
Node笔记(2)
写一个可以生成多层级文件夹的函数
const fs = require('fs');
const path = require('path');
function mkdirs (pathname,callback){
var root = path.dirname(module.parent.filename);
pathname = path.isAbsolute(pathname)?pathname:path.join(__dirname,pathname);
relativepath = path.relative(__dirname,pathname);
var folders = relativepath.split(path.sep);
try {
var pre = '';
folders.forEach(folder =>{
try {
//如果不存在则报错
fs.statSync(path.join(__dirname,pre,folder));
} catch (error) {
fs.mkdirSync(path.join(__dirname,pre,folder));
}
pre = path.join(pre, folder);
});
callback && callback(null);
} catch (error) {
callback && callback(error);
}
}
module.exports = mkdirs;
写一个读取markdown然后转换成html最终使用browsersync加载的服务器:
//markdown文件自动转换
const fs = require('fs');
const path = require('path');
const marked = require('marked');
var browserSync = require("browser-sync");
//接受需要转换的文件路径
const target = path.join(__dirname,process.argv[2]||'../README.md');
var filename = target.replace(path.extname(target),'.html');
var indexpath = path.basename(filename);
// 通过browsersync创建文件服务器
browserSync({
server: path.dirname(target),
index:indexpath
});
//监视文件变化
fs.watchFile(target,{interval:200},(curr,prev)=>{
console.log(`current : ${curr.size} ; previous:${prev.size}`);
//判断文件到底有没有变化
if(curr.mtime == prev.mtime ){
return false;
}
//读取文件,转换为新的HTML
fs.readFile(target,'utf8',(err,content)=>{
if(err)
{
throw err;
}
var html = marked(content);
fs.readFile(path.join(__dirname,'github.css'),'utf8',(err,css)=>{
html = template.replace('{{{content}}}',html).replace('{{{styles}}}',css);
fs.writeFile( filename ,html,'utf-8',(err)=>{
// 调用reload方法
browserSync.reload(indexpath);
console.log('UpdatedTime'+ new Date())});
});
});
});
var template = `<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<style> {{{styles}}} </style>
</head>
<body>
<div>
{{{content}}}
</div>
</body>
