【读书笔记】设计数据密集型应用-第一部分
第一章
可靠性
针对系统的容错设计,提高系统错误的抛出率,而不是忽略它(除了安全这种不可恢复类型的),尽量避免failure
硬件错误
- 硬件自身容许设计
- 软件系统的灵活性与弹性。即容许整台机器异常,而不影响系统
软件错误
- 影响范围大,连锁反应,排查难。bug,依赖服务错误等
- 避免:考虑全面,全面测试,处理隔离,监控
人类错误
- 最小化犯错机会的方式设计系统,全面测试,允许从错误中恢复,监控
Scaliability(可扩展性)
-
Load描述,又称load parameters:CPU, 内存,网络等因素,这取决于系统的设计
-
性能描述:通常使用percentiles(百分位数),99th, 98th等。
- 监控度量percentiles: 使用计算窗口,即保存窗口时间内的数据,并计算排序。其他算法,forwar decay、t-digits等也可
-
应对Load:
- 纵向扩展:升级到更高性能的机器
- 水平扩展:将Load分摊到多台相似的虚拟机上
-
扩展性是针对特定的假设来设计的,而假设可能是错误的。因此在应用初期,应该采取功能快速迭代的方式,而非基于假设的去支持扩展
Maintainability(可维护性)
- Operability,可操作&运维性:提供监控指标、文档、好的默认配置、好的工具等
- Simplicity,Managing Complexity:通过抽象降低复杂度
- Evolvability,Making Change Easy:敏捷的工作模式,TDD,重构
第二章:数据模型和查询语言
关系型模型VS文档型模型
- 一对多关系:关系型使用外键;而文档型使用JSON-LIKE来表示树状结构(更方便)
- 多对一、多对多:两者并无区别,都是使用
relation model(a relation(table) is simply a collection of tuples(rows))而非network)(hierachical) model(with access path) - 对比:
- shcema灵活度:文档型更佳(schema-on-read),数据结构是隐式的,只有读取时才会翻译出来。于关系型(write-on-read)
- 查询局部性优化:文档型更佳。关系型也能支持
数据的查询语言
- 声明式,例如SQL(database)、CSS&HTML(web),MapReduce(分组聚合,例如mongDB中的aggregate)。
- 命令式,例如通过函数查询。声明式更为推荐
图数据模型
对于多对多较多,我们一般使用关系型模型,然而随着数据之间联系变得复杂,数据模型为图模型则更佳
属性图
在属性图模型中,每个顶点(vertex)包括:
- 唯一的标识符
- 一组 出边(outgoing edges)
- 一组 入边(ingoing edges)
- 一组属性(键值对)
每条 边(edge) 包括:
- 唯一标识符
- 边的起点/尾部顶点(tail vertex)
- 边的终点/头部顶点(head vertex)
- 描述两个顶点之间关系类型的标签
- 一组属性(键值对)
Cypher声明式查询语言,语法方便简洁。举例
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
Triple-Stores and SPARQL
三元组模型:(subject, predicate, object),(主,谓,宾)结构。例如(Jim, likes, bananas)
DataLog
是上述Cypher以及SPARQL之类查询语言的基础。通过在查询中组合以及递归重用相同的规则来实现查询,尤其针对复杂查询
小结
- 演化:one big tree(hierarchical) -> relation-model(because of many-to-many) -> NoSQL -> Graph
- 文档数据库通常应用于one-many或者无关系的数据场景
- 而图数据库,则应用于任何数据都可能与其他数据有关系(与文档数据库都是schema less)
- 尽管一种模型可以模拟另外一种模型,但是实际用起来往往很糟糕。因此要选择合适的
第三章 存储与检索
常见存储模型:log-structured, page-oriented
使用append-only data file的模式,可快速实现一个数据库,很多数据库都使用这一原理。
- 更新或者添加记录,都会在文件末尾append一条log。写入性能优
