Go语言内存分配的原理与实现
为什么需要内存分配器?
总说周知,内存作为一种相对稀缺的资源,在操作系统中以虚拟内存的形式来作为一种内存抽象提供给进程,这里可以简单地把它看做一个连续的地址集合{0, 1, 2, ..., M},由栈空间、堆空间、代码片、数据片等地址空间段组合而成,如下图所示(出自CS:APP3e, Bryant and O'Hallaron的第9章第9节)
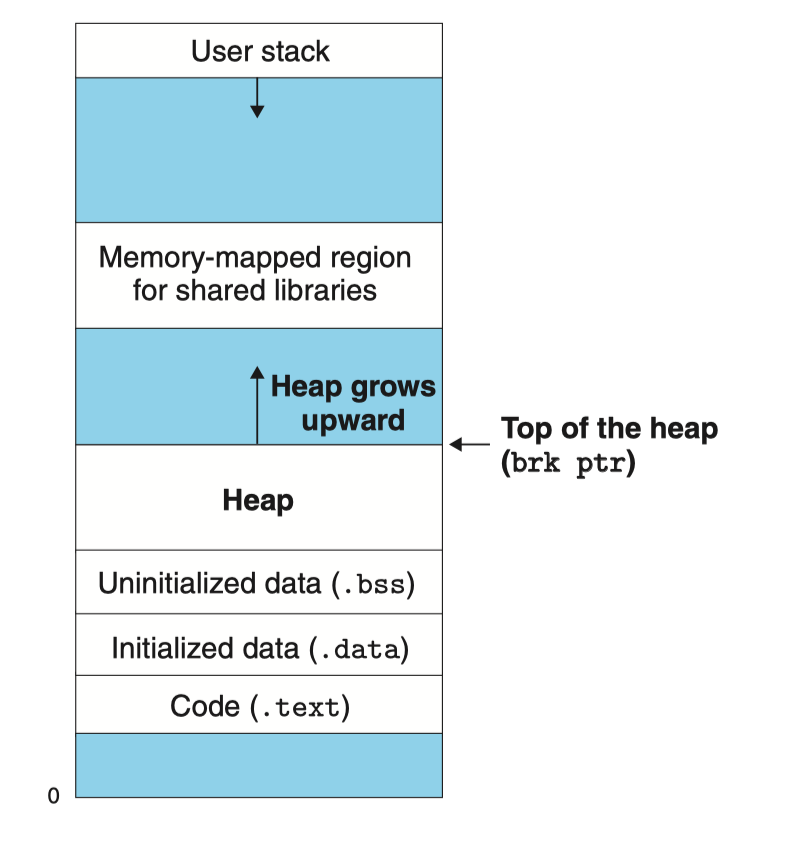
这里我们重点关注Heap(堆),堆是一块动态的虚拟内存地址空间。在C语言中,我们通常使用malloc来申请内存以及使用free来释放内存,也许你想问,这样不就足够了吗?但是,这种手动的内存管理会带来很多问题,比如:
- 给程序员带来额外的心智负担,必须得及时释放掉不再使用的内存空间,否则就很容易出现内存泄露
- 随着内存的不断申请与释放,会产生大量的内存碎片,这将大大降低内存的利用率
因此,正确高效地管理内存空间是非常有必要的,常见的技术实现有Sequential allocation, Free-List allocation等。那么,在Go中,内存是如何被管理的呢?
