【读书笔记】设计数据密集型应用-第三部分
第10章-批处理
系统分类:
- 服务(在线系统):服务等待客户端的请求或指令到达。会尽快地返回结果
- 批处理系统(离线系统):拥有大量的输入数据,通过跑一个job来处理它,并生成输出数据
- 流处理系统(near-real-time system):stream job operates on events shortly after they happen, whereas a batch job operates on a fixed set of input data
使用unix工具的批处理
使用unix工具处理日志文件:
cat /var/log/nginx/access.log | #1
awk '{print $7}' | #2
sort | #3
uniq -c | #4
sort -r -n | #5
head -n 5 #6
使用程序处理:
counts = Hash.new(0) # 1
File.open('/var/log/nginx/access.log') do |file|
file.each do |line|
url = line.split[6] # 2
counts[url] += 1 # 3
end
end
top5 = counts.map{|url, count| [count, url] }.sort.reverse[0...5] # 4
top5.each{|count, url| puts "#{count} #{url}" } # 5
上述两者对比?
- 当不同的URL数量较小时,程序处理较好。因为它读入内存的hash表
- 当数据量非常大时。命令行更好,因为sort命令会通过溢出磁盘的技术适配大数据,且能利用磁盘顺序IO的性能优势
Unix哲学
- 让程序只做好一件事。新功能新程序,而非添加功能
- 每个程序的输出都能成为另外一个程序的输入。即程序只是数据的过滤器
- 尽早地设计构建原型
- 优先使用工具来减轻编程任务,即使是曲线救国的方式
Unix 如何实现的组合性?
统一的接口
Unix中使用文件(fd)来表示,它只是一串有序的字节序列。
(web中则使用URL作为接口)
分离逻辑与布线
用户可以以他们想要的方式链接输入与输出,而该程序不知道也不关心从哪里输入、后又输出到哪里
透明度和实验
Unix 工具非常易于调试。
Unix命令的输入文件通常被视为不可变。这样你可以随意尝试,而不会损坏原始数据
可以在任何时候结束管道,这很便于调试。
可以某个阶段的数据输出保存到文件中,并可以使用该文件作为下一阶段的输入。
MapReduce和分布式文件系统
MapReduce就像Unix工具一样,不过是分布在数千台机器上。
MapReduce的job通过在分布式文件系统上写文件来作为类似Unix中的stdin和stdout
MapReduce任务执行
处理模式:
- 读取一组input文件,并拆解成记录(records)。
- 调用mapper函数,从每条记录中提取一对键值对。
- 按照键来排序所有键值对(MapReduce默认执行)
- 调用reduce函数编列排序后的键值对。
Mapper
负责从input文件中提取键值对
Reducer
MapReduce框架拉去由mapper生成的键值对,收集同一键的所有值,并在改值列表上迭代调用reducer
分布式执行
数据的分布由框架层负责,基本上采用一种就近原则:即会在存有input文件副本的节点上执行mapper,可以节省网络传输数据的开销。
对于reducer,通过对键哈希以确保相同键的键值对会被传递到同一reducer。
键值对必须排序,通常是按阶段排序。只要mapper读取完input文件,并写完排序后的output文件后,reducer就会开始获取output文件。
reducer获取文件,合并且保留有序性,最后对记录处理。
MapReduce工作流
如同Unix命令一样,单个MapReduce任务作用有限,通常是多个任务组合成工作流。
MapReduce并不原生支持,而是用过input&output文件(目录)来实现。且默认是前一个MapReduce任务完全结束后才能开始下一个
Reduce-Side Join and Grouping
如何处理join以及group呢?(类似SQL中的)
join
例如user_info <-> user_activity_event表:
通常是获取user_info的一个副本,并放置与user_activity_event表所在机器的文件系统上,最后再执行任务。
Sort-meger join: 通过归并排序的方式,reducer将两个mapper的output合并
将相关的数据放在一起
group by
设置mapper,使得它生成的键值对是以目标分组键为键。随后分区和排序过程将所有相同键的记录传递到reducer。
处理倾斜数据?
由于存在热点数据的情况(如处理明星相关的分组),会导致负载不均等问题。如何处理?