- 然而查询时,需要遍历所有记录。读取性能差
- 因此不得不引入索引,索引是一种取自原始数据(一般是元信息)额外的数据结构。
- 但是维护索引需要额外性能,尤其是写入时。因此需要根据查询模式,构建索引,达到权衡
HASH Index
使用hash表来存储索引(in-memory),其中键为实际key, 值为文件中实际记录的offset。
如何处理磁盘空间不足?将log文件划分为多个指定长度文件段(segment),当达到长度阈值时,则起一个后台线程进行压缩,并同时合并不同的segment
其他实践细节
- 文件格式。使用2进制
- 删除记录。删除时,标记为tombstore(假删除),在合并压缩过程进行实际删除
- crash recovery。通过保存索引的快照,实现快速重启。
- Partially written records。支持checksum,可检测并忽略异常部分
- 并发控制。写操作保持同步,只允许一个线程进行写操作
Why append-only file 而不是直接更改文件
- 写操作总是有序的,可避免乱序写,从而提升性能(磁盘硬件原因,磁道扫描等)
- 并发和异常崩溃更简单
- 压缩合并机制可避免存储容量问题
缺点
- Hash table 必须in memory。因此大量key-value等情况难以适合,尽管能利用磁盘,但是会大大提升复杂度并降低性能
- range queries 效率低
SSTables and LSM-Trees
更改文件格式,将所有segments中的键值对按照键进行排序。从而改进append-only file模式
优点
- 合并segments非常简单且高效。使用归并排序的算法实现,且当存在同名key,我们保留最近segment中的key
- 无需将索引的keys都保存在内存中。大可只保留部分key的索引,依然key是有序的,则只需找到目前key前后的两个key的索引,获取offset在期间扫描即可
- 提高写入性能。我们可以将记录分组,然后在写入前压缩
- range query 效率很高
构建与维护
我们在内存中维护SSTable,通过使用树管理(红黑树、AVL-Tree)
-
在写入时,添加到tree中。in-memory tree called a memtable
-
当memtable大于一定阈值时,则将其作为SStable file保存在磁盘中(期间,我们新起一个memetable实例)
-
在读取时,按照memtable->recent SSTable file-> older-SSTable file的属性查找
-
在一定的时机,进行合并与压缩
缺点
- 意外崩溃时,会造成in-memory memtable内容丢失。可通过额外一个的append-only log file来避免
性能优化点
- Slow when looking up keys tha do not exist in the database. 可通过Boolm filters来解决
- 压缩合并的时机。分为
size-tired以及leveled两种策略
B-Trees
B-trees break the database into fixed-size blocks or pages.
Each page can be identified using an address or location。a B-tree with n kesy always has a depth of O(logn)。
使B-tree更可靠
- 由于b-tree在写入时,是直接修改page的,期间发生崩溃容易造成一些异常(例如,孤儿页)。引入redo log
- 并发控制,
优化
- 页中只存储key的摘要,节省空间
- pages能被放置在磁盘任意位置。为避免,会在写入时,重新排布tree。
- 添加额外的指针,例如连接叶子页,从而避免过多的跳转
其他索引
- primary key index。例如标识关系数据库中的row,图数据库中的顶点
- secondary indexes。例如关系数据库中以某列(user_id)作为索引。很容易通过key-value索引构建
- index中存储值。例如聚簇索引(indexed row store in index),覆盖索引(聚簇&非聚簇的折中,存indexed row的部分列)
- 多列索引。concatenated index(连接索引), 将多个列组合而成,只能按照前后顺序生效
- multi-dimensional(多维索引)。更为通用
- 全文搜索和模糊索引;内存数据库
事务处理或分析?