注:此为Go1.13.6的实现逻辑,随版本更替某些细节会有些许不同
实现原理
Go的内存分配器是基于TCMalloc设计的,因此我建议你先行查阅,这将有利于理解接下来的内容。
大量工程经验证明,程序中的小对象占了绝大部分,且生命周期都较为短暂。因此,Go将内存划分为各种类别(Class),并各自形成Free-List。相较于单一的Free-List分配器,分类后主要有以下优点:
-
其一方面减少不必要的搜索时间,因为对象只需要在其所属类别的空闲链表中搜索即可
-
另一方面减少了内存碎片化,同一类别的空闲链表,每个对象分配的空间都是一样大小(不足则补齐),因此该链表除非无空闲空间,否则总能分配空间,避免了内存碎片
那么,Go内存分配器具体是如何实现的呢?接下来,我将以自顶向下的方式,从宏观到微观,层层拨开她的神秘面纱。
数据结构
首先,介绍Go内存分配中相关的数据结构。其总体概览图如下所示:
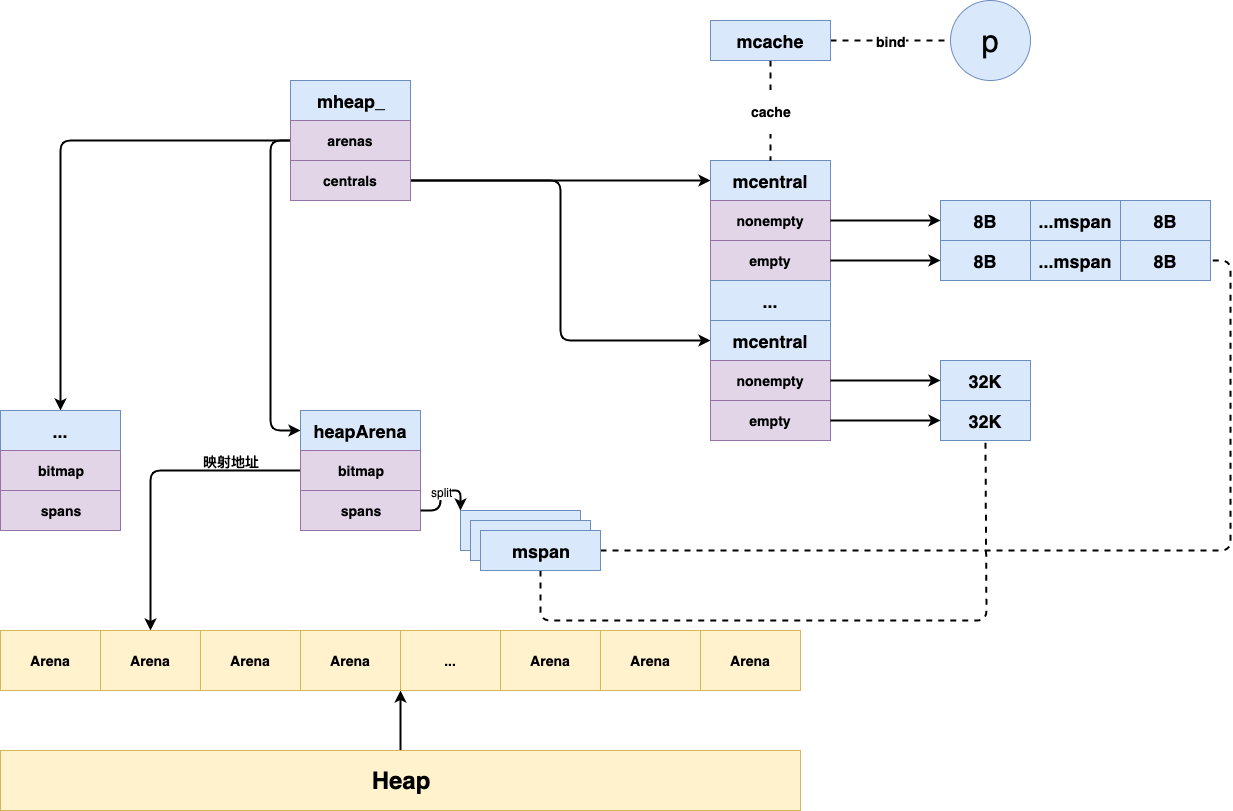
heapArena
在操作系统中,我们一般把堆看做是一块连续的虚拟内存空间。
Go将其划分为数个相同大小的连续空间块,称之arena,其中,heapArena则作为arena空间的管理单元,其结构如下所示:
type heapArena struct {
bitmap [heapArenaBitmapBytes]byte
spans [pagesPerArena]*mspan
...
