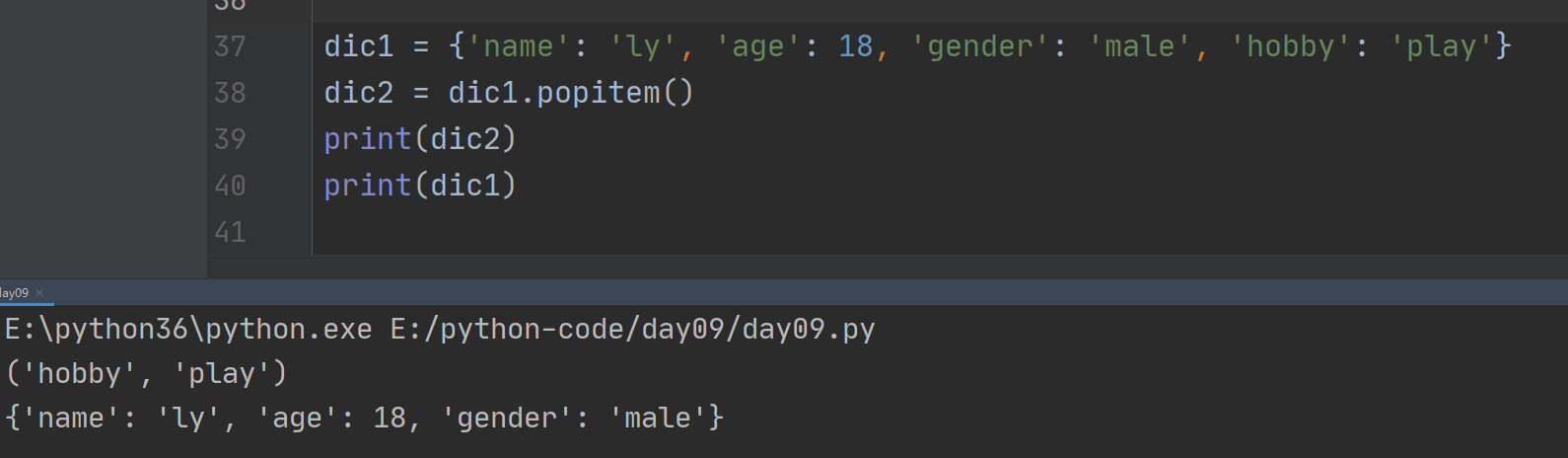
1、popitem()
随机返回并删除字典中的最后一对键和值。
如果字典已经为空,却调用了此方法,就报出KeyError异常。
2、update()
用新字典更新旧字典,有则修改,无则添加
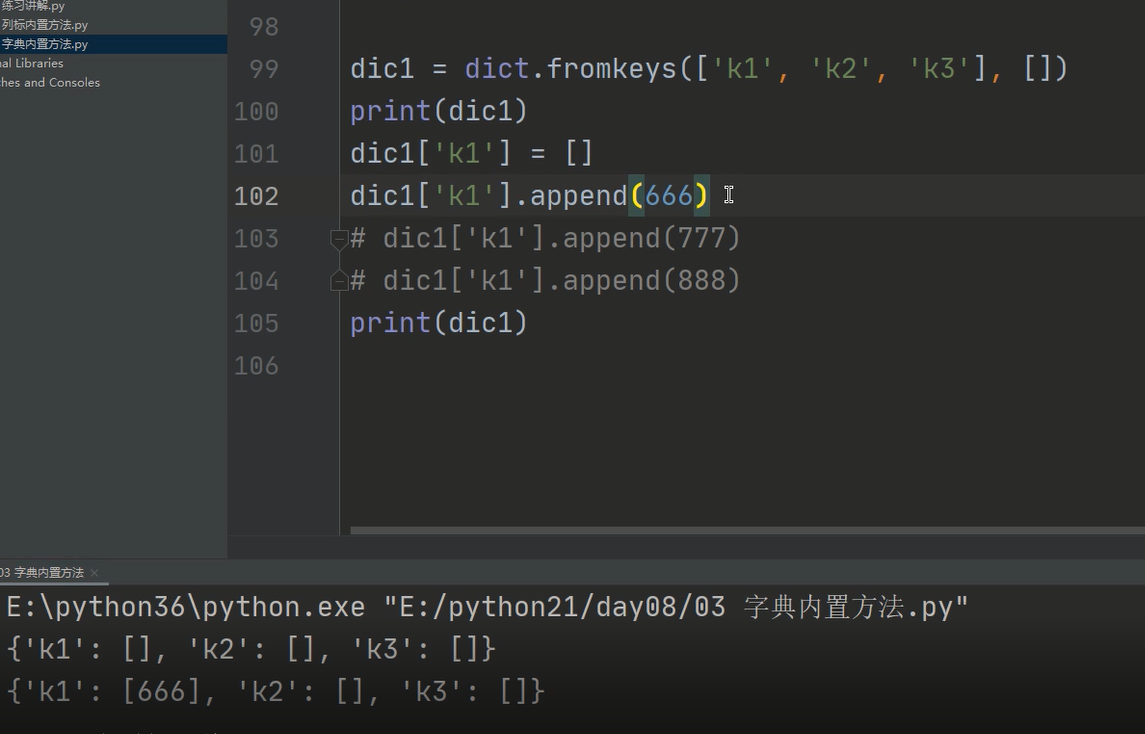
3、dic.fromkeys()
1、给列表内的每一个元素怎加一个value值,使之组成新的字典k:v关键值对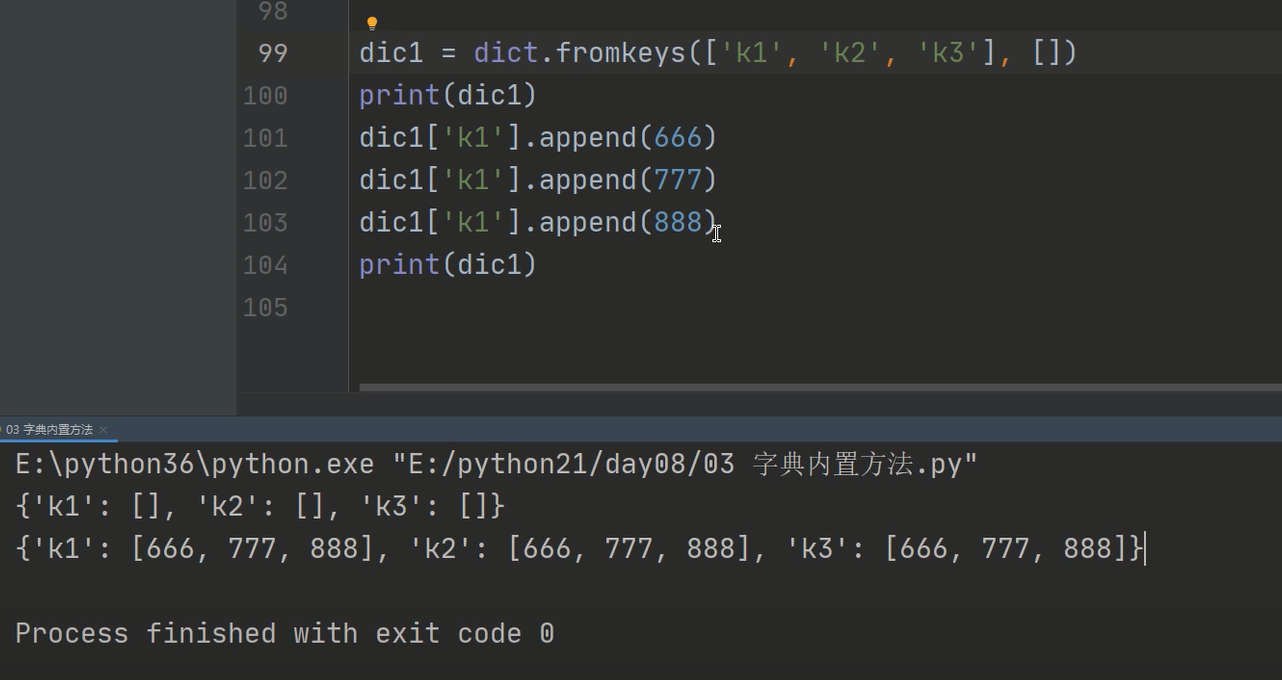
2、给具体某一个k赋值
.append()
4、setdefault()
key不存在则新增键值对,并将新增的value返回
key存在则不做任何修改,并返回已存在key对应的value值

六、元组
1、类型转换
整型、浮点型不可以转换为元组
字符串、列表、元组、字典、集合可以转为元组
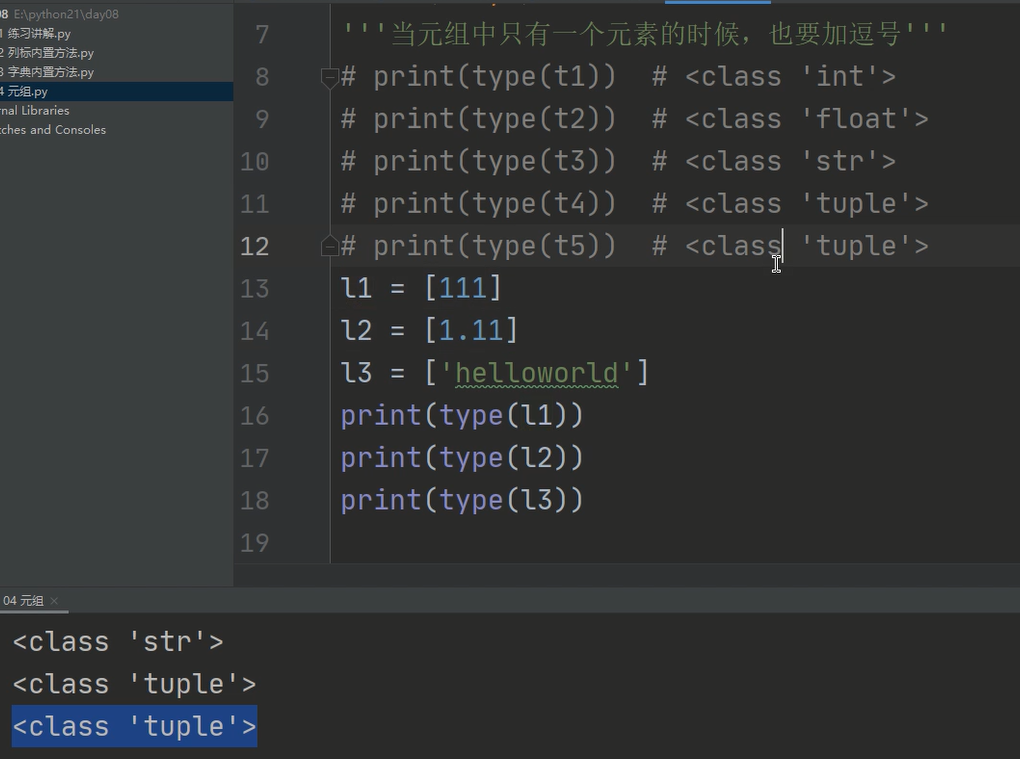
