云原生下的指标与日志采集
引言:
众所周知,对于一个云原生 PaaS 平台而言,在页面上查看日志与指标是最为基础的功能。无论是日志、指标还是链路追踪,基本都分为采集、存储和展示 3 个模块。
这里笔者将介绍云原生下的常见的指标 & 日志的采集方案,以及 Erda 作为一个云原生 PaaS 平台是如何实将其现的。
指标采集方案介绍
常见架构模式
1. Daemonset
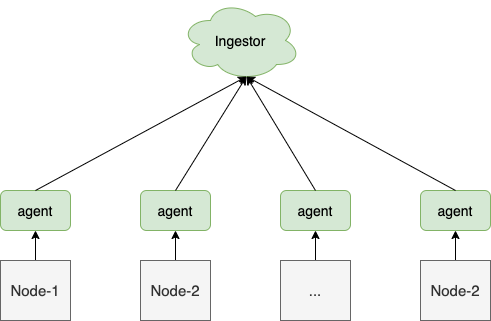
采集端 agent 通过 Daemonset 的方式部署在每个节点上。该模式下,通常是由 agent 主动采集的方式来获取指标,常见的 agent 有 telegraf、metricbeat、cadvisor 等。
应用场景:
- 通常用来采集节点级别的指标,例如:节点资源指标、节点上的容器资源指标、节点的性能指标等。
2. 推 & 拉
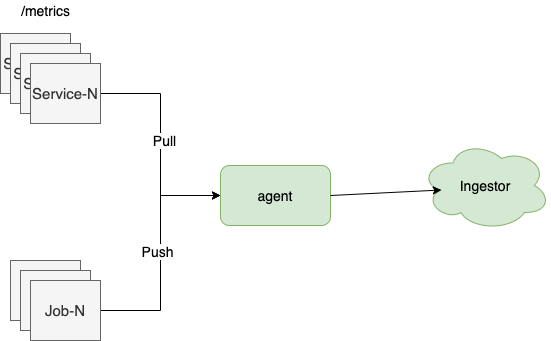
当我们需要采集程序的内部指标时,通常采用 agent 主动拉取指标或客户端主动推送指标的方式。
应用场景:
- 对于 Web 服务、中间件等长时间运行的服务来说,我们一般采用定时拉取的方式采集;
- 对于 CI/CD、大数据等短时任务,则一般是以客户端主动推送的方式采集,例如:推送任务的运行耗时、错误数等指标。
那么,到底是采用推还是拉的方式呢?
我认为这取决于实际应用场景。例如:短时任务,由于 agent 可能还没开始采集它就已经结束了,因此我们采用推的方式;而对于 Web 服务则不存在这个问题,采用拉的方式还能减少用户侧的负担。
开源方案介绍
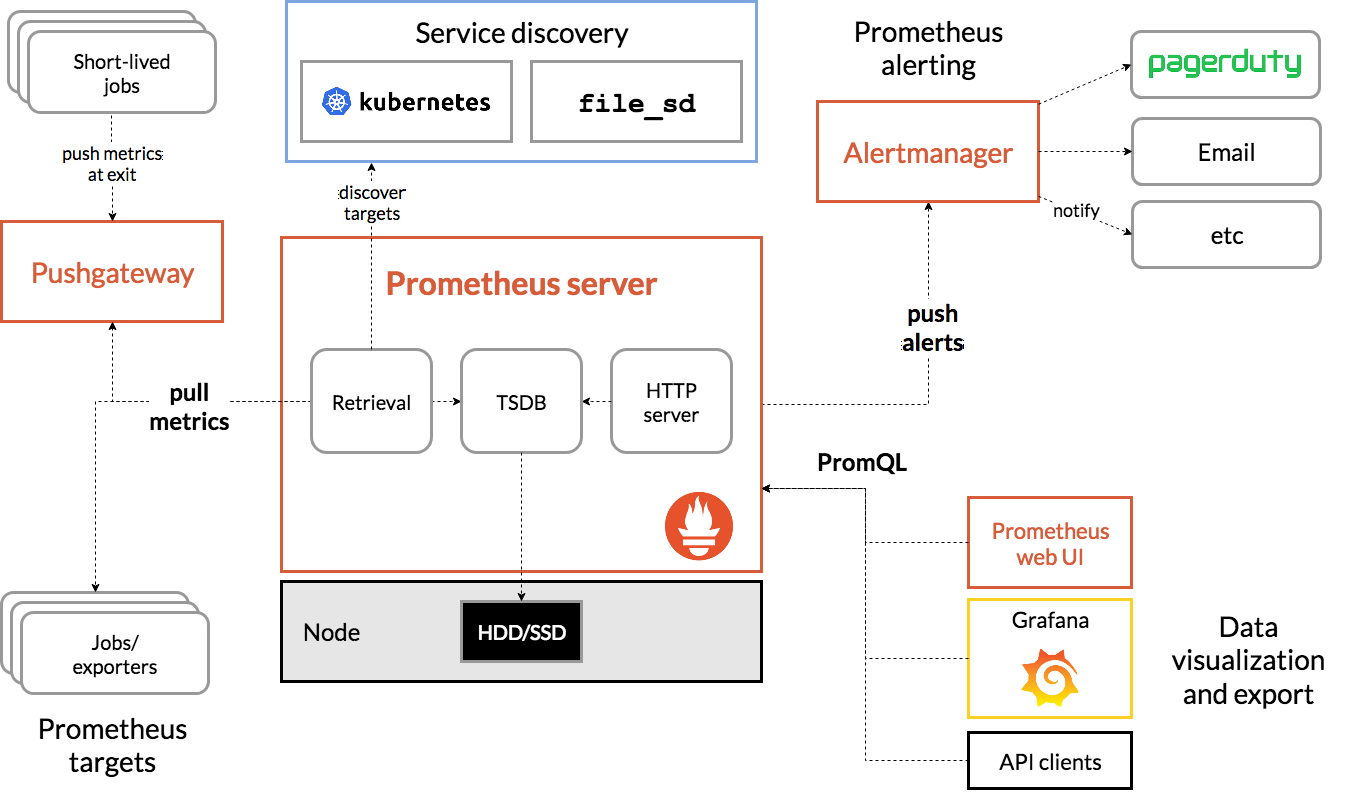
Prometheus 作为 CNCF 的 2 号毕业选手,一出生就基本成为云原生尤其是 Kubernetes 的官配监控方案了。
它实际是一套完整的解决方案,这里我们主要介绍它的采集功能。
- 拉场景下,Prometheus server 中的 Retrieval 模块,负责定时抓取监控目标暴露的指标。
- 推场景下,客户端推送指标到 Pushgateway,再由 Retrieval 模块定时抓取 Pushgateway。