}
- bitmap: 表示arena区域中的哪些地址保存了对象,哪些地址保存了指针
- spans: 表示arena区域中的哪些操作系统页(8K)属于哪些mspan
mheap
然后,则是核心角色mheap了,它是Go内存管理中的核心数据结构,作为全局唯一变量,其结构如下所示:
type mheap struct {
free mTreap
...
allspans []*mspan
...
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
...
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
}
- free: 使用树堆的结构来保存各种类别的空闲mspan
- allspans: 用以记录了分配过了的mspan
- arenas: 表示其覆盖的所有arena区域,通过虚拟内存地址计算得到下标索引
- central: 表示其覆盖的所有mcentral,一共134个,对应67个类别
mcentral
而mcentral充当mspan的中心管理员,负责管理某一类别的mspan,其结构如下:
type mcentral struct {
lock mutex
spanclass spanClass
nonempty mSpanList
empty mSpanList
}
- lock: 全局互斥锁,因为多个线程会并发请求
- spanclass:mspan类别
- nonempty:mspan的双端链表,且其中至少有一个mspan包含空闲对象
- empty:mspan的双端链表,但不确定其中的mspan是否包含空闲对象
mcache
mcache充当mspan的线程本地缓存角色,其与线程处理器(P)一一绑定。
这样呢,当mcache有空闲mspan时,则无需向mcentral申请,因此可以避免诸多不必要的锁消耗。结构如下所示:
type mcache struct {
...
alloc [numSpanClasses]*mspan
...
}
- alloc: 表示各个类别的mspan
mspan
mspan作为虚拟内存的实际管理单元,管理着一片内存空间(npages个页),其结构如下所示:
type mspan struct {
next *mspan // 指向下一个mspan
prev *mspan // 指向前一个mspan
...
npages uintptr
freeindex uintptr
nelems uintptr // 总对象个数
...
allocBits *gcBits
gcmarkBits *gcBits
}
- next指针指向下一个mspan,prev指针指向前一个mspan,因此各个mspan彼此之间形成一个双端链表,并被runtime.mSpanList作为链表头。
- npages:mspan所管理的页的数量
- freeindex:空闲对象的起始位置,如果freeindex等于nelems时,则代表此mspan无空闲对象可分配了
- allocBits:标记哪些元素已分配,哪些未分配。与freeindex结合,可跳过已分配的对象
- gcmarkBits:标记哪些对象存活,每次GC结束时,将其设为allocBits
通过上述对Go内存管理中各个关键数据结构的介绍,想必现在,我们已经对其有了一个大概的轮廓。接下来,让我们继续探究,看看Go具体是如何利用这些数据结构来实现高效的内存分配算法
算法
分配内存
内存分配算法,其主要函数为runtime.mallocgc,其基本步骤简述如下:
- 判断待分配对象的大小
- 若对象小于maxTinySize(16B),且不为指针,则执行微对象分配算法
- 若对象小于maxSmallSize(32KB),则执行小对象分配算法
- 否则,则执行大对象分配算法
在微对象以及小对象分配过程中,如果span中找不到足够的空闲空间,Go会触发层级的内存分配申请策略。其基本步骤如下:
- 先从mcache寻找对应类别的span,若有空闲对象,则成功返回
- 若无,则向mcentral申请,分别从nonempty和empty中寻找匹配的span,若找到,则成功返回
- 若还未找到,则继续向mheap申请,从mheap.free中寻找,若找到,则成功返回
- 若未找到,则需扩容,从关联的arena中申请,若关联的arena中空间也不足,则向OS申请额外的arena
- 扩容完毕后,继续从mheap.free中寻找,若仍未找到,则抛出错误
源码分析
mallocgc函数
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if debug.sbrk != 0 {
align := uintptr(16)
if typ != nil {
// TODO(austin): This should be just
// align = uintptr(typ.align)
// but that's only 4 on 32-bit platforms,
// even if there's a uint64 field in typ (see #599).
// This causes 64-bit atomic accesses to panic.