注意:
当元组()中只有一个元素的时候,必须添加一个逗号,否则会默认为那个元素的本来类型
但是但列表中只有一个元素的时候,他还是列表类型,推荐也加一个逗号,以方便记忆
2、索引取值
按索引取值(正向取+反向取):只能取,不能改否则报错!
3、切片
按索引取值(正向取+反向取):只能取,不能改否则报错!
4、长度
len(tuple)
5、成员运算
in 和 not in
返回值为Flase或True
6、循环
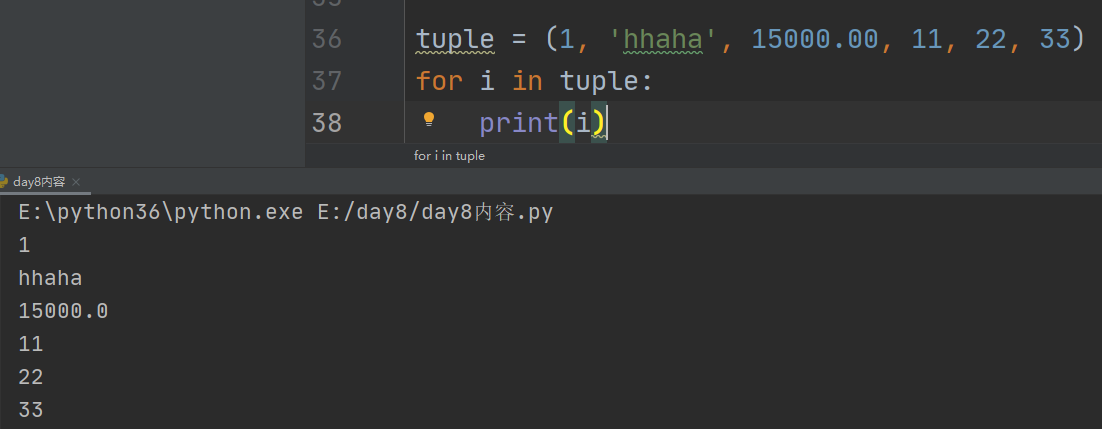
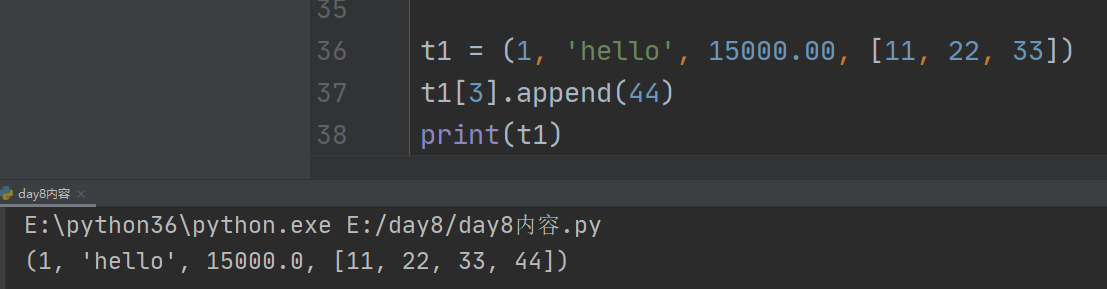
7、注意:
turple元组不能更改,但是如果元组内有列表类型的时候,可以添加元素至列表内
七、集合
1、集合特点:
1、特点:
集合就是在{}内用逗号分隔开的多个元素,集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
2、注意:
