Golang中的map实现
总所周知,大多数语言中,字典的底层是哈希表,而且其算法也是十分清晰的。无论采用链表法还是开放寻址法,我们都能实现一个简单的哈希表结构。对于Go来说,它是具体如何实现哈希表的呢?以及,采取了哪些优化策略呢?
内存模型
map在内存的总体结构如下图所示。
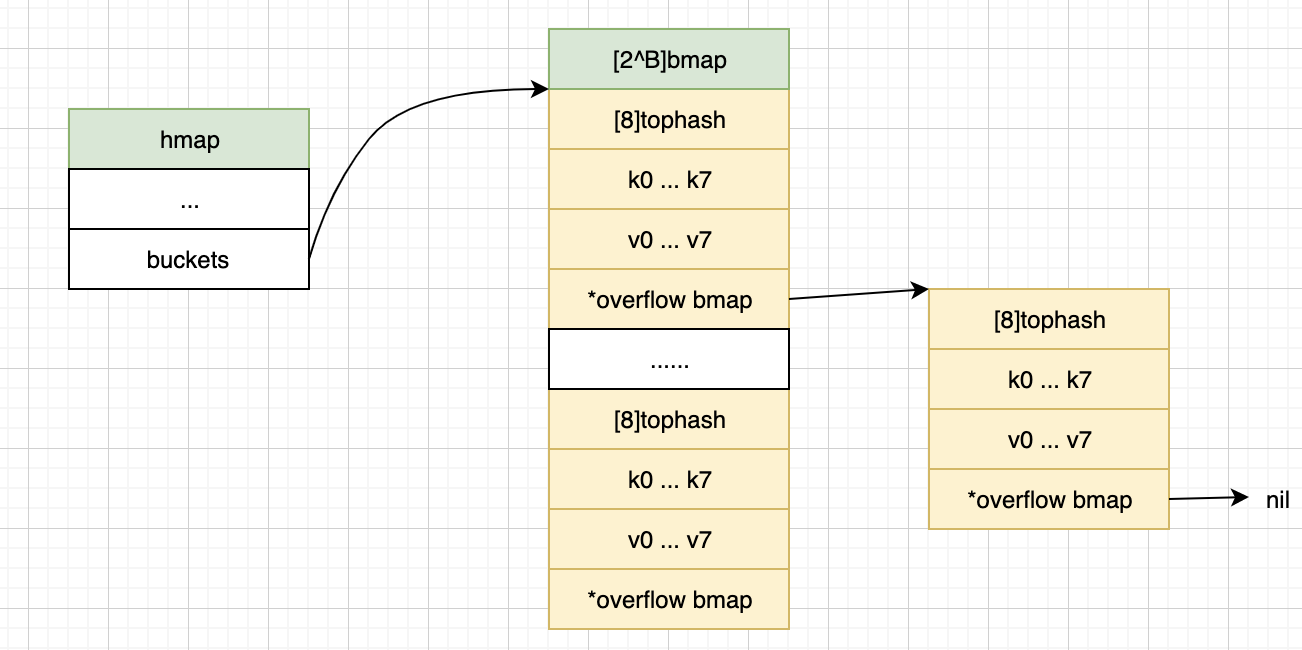
头部结构体hmap
type hmap struct {
count int // 键值对个数
flags uint8
B uint8 // 2^B = 桶数量
noverflow uint16 // 溢出桶的个数
hash0 uint32 // hash seed
buckets unsafe.Pointer // 哈希桶
oldbuckets unsafe.Pointer // 原哈希桶,扩容时为非空
nevacuate uintptr // 扩容进度,地址小于它的桶已被迁移了
extra *mapextra // optional fields
}
hmap即为map编译后的内存表示,这里需要注意的有两点。
- B的值是根据负载因子(LoadFactor)以及存储的键值对数量,在创建或扩容时动态改变
- buckets是一个指针,它指向一个
bmap结构
桶结构体bmap
type bmap struct {
// tophash数组可以看做键值对的索引
tophash [bucketCnt]uint8
// 实际上编译器会动态添加下述属性
// keys [8]keytype
// values [8]valuetype
// padding uinptr
// overflow uinptr
}
虽然bmap结构体中只有一个tophash数组,但实际上,其后跟着8个key的槽位、8个value的槽位、padding以及一个overflow指针。如下图所示

这里,Go做了优化。
- 这里并没有把key/value作为一个entry,而是分开存储。主要是为了节省内存,有时可以避免使用padding(额外的内存)来对齐,比如
map[int64]int8就完全不需要padding。
查找操作
查找操作总体和链表法的哈希表查找类似,即key ---> hashFunc(key) ---> mask(hash) ---> 桶的位置 ---> 遍历链表。其主要代码如下所示
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
// 计算得到桶的位置bucket-k
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 若正在扩容,老buckets则为非空
// 若bucket-k在老的buckets数组中,未被迁移,则使用老的
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// 根据tophash(hash), 在bucket-k中的tophash中查找key
top := tophash(hash)
// 找到对应的bucket后,遍历查找对应的key/value
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
...