// Hence, we use stricter alignment that matches
// the normal allocator better.
if size&7 == 0 {
align = 8
} else if size&3 == 0 {
align = 4
} else if size&1 == 0 {
align = 2
} else {
align = 1
}
}
return persistentalloc(size, align, &memstats.other_sys)
}
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := size
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.ptrdata == 0
if size <= maxSmallSize {
if noscan && size < maxTinySize { // 分配微对象
// Go将多个微对象放置在一个单独的内存块中(这里是16 bytes),当内存块中所有的
// 对象都不可达后,则该内存块为空闲内存块。
// Tiny allocator.
//
// Tiny allocator combines several tiny allocation requests
// into a single memory block. The resulting memory block
// is freed when all subobjects are unreachable. The subobjects
// must be noscan (don't have pointers), this ensures that
// the amount of potentially wasted memory is bounded.
//
// Size of the memory block used for combining (maxTinySize) is tunable.
// Current setting is 16 bytes, which relates to 2x worst case memory
// wastage (when all but one subobjects are unreachable).
// 8 bytes would result in no wastage at all, but provides less
// opportunities for combining.
// 32 bytes provides more opportunities for combining,
// but can lead to 4x worst case wastage.
// The best case winning is 8x regardless of block size.
//
// Objects obtained from tiny allocator must not be freed explicitly.
// So when an object will be freed explicitly, we ensure that
// its size >= maxTinySize.
//
// SetFinalizer has a special case for objects potentially coming
// from tiny allocator, it such case it allows to set finalizers
// for an inner byte of a memory block.
//
// The main targets of tiny allocator are small strings and
// standalone escaping variables. On a json benchmark
// the allocator reduces number of allocations by ~12% and
// reduces heap size by ~20%.
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
if size&7 == 0 {
off = round(off, 8)
} else if size&3 == 0 {
off = round(off, 4)
} else if size&1 == 0 {
off = round(off, 2)
}
// 如果内存块有足够的空间,则直接进行分配
if off+size <= maxTinySize && c.tiny != 0 {
// The object fits into existing tiny block.
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
// 否则,额外再申请一块maxTinySize大小内存
// Allocate a new maxTinySize block.
span := c.alloc[tinySpanClass] // tinySpanClass = 5 // 101
v := nextFreeFast(span)
if v == 0 {
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else { // 分配小对象
// maxTinySize(16B) < size <= maxSmallSize(32K),则为小对象
// 通过size得到其所属的大小类别sizeclass
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
// 通过sizeclass得到实际size
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
span := c.alloc[spc]
// 尝试从span中获取空闲空间
v := nextFreeFast(span)
if v == 0 {
// 如未获取到,则向上一级(mcache)申请
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else { // 分配大对象
var s *mspan
shouldhelpgc = true
systemstack(func() {
// 直接从系统栈上调用largeAlloc
s = largeAlloc(size, needzero, noscan)
})
// 此时span上只有一个对象
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
publicationBarrier()
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0
releasem(mp)
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
if rate := MemProfileRate; rate > 0 {
if rate != 1 && size < c.next_sample {
c.next_sample -= size
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t)
}
}
return x
}
这里有两个重要的函数,分别为nextFreeFast和nextFree函数
nextFreeFast函数
尝试从span中获取空闲空间,根据bitmap mspan.allocCache来寻找空闲空间
// nextFreeFast returns the next free object if one is quickly available.
// Otherwise it returns 0.
func nextFreeFast(s *mspan) gclinkptr {
theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
// 若还有空闲页
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
return gclinkptr(result*s.elemsize + s.base())
}
}
return 0
}
mcache.nextFree函数
再次尝试从span中获取空闲空间,如无空闲空间则调用refill函数
// nextFree returns the next free object from the cached span if one is available.
// Otherwise it refills the cache with a span with an available object and
// returns that object along with a flag indicating that this was a heavy
// weight allocation. If it is a heavy weight allocation the caller must
// determine whether a new GC cycle needs to be started or if the GC is active
// whether this goroutine needs to assist the GC.
//
// Must run in a non-preemptible context since otherwise the owner of
// c could change.