- 预先跑一份样本数据来判断哪些键是热点键
- 显示指定热点键
然后使用随机话的策略来减轻热点数据的分区
Map-Side Join
Brocadcast hash join
两个连接输入之一很小,所以它并没有分区,而且能被完全加载进一个哈希表中。因此,你可以为连接输入大端的每个分区启动一个Mapper,将输入小端的散列表加载到每个Mapper中,然后扫描大端,一次一条记录,并为每条记录查询散列表。
Partitioned hash joins
如果两个连接输入以相同的方式分区(使用相同的键,相同的散列函数和相同数量的分区),则可以独立地对每个分区应用散列表方法。
批处理工作流的输出
- 建立索引:批处理处理文档并输出索引
- 键值存储:批处理处理数据并输出键值对到数据库(或者写入文件,数据库程序再读文件)
批处理输出的哲学
任何先前的输出都被新的输出完全取代,且无任何副作用。
Hadoop和分布式数据库的对比
存储多样性
Hadoop会以原始的形式手机数据,后续再处理数据模型的设计。而传统数据库必须提前设计好数据模型
不加区分的数据存储转移了负担:数据集生成者不需要强制转换为标准格式,数据的解释称为消费者的问题(如文档数据库)
处理模型多样性
由于可以自定义编写各种处理函数,因此可以处理各种各样的数据模型
针对频繁故障的设计
两种设计思路:处理故障和使用内存磁盘的方式。
批处理是离线任务,故障敏感,因此不像MPP那样终止整个查询,而是以单个任务的粒度重试。
而且总是积极地将数据写入磁盘,一方面是容错另一方面是弥补能存不足
为何这样设计?是因为故障率往往会很高,不仅是硬件错误,更是软件问题(如k8s之类的优先级任务,应用不广)
MapReduce 之后
物化中间状态
materialization(物化):将中间状态写入到文件的过程
MapReduce通常是全量物化,缺点?
- 任务只能在前置任务都完成后才能执行
- mapper往往是多余的,例如简单地读取reducer生成的数据
- 数据副本针对临时文件往往是多余的
工作流引擎
将工作流显示地建模为数据从多个处理阶段通过,这样的系统成为数据流引擎(dataflow engines)
与MapReduce的不同(优点)?
- 没有所谓的mapper、reducer。而是将每个函数成为operators(算子),引擎听过各种选项来链接各个算子
- 排序只在必要的地方执行
- 没有不必要的mapper
- 算子可以在数据就绪后就开始,而不是等待前置任务完全完成
容错
通过将中间状态保存在文件系统上,故障时,通过其他节点的可用数据重新,若还不行则重新计算原始数据。
如何实现该机制?
-
例如SPARK使用RDD来跟踪数据是如何计算的(使用了哪些分析,用来哪些算子等)
-
必须知道计算是否是确定性的,即给出相同输入,是否输出相同输出。若不确定,则下游算子将无法处理矛盾。通常对于不确定的算子,一般是杀死下游算子,并重新计算
-
针对大数据量的,则可以物化中间态。减少开销
关于物化
类比Unix,MapReduce是将每个命令的输出写入文件来实现。
而如同flink之类的,则是基于管道思想,将算子的增量传递给其他算子,而无需等待输入完成。
图与迭代处理
针对图的数据模型,如何处理?
Pregel处理模型
思想:一个顶点“发送消息“给另一个顶点,通常这些消息沿着图的边进行发送。
每次迭代,为每个顶点调用一个函数,将所有发送给它的消息再传递给他。不断迭代直到图处理完毕(与图处理算法的递归闭包处理方式类似)
容错
当开始下一个迭代时,前置的迭代必须完全结束,且所有消息都必须拷贝到所有其他顶点
高级API和语言
像声明式转变
尝试性地加入声明式是可行的,应用只是简单地说明那些链接是必须的,查询优化器绝地如何最好地执行链接。
引入声明式的部分,又保有原来的自定义算子的方式,将大大提高可用性。
总结
批处理:input数据是有界的,是一个已知的,固定大小的数据集合。
而流处理则是无界的,即,你任然有一个任务,但是输入数据是无限的
第十一章-流处理
第十二章-数据系统的未来
数据集成
分布式事务 VS 数据派生
总体上来说,数据派生更为方便可行。应该尽量少用分布式事务(性能、运维难等)
流处理与批处理
两者相辅相成,需要统一
lambda architecture