数据处理模式。
- OLTP(online trasaction processing)。常见于交易、登录等事务,面向用户
- OLAP(online transaction processing)。报表分析、聚合等,面向分析人员
Data Warehousing
OLTP系统通常需要保持高可用、低延迟,而直接对OLTP所用的数据库查询分析,容易产生不良影响。且OLTP相关数据库的索引也往往不适合OLAP
ETL(extract-transform-load):Warehouse将其他系统的数据收集过来,转换analysis-friendly模式,清理并加载导入到data warehouse
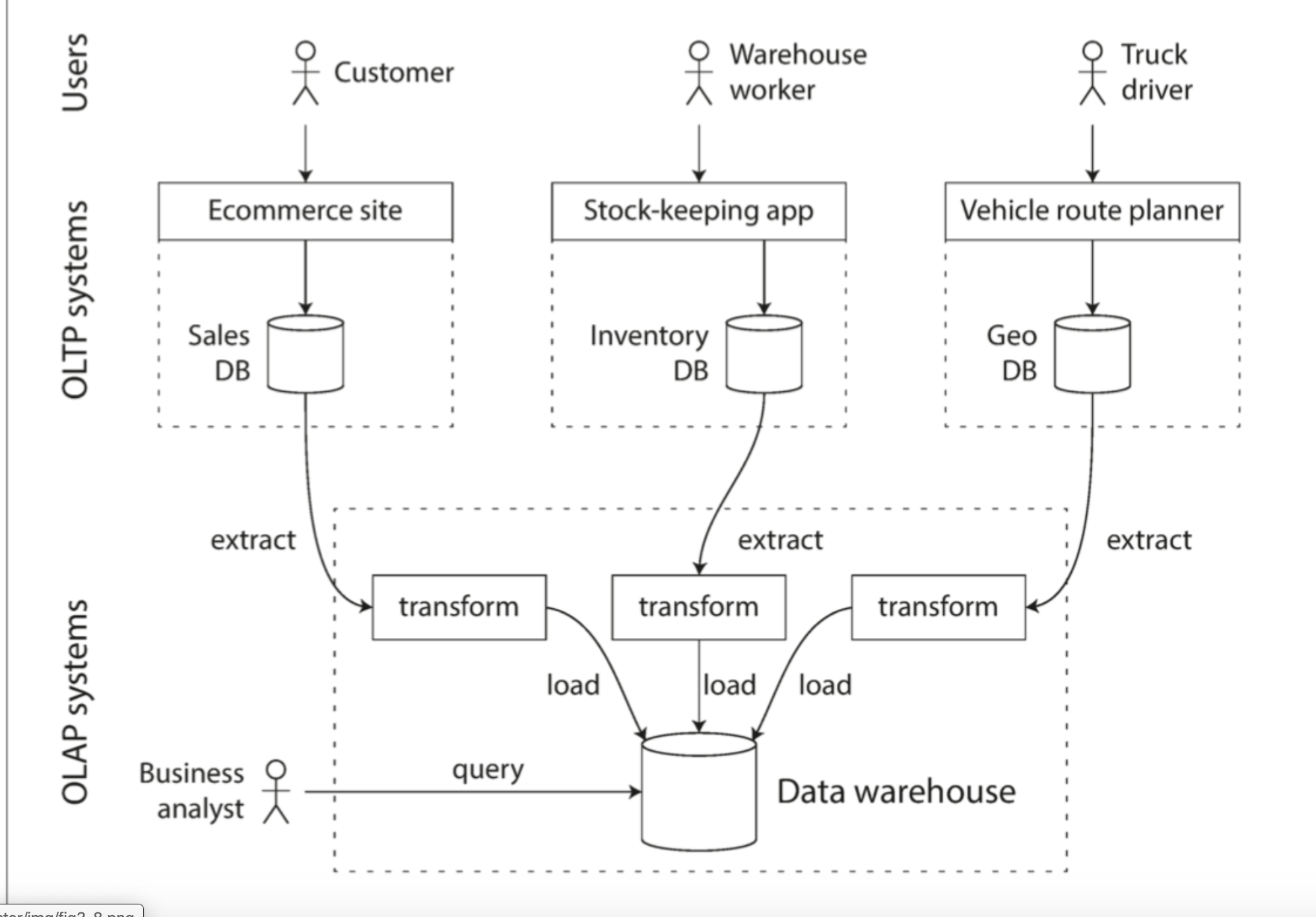
小公司业务量小,并不需要整套系统,简单SQL、报表分析工具都可以。
Schemas for Analytics
- star schema: 实际的表处于中心,被它不同维度的信息表包围,它们之间的连接就如同星星
- Snowflake schema: star schema的扩展,将周围表划分为更多的子维度表(少用)
Column-Oriented Storage
将所有的值按照列区分开并各自单独存储在一起,而非将所有列的值合并为行存储。
因为分析往往只针对个别列,以行为维度存储会读取不必要的列数据
例如,
column_1_key file contents: 1,2,3
column_2_key file contents: tom,jerry,john
Column Comparession
使用bitmap encoding技术
列存储的排序
排序后,有助于压缩,以及查询
列存储的写入
所有的写入,首先会写入内存,添加到一个排序好的结构中,然后准备被写入磁盘(而非像B-Tree一样直接修改pages)
聚合
Materiablized view: 针对sum、count等一类聚合后的结果数据的缓存。
Data cubes: 多维度的聚合缓存优化(例如商品的名称、购买日期两个维度,构成一个data cubes)。针对特定的查询很快(预先计算好了),例如每年的购买商品量
第四章-编码与更新
应用总是在不断更新的,而相关的数据自然也得不断更新。同样,数据格式的更更新也会导致关联应用代码的更新。而应用代码的更新往往更麻烦。
为满足making change easy,我们必须让数据的更新满足,向前兼容以及向后兼容。
数据编码的格式
编码(encoding),将数据从内存表示转换为字节序列的过程。反之,称为解码(decoding)
语言特定格式
语言内置的编码格式,例如Python中的pickle等。通常不建议
JSON, XML, and Binary Variants
json, xml都是文本编码,且能自解释的,可读行非常高。
缺点:
- 数据类型缺乏,例如JSON不能区分整数、浮点数
- 不支持二进制类型,不得不用base64转换,而这将导致增加额外33%的数据大小
题外话,这跟让不同组织达成一致相比都不是缺点:)
二进制变体,如BSON, BJSON等
Trift and Protocol Buffers
当用于组织内部时,推广二进制编码往往没那么多压力。失去了可读性,但是体积更小,编解码更快
Thrift BinaryProtocol