列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值
而集合类型既没有索引也没有key与值对应,所以无法取得单个的值
而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
3、空集合定义:
{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,
所以要想定义一个空字典和空集合,应该:
d = {} # 默认是空字典
s = set() # 这才是定义空集合
2、类型转换
但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
字符串、列表、元组、字典、
3、去重
1、简单去重
其他类型转换成集合并打印即可去重,然后转回原类型
2、去重并按原顺序返回
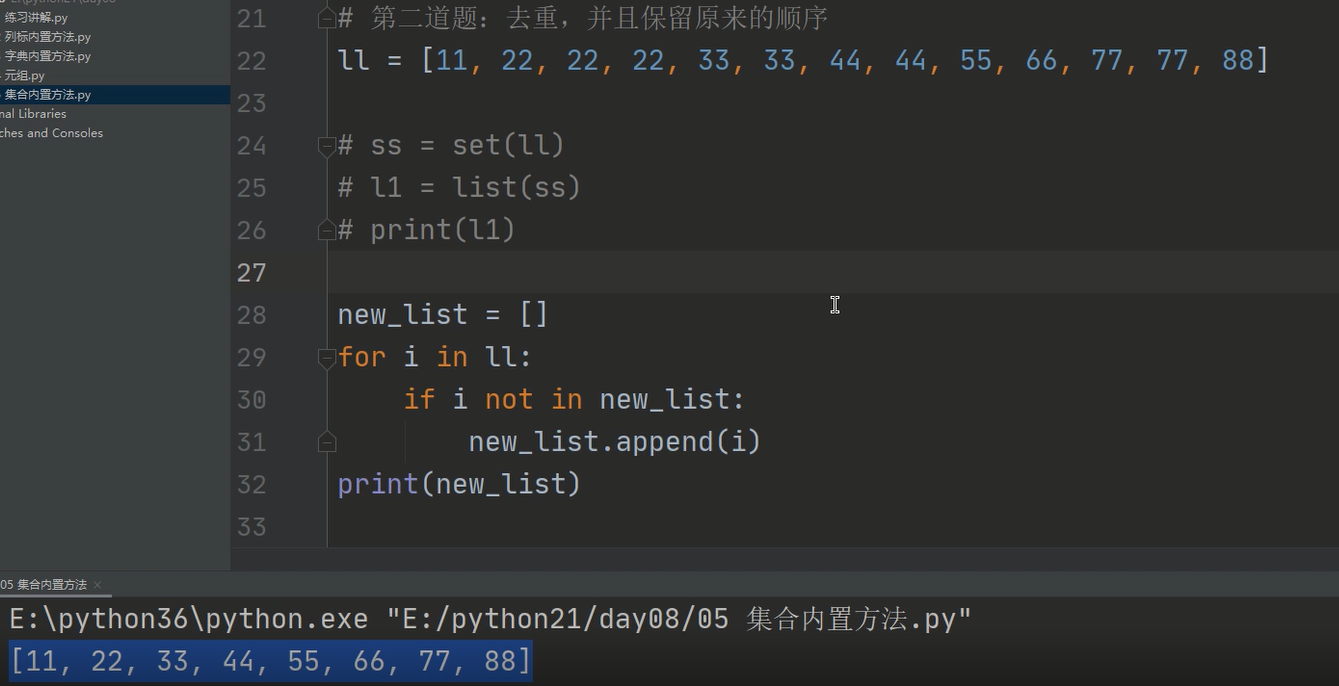
4、关系运算
friends1 = {"zero", "kevin", "jason", "egon"}
friends2 = {"Jy", "ricky", "jason", "egon"}
1、求合集,并集 a | b
print(friends1 | friends2)
2、求交集 a & b
print(friends1 & friends2)
3、求friends1差集 a - b
print(friends1 - friends2)
4、求friends2差集 b - a
print(friends2 - friends1)
5、是否相等 a ==b 返回True和Flase
print(friends2 == friends1)
6、求对称差集 a ^ b
print(friends1 ^ friends2)
6、求父集,子集 a > b a < b
print(friends1 > friends2)
print(friends1 < friends2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号