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
s = c.alloc[spc] // 获取span
shouldhelpgc = false
freeIndex := s.nextFreeIndex()
// span中已无空闲空间
if freeIndex == s.nelems {
// The span is full.
if uintptr(s.allocCount) != s.nelems {
println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount != s.nelems && freeIndex == s.nelems")
}
// 额外再申请一个空闲span
c.refill(spc)
shouldhelpgc = true
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
// 计算mspan地址
v = gclinkptr(freeIndex*s.elemsize + s.base())
s.allocCount++
if uintptr(s.allocCount) > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
return
}
mcache.refill函数
refill函数尝试从mcentral中获取span,并回填到mcache中,替换掉原先的span。(TODO: 原先的span要怎么办呢?不管了吗?)
// refill acquires a new span of span class spc for c. This span will
// have at least one free object. The current span in c must be full.
//
// Must run in a non-preemptible context since otherwise the owner of
// c could change.
func (c *mcache) refill(spc spanClass) {
// Return the current cached span to the central lists.
s := c.alloc[spc]
if uintptr(s.allocCount) != s.nelems {
throw("refill of span with free space remaining")
}
if s != &emptymspan {
// Mark this span as no longer cached.
if s.sweepgen != mheap_.sweepgen+3 {
throw("bad sweepgen in refill")
}
atomic.Store(&s.sweepgen, mheap_.sweepgen)
}
// 从mcentral中获取新的mspan
// Get a new cached span from the central lists.
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
if uintptr(s.allocCount) == s.nelems {
throw("span has no free space")
}
// Indicate that this span is cached and prevent asynchronous
// sweeping in the next sweep phase.
s.sweepgen = mheap_.sweepgen + 3
// 回填进mcache
c.alloc[spc] = s
}
mcentral.cacheSpan函数
该函数尝试从mecentral中获取有空闲空间的span,若无,则从mheap中获取
// Allocate a span to use in an mcache.
func (c *mcentral) cacheSpan() *mspan {
// Deduct credit for this span allocation and sweep if necessary.
spanBytes := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) * _PageSize
deductSweepCredit(spanBytes, 0)
lock(&c.lock)
traceDone := false
if trace.enabled {
traceGCSweepStart()
}
sg := mheap_.sweepgen
retry:
var s *mspan
// 先尝试从nonempty中分配
for s = c.nonempty.first; s != nil; s = s.next {
// 若span为待清除状态,且能修改为正在清除的状态
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
// 状态修改成功,则将其移至empty
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
// 清理后,跳转到havespan
goto havespan
}
// span处于正在清除状态,则跳过
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
// 此时,span不在需要清理,因此直接分配之
// we have a nonempty span that does not require sweeping, allocate from it
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
goto havespan
}
// 再尝试从empty中分配
for s = c.empty.first; s != nil; s = s.next {
// 若span为待清除状态,且能修改为正在清除的状态
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
// we have an empty span that requires sweeping,
// sweep it and see if we can free some space in it
c.empty.remove(s)
// swept spans are at the end of the list
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
freeIndex := s.nextFreeIndex()
// 清理后判断是否有空闲对象
if freeIndex != s.nelems {
// 若有,则分配之
s.freeindex = freeIndex
goto havespan
}
lock(&c.lock)
// the span is still empty after sweep
// it is already in the empty list, so just retry
goto retry
}
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
// 已经找不到有未分配对象的span了
// already swept empty span,
// all subsequent ones must also be either swept or in process of sweeping
break
}
if trace.enabled {
traceGCSweepDone()
traceDone = true
}
unlock(&c.lock)
// 调用c.grow(),尝试从mheap中申请span
// Replenish central list if empty.
s = c.grow()
if s == nil {
return nil
}
lock(&c.lock)
c.empty.insertBack(s)
unlock(&c.lock)
// At this point s is a non-empty span, queued at the end of the empty list,
// c is unlocked.
havespan:
if trace.enabled && !traceDone {
traceGCSweepDone()
}
n := int(s.nelems) - int(s.allocCount)
if n == 0 || s.freeindex == s.nelems || uintptr(s.allocCount) == s.nelems {
throw("span has no free objects")
}
// Assume all objects from this span will be allocated in the
// mcache. If it gets uncached, we'll adjust this.