The core idea of the lambda architecture is that incoming data should be recorded byappending immutable events to an always-growing dataset, similarly to event sourc‐ing
Unbundling Databases
Composing Data Storage Technologies
拆分数据库,并用derived data or log-based event来组合,可以适用于单个软件无法满足的大规模的系统。
Designing Applications Around Dataflow
Separation of application code and state
not putting application logic in the database andnot putting persistent state in the application
Mutable data ofthen only be poll periodically. subscribe change not support very well
Stream processors and services
Subscribing to a stream of change: 相对更优,性能也更加,无需网络调用。未来可能是趋势
querying the current state whenneeded: 需要额外的网络调用。(对应于微服务架构)
Observing Derived State
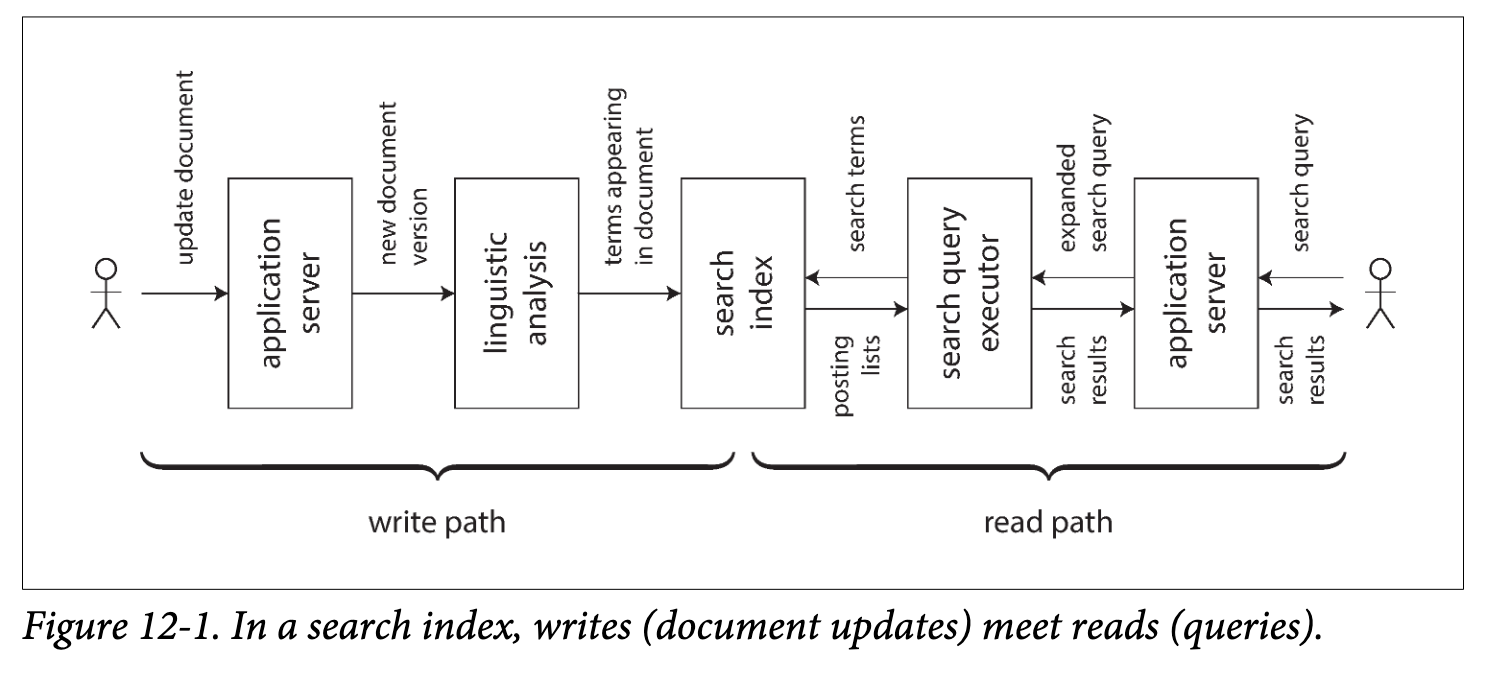
The derived dataset is the place where the write path and the read path meet
Write path: The write path is the portion of the journey that is precomputed
Read path: The read path is the portion of the journey that only happenswhen someone asks for it
Aiming for Correctness
事务作为一种老的方式,可行,但是还不够(例如网络问题造成的用户重试,两次请求是独立的事务)
End-to-end是一种比较理想的方式,用一个request-id来实现,但是抽象程度还不够
Enforcing Constraints
使用单主来保证一致性,leader负责一致性检测。功能有限,单节点异常风险
log-based:基于log实现,对标识hash,所有事件都会被哈希到同一分片上,然后使用stream processor同步执行判断。只能针对唯一性
多分区下(例如username, address),使用end-to-end request-id,由主要分区的stream processor派生出其他分区的message
Timeliness and Integrity(及时性和完整性)
In many business contexts, it is actually acceptable to temporarily violate a constraintand fix it up later by apologizing
Trust, but Verify
事务并不想它所保证的那样安全,并不一定能保证数据的完整性
使用end-to-end才是最终解决方案:
If we can check that an entire derived datapipeline is correct end to end, then any disks, networks, services, and algorithmsalong the path are implicitly included in the check.
如何实现end-to-end check?
使用密码学方面的工具,类似区块链技术里的哈希树算法,为每个event生成唯一标识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号