// 计算第i个位置的key的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 比较tophash[i]上的k是否与目标key相等
if alg.equal(key, k) {
// 计算value的地址
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue() {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
}
// 若最终还是没找到,则返回nil
return unsafe.Pointer(&zeroVal[0])
}
首先,Go通过对应类型的alg.hash计算得到hash值(各种类型的hash&equal函数定义),取后B位作为buckets数组的下标(实际上为取余),取高8位作为tophash的下标。
然后,通过一个嵌套循环查找目标key:外层循环是遍历一个bmap单链表,它们通过overflow指针相连;内层循环则遍历tophash数组,逐个比较,当匹配成功时,则计算得到实际key的地址,比较两者,成功则返回。如下图所示
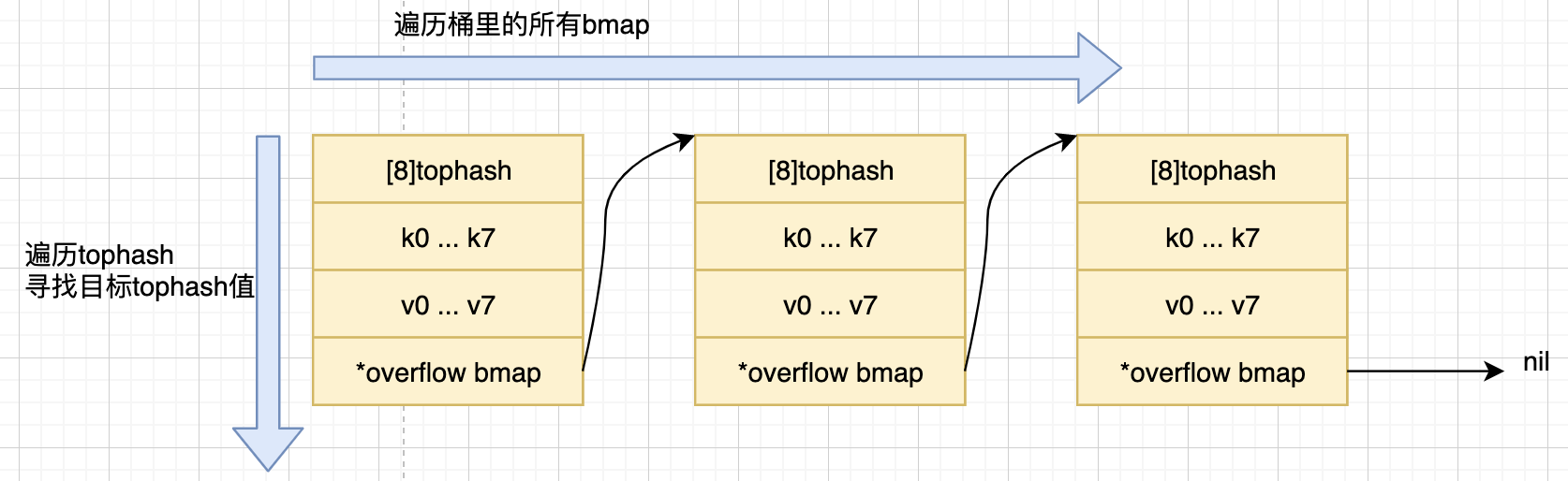
这里,Go做了如下优化。
- 使用tophash数组,作为索引,用以判断key是否存在该bmap中,若确实存在,再使用较为耗时的比较算法判断key是否相等。
除了查找操作,map的插入、删除以及扩容操作也十分值得学习,大家可以去查阅相关源码
本人才疏学浅,文章难免有些不足之处,非常欢迎大大们评论指出。
参考
- https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics#easy-footnote-1-3224
- https://github.com/golang/go/blob/master/src/runtime/map.go
- https://studygolang.com/articles/25134
- https://www.linkinstar.wiki/2019/06/03/golang/source-code/graphic-golang-map/
- [https://github.com/qcrao/Go-Questions/blob/master/map/map 的底层实现原理是什么.md](https://github.com/qcrao/Go-Questions/blob/master/map/map 的底层实现原理是什么.md)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号