atomic.Xadd64(&c.nmalloc, int64(n))
usedBytes := uintptr(s.allocCount) * s.elemsize
atomic.Xadd64(&memstats.heap_live, int64(spanBytes)-int64(usedBytes))
if trace.enabled {
// heap_live changed.
traceHeapAlloc()
}
if gcBlackenEnabled != 0 {
// heap_live changed.
gcController.revise()
}
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8
// Init alloc bits cache.
s.refillAllocCache(whichByte)
// Adjust the allocCache so that s.freeindex corresponds to the low bit in
// s.allocCache.
s.allocCache >>= s.freeindex % 64
return s
}
mcentral.grow函数
根据mcentral的span类别,尝试从mheap中申请一个新的span
// grow allocates a new empty span from the heap and initializes it for c's size class.
func (c *mcentral) grow() *mspan {
// 根据mcentral的span类别计算申请的span页数和大小
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
// 从mheap中申请一个新的span
s := mheap_.alloc(npages, c.spanclass, false, true)
if s == nil {
return nil
}
// 计算可保存的元素个数
// Use division by multiplication and shifts to quickly compute:
// n := (npages << _PageShift) / size
n := (npages << _PageShift) >> s.divShift * uintptr(s.divMul) >> s.divShift2
s.limit = s.base() + size*n
heapBitsForAddr(s.base()).initSpan(s)
return s
}
mheap.alloc函数
// alloc allocates a new span of npage pages from the GC'd heap.
//
// Either large must be true or spanclass must indicates the span's
// size class and scannability.
//
// If needzero is true, the memory for the returned span will be zeroed.
func (h *mheap) alloc(npage uintptr, spanclass spanClass, large bool, needzero bool) *mspan {
// Don't do any operations that lock the heap on the G stack.
// It might trigger stack growth, and the stack growth code needs
// to be able to allocate heap.
var s *mspan
systemstack(func() {
// 在系统栈上调用mheap.alloc_m
s = h.alloc_m(npage, spanclass, large)
})
if s != nil {
if needzero && s.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(s.base()), s.npages<<_PageShift)
}
s.needzero = 0
}
return s
}
mheap.alloc_m
锁住mheap,并调用allocSpanLocked分配span
// alloc_m is the internal implementation of mheap.alloc.
//
// alloc_m must run on the system stack because it locks the heap, so
// any stack growth during alloc_m would self-deadlock.
//
//go:systemstack
func (h *mheap) alloc_m(npage uintptr, spanclass spanClass, large bool) *mspan {
_g_ := getg()
// 为防止堆增长过快,在分配n页空间前,先回收至少n页空间
// To prevent excessive heap growth, before allocating n pages
// we need to sweep and reclaim at least n pages.
if h.sweepdone == 0 {
h.reclaim(npage)
}
lock(&h.lock)
// 更新mcache上的统计信息到中心memstats
// transfer stats from cache to global
memstats.heap_scan += uint64(_g_.m.mcache.local_scan)
_g_.m.mcache.local_scan = 0
memstats.tinyallocs += uint64(_g_.m.mcache.local_tinyallocs)
_g_.m.mcache.local_tinyallocs = 0
// 申请span,allocSpanLocked要求堆已上锁
s := h.allocSpanLocked(npage, &memstats.heap_inuse)
if s != nil {
// Record span info, because gc needs to be
// able to map interior pointer to containing span.
atomic.Store(&s.sweepgen, h.sweepgen)
h.sweepSpans[h.sweepgen/2%2].push(s) // Add to swept in-use list.
s.state = mSpanInUse
s.allocCount = 0
s.spanclass = spanclass
if sizeclass := spanclass.sizeclass(); sizeclass == 0 {
s.elemsize = s.npages << _PageShift
s.divShift = 0
s.divMul = 0
s.divShift2 = 0
s.baseMask = 0
} else {
s.elemsize = uintptr(class_to_size[sizeclass])
m := &class_to_divmagic[sizeclass]
s.divShift = m.shift
s.divMul = m.mul
s.divShift2 = m.shift2
s.baseMask = m.baseMask
}
// Mark in-use span in arena page bitmap.
