
记录一次ChatGPT编写简单Python脚本的过程
最近因公司业务需要从网上找了开源源代码进行了解某领域行业软件,其中有一个项目搭建过程发现数据库文件缺失。
项目为C#源码,进行了分层,打开model文件夹查看实体有一百多个,如果根据实体在一个一个建表的话很要命的一件事情。
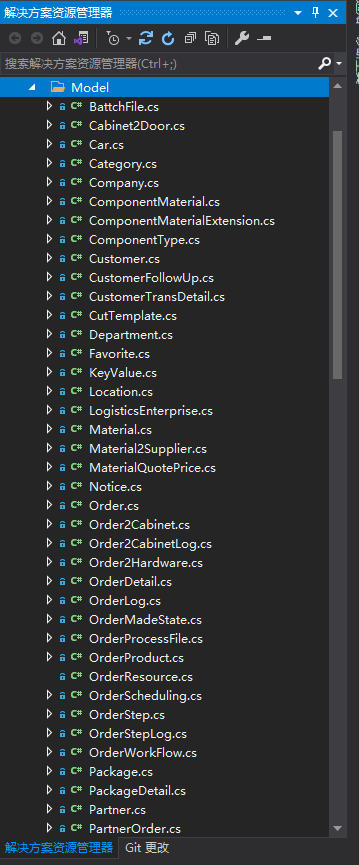
打开实体类文件查看源码发现,在类和属性上有表名与字段名的注解,这就很方便的用脚本进行解析出来了。
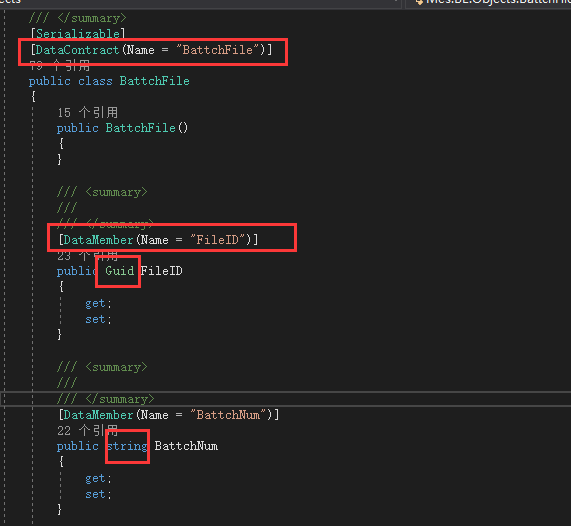
好多年不写代码手脚不利落了,于是乎打开ChatGPT让AI帮忙生成了代码,经过几轮沟通与简单的修改后得到了全部100多个表的生成sql脚本。
生成出来的脚本展示如下:

首先获取了model文件夹下的文件清单进行遍历。
再从每个文件中获取表名,生成create table语句,还做了表是否存在,如果已经存在则先删除。
再逐行读取属性字段,并从下一行中获得类型,拼接数据表字段的脚本。
最后针对格式中多余的逗号进行了修正。
与ChatGPT聊天的完整记录如下,供大家参考学习。

经过简单修改后的代码如下,未进行精心规范化,临时脚本执行一次拿到结果就不用了,没必要过度强迫症。
import os
import glob
import re
def get_cs_files(f_path):
# 拼接文件夹路径和文件扩展名模式
pattern = os.path.join(f_path, '*.cs')
# 使用glob匹配文件路径
csharp_files = glob.glob(pattern)
return csharp_files
def write_lines_to_file(f_path, str):
with open(f_path, 'a', encoding='utf-8') as m_file:
m_file.write(str + '\n')
def extract_table_name(input_string):
pattern = r'DataContract\(Name\s*=\s*"(\w+)"\)'
match = re.search(pattern, input_string)
if match:
return match.group(1)
else:
return None
def extract_field_name(input_string):
pattern = r'DataMember\(Name\s*=\s*"(\w+)"\)'
match = re.search(pattern, input_string)
if match:
return match.group(1)
else:
return None
def create_field_sql(f_type, f_name):
if f_type == 'int':
return "[" + f_name + "] [int] NULL DEFAULT(0),"
elif f_type == 'DateTime':
return "[" + f_name + "] [smalldatetime] NULL DEFAULT (getdate()),"
elif f_type == 'bool':
return "[" + f_name + "] [bit] NULL DEFAULT(0),"
else:
return "[" + f_name + "] [nvarchar](500) NULL DEFAULT (''),"
# 指定文件夹路径
folder_path = 'model'
create_file_name = 'createsql.txt'
# 获取.cs文件清单
cs_files = get_cs_files(folder_path)
# 打印.cs文件清单
# 遍历每个文件并写入到createsql.txt文件中
with open(create_file_name, 'w', encoding='utf-8') as file:
file.write("SET ANSI_NULLS ON\n")
file.write("GO\n")
file.write("SET QUOTED_IDENTIFIER ON\n")
file.write("GO\n\n")
for file_path in cs_files:
print(file_path)
lines = []
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
line_count = len(lines)
for i, line in enumerate(lines):
current_line = line.strip()
next_line = ''
if i + 1 < line_count:
next_line = lines[i + 1].strip()
# [DataContract(Name = "BattchFile")]
table_name = extract_table_name(current_line)
if table_name is not None:
# CREATE TABLE [dbo].[BattchFile](
write_lines_to_file(create_file_name,
"IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].["
+ table_name + "]') AND type in (N'U')) BEGIN DROP TABLE [dbo].[" + table_name + "] END")
write_lines_to_file(create_file_name, "GO")
write_lines_to_file(create_file_name, "CREATE TABLE [dbo].[" + table_name + "](")
field_name = extract_field_name(current_line)
if field_name is not None:
field_type = next_line.replace("public ", "").replace(" " + field_name, "")
field_sql = create_field_sql(field_type, field_name)
write_lines_to_file(create_file_name, field_sql)
write_lines_to_file(create_file_name, ") ON [PRIMARY]")
write_lines_to_file(create_file_name, "GO\n")
lines = []
with open(create_file_name, 'r', encoding='utf-8') as file:
lines = file.readlines()
line_count = len(lines)
for i, line in enumerate(lines):
current_line = line.strip()
next_line = ''
if i + 1 < line_count:
next_line = lines[i + 1].strip()
if next_line.startswith(')'):
lines[i] = current_line.rstrip(',') + "\n" # 去除前一行末尾逗号
with open(create_file_name, 'w', encoding='utf-8') as file:
for line in lines:
file.write(line)
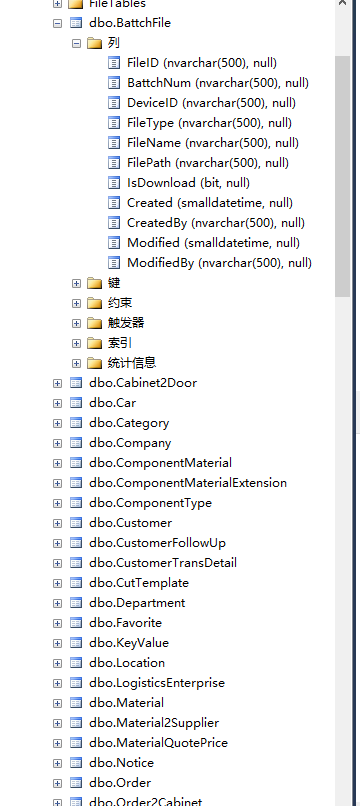
最后展示一下数据库中执行建表的成果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号