mysql的学习
1、主从复制、读写分离
2、MYSQL+keepalive
3、分库分表
4、mysql一个库能承载(1000万~2000万)条记录
行锁:
读锁:共享锁
写锁:排它锁
select 不加锁(会忽略任意锁,不会阻塞)
锁冲突会阻塞的
update、delete、insert会默认加写锁
mysql的页大小16kb
缓冲池默认页的大小是16kb
mvcc机制
间隙锁与健隙锁
隐藏列:row_id,事务id,回滚指针
自增主键有什么好处:b+树的迁移和分裂,空间变大,导致页变多了就是导致树的高度增加,每页存的指针书变少
B+树高度1~3
B+树的首页可以缓冲在内存里面,所以只需要最多进行2次IO操作
联合索引是怎么实现的:
utf8
utf8mb4
order by,group by和索引的关系
当提交事务时,先写重做日志,再修改页。
1、缓冲池:LRU list、FREE list、FLUSH list
2、重做日志缓冲(Checkpoint)
3、两次写操作(主要是解决磁盘文件被破坏以后的解决办法)
MyISAM:
b.frm :描述表结构文件,字段长度等
b.MYD(MYData):数据信息文件,存储数据信息(如果采用独立表存储模式)
b.MYI(MYIndex):索引信息文件。
innodb:
b.frm :描述表结构文件,字段长度等
如果采用独立表存储模式,data\a中还会产生b.ibd文件(存储数据信息和索引信息)
如果采用共存储模式的,数据信息和索引信息都存储在ibdata1中
MYSQL读取数据,一次从磁盘读取一页到内存
MYSQL写回数据,一次把内存中的一页数据刷新到磁盘(checkpoint机制)
缓冲池的管理:
LRU页、Free页、unzip_LRU页、Flush页
重做日志缓冲(每1s向重做日志文件刷新一次)
1、每1s
2、事务提交时
3、重做日志缓冲空间小于2/1时
额外的内存池:
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
checkpoint刷新脏页到磁盘的机制
sharp checkpoint刷新全部脏页
fuzzy checkpoint刷新一部分脏页
缓冲池中缓冲的数据页类型有:数据页、索引页、undo页、插入缓冲、自适应hash索引、innodb存储的锁信息、数据字典信息
数据页、索引页、undo页会受到LRU列表的管理,其他的也是不受LRU算法的管理的
缓冲的页列表:LRU页列表、unzip_LRU页列表、Free页列表
LRU页列表的页被修改后,称之为脏页
Flush列表中的页被称之为脏页
内存包括缓冲池、重做日志缓冲、额外的内存池
重做日志缓冲(向重做日志文件刷新策略)
1、每1s
2、事务提交时
3、重做日志缓冲空间小于2/1时
事务提交时,先做重写日志,再修改页。
重做日志出现不可用的情况是因为当前数据库对重做日志的设计都是循环使用的。
innodb是通过LSN号来标记版本的(页有LSN号、重做日志有LSN号、checkpoint有LSN号)
innodb插入缓冲关键特性:插入缓冲(辅助索引插入且索引不是唯一的)、两次写、自适应hash索引、异步IO、刷新邻接页
自增主键的好处:聚簇索引是按主键进行排序的
聚簇索引是按主键进行排序的,其他索引不是按照主键进行排序的,因此插入索引的时候是离散的
Change buffer是对insert buffer的升级版(对象非唯一的辅助索引)(数据结构就是一颗B+树)
double write(两次写增加可靠性);重做日志是在物理页没有损坏的情况下,如果物理页发生了锁坏,则需要通过double write进行恢复
double write+重做日志(才可以彻底解决可靠性问题)
binlog会记录所有存储引擎下的日志,binlog记录的是逻辑日志,只在事务提交之前写入
redolog只记录innodb下的日志,而redolog记录的是物理页的修改情况,每1s就写入一次
在innodb中,表是根据主键顺序组织存放的
表空间是由段、区、页组成的
段包括数据段、索引段、回滚段
区是由连续页空间组成的,每个区的大小是1MB,一个区有64个页
页内部是通过链表来串联行记录的
B+数索引只能找到记录所在的页,然后会把整个页加载到内存,从页中再找具体的记录
页内的数据结构(page directory二分查找+recorder header链表查找)
每页的Page Directory中的槽是按照主键的顺序存放的,(那么就可以进行二分法查找了)
数据库的B+树的特点是高扇出性
联合索引在什么情况下可以用到:(1)只有where语句;(2)where+order by;(3)where+group by;(4)聚合操作也会走索引,因为这样子减少了IO访问磁盘的次数(覆盖索引)
在SQL查询中也可以强制使用某一个索引(1)FORCE INDEX(索引);(2)USE INDEX(索引)
意向锁以为者事务希望在更细粒度上进行加锁。
MVCC机制是通过undo日志来实现的。(快照机制)
MYSQL对行的查询采用的是Next-Key锁,但是如果查询的索引含有唯一属性时,就会退化为Record-Lock
1、快照读(通过MVCC解决幻读)
2、当前读(通过next-key解决幻读)
在可重复读事务隔离级别下面:采用next-key来加锁
在提交读事务隔离级别下面:采用record-lock加锁
redo log用来保证事务的持久性和原子性
undo log用来保证食物的一致性(实现事务回滚以及MVCC的功能)
redo log是物理日志,回复速度要比(bin log,undo log这种逻辑日志快得多)
undo log也会产生redo log
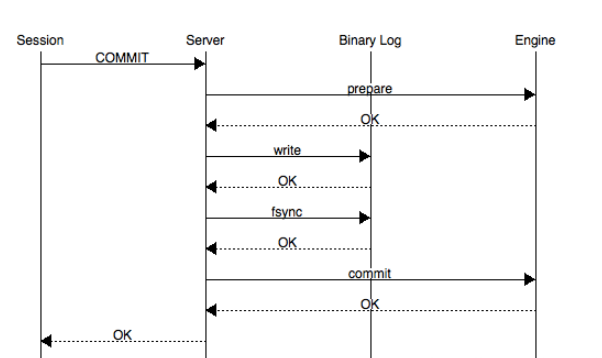
MYSQL的两阶段提交(先写redolog再写binlog)
MYSQL的乐观锁与悲观索的实现:(以现金扣减为例子来说明)
悲观锁的实现:
1、开启事务
2、select cash from table where id =#{id} for update;
3、update table set cash=cash-#{cash} where id=#{id} and cash>=#{cash};
4、关闭事务
乐观锁的实现(增加一个字段版本或者时间戳):
1、select cash,version from table where id =#{id};
2、update table set cash=cash-#{cash},version = version +1 where id=#{id} and cash>=#{cash} and version = #{version};
MYSQL集群的搭建:
1、在主库和备库分别创建账户并赋予一定的权限
2、主库上配置唯一的(server_id,bin_log
3、备库上配置(server_id,bin_log,relay_log,log_slave_updates,read_only)
4、CREATE MASTER TO和START SLAVE
MYSQL的优化
1、索引下推
逻辑读与物理读的区别和怎么知道执行逻辑读和物理读的时间:
1、物理读的单位(16k的物理页)
2、逻辑读的单位(数据库的每一行)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号