</html>
`;
流的概念
--流是程序输入或输出的一个连续的字节序列
--文件流,网络流
--设备输入输出都是用流来处理的
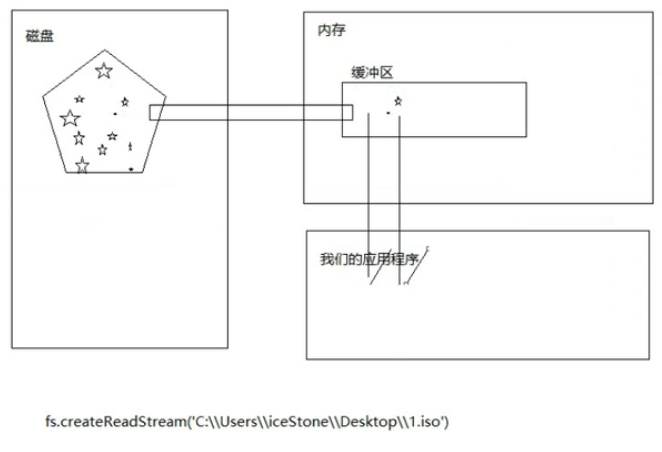
fs.createReadStream()
创建一个流的管子,将磁盘中数据与内存中的部分导通连接起来。。
// 创建文件的读取流,并没有读出正式的数据,开始了读取文件的任务()
(线程池中的处理。。)
// 创建文件的读取流,并没有读出正式的数据,开始了读取文件的任务()
var reader = fs.createReadStream('.\\1.iso');
reader.on('data',(chunk)=>{
//chunk是一个buffer(字节数组)
console.log('读了一点'+chunk.length);
});
//缓冲区存的就是一个字节数组
文件流的方式操作只读流
//文件的复制
const fs = require('fs');
const path = require('path');
// 创建文件的读取流,并没有读出正式的数据,开始了读取文件的任务()
var reader = fs.createReadStream('.\\1.iso');
fs.stat('.\\1.iso',(err,stats)=>{
if(stats){
var readTotal = 0;
reader.on('data',(chunk)=>{
//chunk是一个buffer(字节数组)
console.log('读了一点.进度'+(readTotal+=chunk.length)/stats.size * 100+'%');
});
}
});
文件流的写入:
//文件的复制
const fs = require('fs');
const path = require('path');
// 创建文件的读取流,并没有读出正式的数据,开始了读取文件的任务()
var reader = fs.createReadStream('.\\1.iso');
// 创建一个写入流
var writer = fs.createWriteStream('.\\2.iso');
fs.stat('.\\1.iso',(err,stats)=>{
if(stats){
var readTotal = 0;
reader.on('data',(chunk)=>{
//chunk是一个buffer(字节数组)
writer.write(chunk,(err)=>{
console.log('写了一点.进度'+(readTotal+=chunk.length)/stats.size * 100+'%');
});
});
}
});
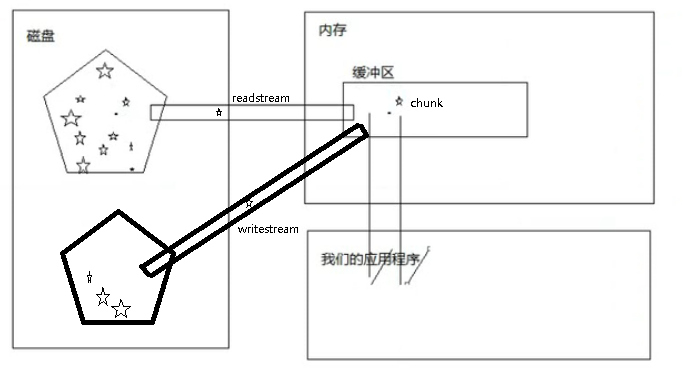
pipe方法
//文件的复制
const fs = require('fs');
const path = require('path');
// 创建文件的读取流,并没有读出正式的数据,开始了读取文件的任务()
var reader = fs.createReadStream('.\\1.iso');
// 创建一个写入流
var writer = fs.createWriteStream('.\\2.iso');
//reader 读取流
reader.pipe(writer);
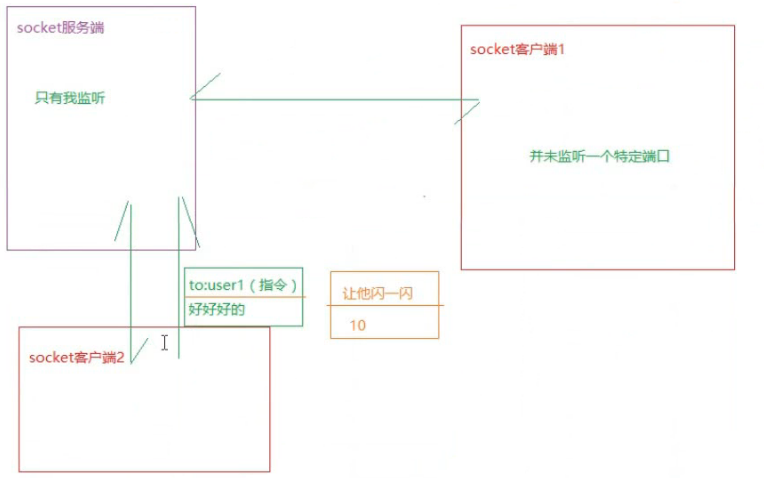
Socket(传输层)
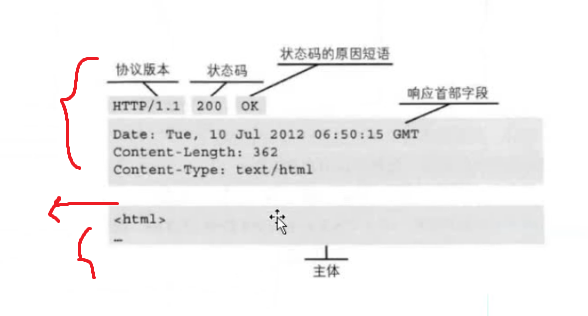
HTTP(应用层)
//
超文本传输协议
浏览器的本质作用
1.将用户输入的URL封装为一个请求报文,
2.建立与服务器端的连接,
3.将封装好的请求报文通过socket发送到服务器端,
server.write(JSON.stringify(send));
4.接收到服务端返回的响应报文,
5.解析响应报文JSON.parse,
6.渲染内容到页面当中 console.log(msg)。
浏览器就是一个Socket客户端
请求报文:

响应报文:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号