arena, pageIdx, pageMask := pageIndexOf(s.base())
arena.pageInUse[pageIdx] |= pageMask
// update stats, sweep lists
h.pagesInUse += uint64(npage)
if large {
// 如果是大对象,则更新大对象相关统计信息
memstats.heap_objects++
mheap_.largealloc += uint64(s.elemsize)
mheap_.nlargealloc++
atomic.Xadd64(&memstats.heap_live, int64(npage<<_PageShift))
}
}
// heap_scan and heap_live were updated.
if gcBlackenEnabled != 0 {
gcController.revise()
}
if trace.enabled {
traceHeapAlloc()
}
// h.spans is accessed concurrently without synchronization
// from other threads. Hence, there must be a store/store
// barrier here to ensure the writes to h.spans above happen
// before the caller can publish a pointer p to an object
// allocated from s. As soon as this happens, the garbage
// collector running on another processor could read p and
// look up s in h.spans. The unlock acts as the barrier to
// order these writes. On the read side, the data dependency
// between p and the index in h.spans orders the reads.
unlock(&h.lock)
return s
}
mheap.allocSpanLocked
尝试从mheap.free中寻找匹配的span,若未找到则向OS申请
// Allocates a span of the given size. h must be locked.
// The returned span has been removed from the
// free structures, but its state is still mSpanFree.
func (h *mheap) allocSpanLocked(npage uintptr, stat *uint64) *mspan {
// 尝试从mheap.free中找到匹配的span
t := h.free.find(npage)
if t.valid() {
goto HaveSpan
}
// 若未找到,则向OS申请npage内存
if !h.grow(npage) {
return nil
}
// 再尝试从mheap.free寻找匹配的span
t = h.free.find(npage)
if t.valid() {
goto HaveSpan
}
throw("grew heap, but no adequate free span found")
HaveSpan:
s := t.span()
if s.state != mSpanFree {
throw("candidate mspan for allocation is not free")
}
// First, subtract any memory that was released back to
// the OS from s. We will add back what's left if necessary.
memstats.heap_released -= uint64(s.released())
if s.npages == npage {
h.free.erase(t)
} else if s.npages > npage {
// 若得到的span空间大于npage,则用多余的空间生成一个新的span,并置于mheap.free中
// Trim off the lower bits and make that our new span.
// Do this in-place since this operation does not
// affect the original span's location in the treap.
n := (*mspan)(h.spanalloc.alloc())
h.free.mutate(t, func(s *mspan) {
n.init(s.base(), npage)
s.npages -= npage
s.startAddr = s.base() + npage*pageSize
h.setSpan(s.base()-1, n)
h.setSpan(s.base(), s)
h.setSpan(n.base(), n)
n.needzero = s.needzero
// n may not be big enough to actually be scavenged, but that's fine.
// We still want it to appear to be scavenged so that we can do the
// right bookkeeping later on in this function (i.e. sysUsed).
n.scavenged = s.scavenged
// Check if s is still scavenged.
if s.scavenged {
start, end := s.physPageBounds()
if start < end {
memstats.heap_released += uint64(end - start)
} else {
s.scavenged = false
}
}
})
s = n
} else {
throw("candidate mspan for allocation is too small")
}
// "Unscavenge" s only AFTER splitting so that
// we only sysUsed whatever we actually need.
if s.scavenged {
// sysUsed all the pages that are actually available
// in the span. Note that we don't need to decrement
// heap_released since we already did so earlier.
sysUsed(unsafe.Pointer(s.base()), s.npages<<_PageShift)
s.scavenged = false
}
// 更新heapArena中的span信息
h.setSpans(s.base(), npage, s)
*stat += uint64(npage << _PageShift)
memstats.heap_idle -= uint64(npage << _PageShift)
if s.inList() {
throw("still in list")
}
return s
}
mheap.grow
// Try to add at least npage pages of memory to the heap,
// returning whether it worked.