Thrift CompactProtocol(与Protocol Buffers基本相同)

两者相对比:
- CompactProtocol体积更小
- 使用field tag替换字段名
- 使用
variable-length表示数字。每个字节的头个位用来表示后续字节是否同属该数字值
注意,required以及optional标记,只在运行时校验。数据表示均一致。
字段更新时
- 可任意更改字段名,而不能更改tag number。
- 添加一个字段:
- 向前兼容:老代码会直接忽略该字段
- 向后兼容:新字段必须为optional或者有默认值,以便读到老的数据时,可以忽略或取默认
字段类型更新时
- 会有丢失数据或丧失精度的风险。例如整数,32bit -> 64bit。64读到32位填充0,32读到64无法满足而丢弃置空
- ProtobufProtocol中的repeated标记表示同样的field tag出现若干次,可兼容optional
Avro

相较上述Thrift、Protobuf,它没有field tag或者field name,因此必须使用相同的schema来读写。
写入端&读取端,可拥有不同的schema,对于兼容性,可使用default value以及版本号来解决
动态生成schema
Avro可支持动态生成schema,可以方便地通过JSON,数据库表结构等直接生成Acro结构。
而ProtocolBufferdeng则不得不手动修改field tag与列名的映射
数据流的模型
Dataflow Through Databases
写入<->未来读取
向后兼容,否则的话未来的代码将不能读取之前的数据
向前兼容,老的代码可能会使用到新的数据,例如滚动升级
兼容性
数据的写入时间不同,Rewriting(migrationg)的方式,或者填入默认值(使用Avro模型)
使用归档存储
Dataflow Through Services
请求<->返回
多用于在网络之中的传输,例如web service与client,service与service(SOA, 微服务)。
SOAP,REST
- REST更为广泛,路径代表资源,HTTP动词代表操作
- SOAP则使用XML来定义
REST也是源自RPC,不过相较RPC,其不像RPC一样把调用当错内部函数,而更像是个网络协议。
REST用于OPENAPI, 而RPC往往只能用在组织内部。
兼容性
服务端只需要针对request做向后兼容,对response做向前兼容。
- gRPC之类的使用内置的编码格式做兼容
- SOAP使用XML schema做兼容
- RESTful API使用增加可选请求参数,在返回体中添加新字段。最终可使用版本号
Message-Passing Dataflow
可以看做为异步消息传递系统
相较于RPC拥有BUffer作为缓存,提高可靠性。自动重传消息等等
message broker
RabbitMQ, Kafka等等。消息传递给query或topic,broker确保消息传递给了consumers或subscribers。
数据格式:字节序列即可,JSON, ProtoBuf均可。
分布式actor框架
以message broker作为桥梁,连接各个actor,从而提升扩展性,降低复杂性,避免线程、锁等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号