//
// h must be locked.
func (h *mheap) grow(npage uintptr) bool {
ask := npage << _PageShift
nBase := round(h.curArena.base+ask, physPageSize)
if nBase > h.curArena.end {
// 当前arena未有足够的空间,则需要额外分配更多的arena空间
// Not enough room in the current arena. Allocate more
// arena space. This may not be contiguous with the
// current arena, so we have to request the full ask.
// 从OS中申请arena空间
av, asize := h.sysAlloc(ask)
if av == nil {
print("runtime: out of memory: cannot allocate ", ask, "-byte block (", memstats.heap_sys, " in use)\n")
return false
}
if uintptr(av) == h.curArena.end {
// 若新分配的arena紧接着当前arean,则直接append到原arena后面
// The new space is contiguous with the old
// space, so just extend the current space.
h.curArena.end = uintptr(av) + asize
} else {
// 若并非紧挨着,则将多余的空间,生成成span插入mheap.free
// The new space is discontiguous. Track what
// remains of the current space and switch to
// the new space. This should be rare.
if size := h.curArena.end - h.curArena.base; size != 0 {
h.growAddSpan(unsafe.Pointer(h.curArena.base), size)
}
// 切换到新的arena空间
// Switch to the new space.
h.curArena.base = uintptr(av)
h.curArena.end = uintptr(av) + asize
}
// The memory just allocated counts as both released
// and idle, even though it's not yet backed by spans.
//
// The allocation is always aligned to the heap arena
// size which is always > physPageSize, so its safe to
// just add directly to heap_released. Coalescing, if
// possible, will also always be correct in terms of
// accounting, because s.base() must be a physical
// page boundary.
memstats.heap_released += uint64(asize)
memstats.heap_idle += uint64(asize)
// Recalculate nBase
nBase = round(h.curArena.base+ask, physPageSize)
}
// 分配nBase-v大小的空间,生成span并回填mheap.free
// Grow into the current arena.
v := h.curArena.base
h.curArena.base = nBase
h.growAddSpan(unsafe.Pointer(v), nBase-v)
return true
}
mheap.growAddSpan
根据新的空间创建新的span,回填入mheap.free中
// growAddSpan adds a free span when the heap grows into [v, v+size).
// This memory must be in the Prepared state (not Ready).
//
// h must be locked.
func (h *mheap) growAddSpan(v unsafe.Pointer, size uintptr) {
// Scavenge some pages to make up for the virtual memory space
// we just allocated, but only if we need to.
h.scavengeIfNeededLocked(size)
s := (*mspan)(h.spanalloc.alloc())
s.init(uintptr(v), size/pageSize)
h.setSpans(s.base(), s.npages, s)
s.state = mSpanFree
// [v, v+size) is always in the Prepared state. The new span
// must be marked scavenged so the allocator transitions it to
// Ready when allocating from it.
s.scavenged = true
// This span is both released and idle, but grow already
// updated both memstats.
h.coalesce(s)
h.free.insert(s)
}
学到了什么
- 本地线程缓存,提高性能:通过mcache缓存小对象的span,并优先在mcache中分配,避免锁损耗
- 无处不在的BitMap应用场景:通过二进制位来映射对象,例如mspan.allocBits用以表示对象是否分配
- 多层级的分配策略:自低向上,性能损耗由低到高,频繁度则由高到低,因此能有效提高性能。思想上类似CPU中的多级缓存
总结
本文主要介绍了Go内存分配中的一些重要组件以及分配算法。可以看到,其主要思想还是基于TCMalloc的策略,将对象根据大小分类,并使用不同的分配策略。此外,还采用逐层的内存申请策略,大大提高内存分配的性能。
此外,在分配过程中,穿插了各种GC相关的代码,因此Go的内存分配是与GC紧密相连的,这我将在GC篇中详解。
参考
- https://google.github.io/tcmalloc/
- http://goog-perftools.sourceforge.net/doc/tcmalloc.html
- https://medium.com/@ankur_anand/a-visual-guide-to-golang-memory-allocator-from-ground-up-e132258453ed
- https://www.cnblogs.com/zkweb/p/7880099.html
- https://www.cnblogs.com/luozhiyun/p/14349331.html
- https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-memory-allocator/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号