其与推&拉方案基本相同,不过由于其即为丰富的 exporter 体系,基本可以采集包括节点级别的各种指标。
Erda 采用的架构方案
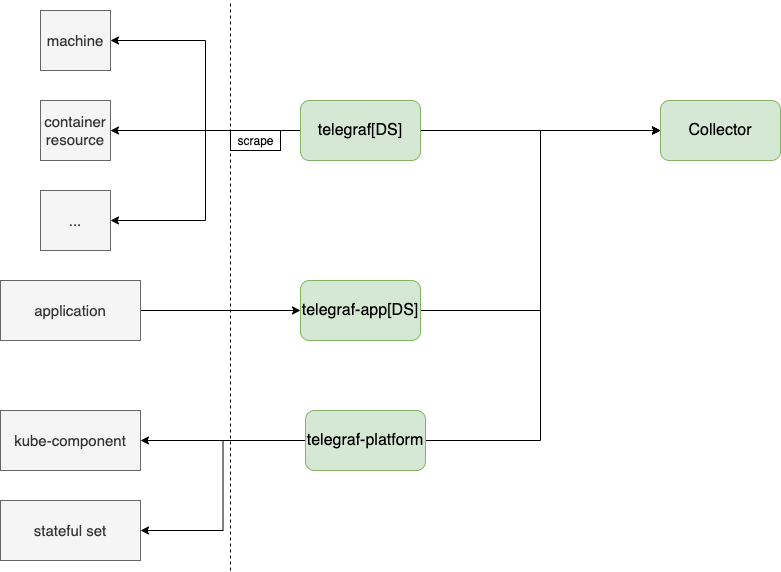
在 Erda 中,当前的方案是通过二开了 telegraf, 利用其丰富的采集插件,合并了 Daemonset 和推拉方案。
- telegraf[DS]:作为Daemonset采集节点级别的指标;
- telegraf-app[DS]:不采集指标,仅用于转发上报 trace 数据;
- telegraf-platform: 采集服务级别的指标;
- collector:收集 telegraf 上报的指标,以及客户端程序主动推送的指标。
日志采集方案介绍
常见架构模式
1. Daemonset
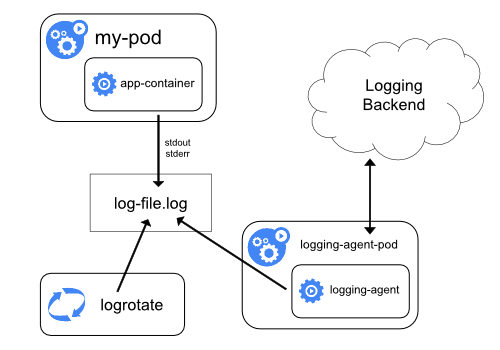
容器内应用的日志若输出到 stdout 中,容器运行时会通过 logging-driver 模块输出到其他媒介上,通常是本机的磁盘上,例如 Docker 通常会通过 json-driver 输出日志到 /var/log/docker/containers/
对于这种场景,我们一般采用 Daemonset 的方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. Sidecar
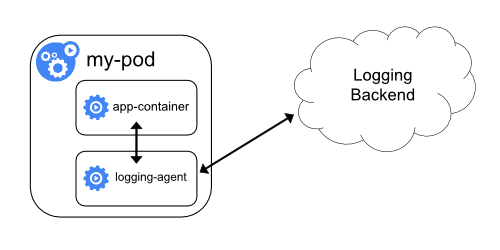
Daemonset 方案也有一些局限性,例如,当应用日志是输出到日志文件时,或者想对日志配置一些处理规则(例如,多行规则、日志提取规则)时。
此时可采用 Sidecar 的方案,通过 logging-agent 与应用容器通过共享日志目录、主动上报等方式来采集。
3. 主动上报
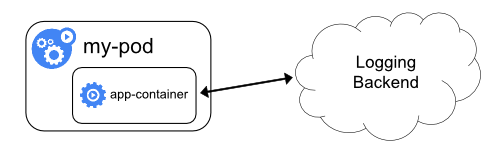
当然,还可以主动(一般通过供应商提供的 SDK)上报日志。
常见应用场景有:
- 当你想转发日志到外部系统时可以使用主动上报的模式,例如,转发阿里云的日志到 Erda;
- 当你不想或者不具备部署任何 logging-agent 时,例如:当你只想试用下 Erda 的日志分析时。
开源方案介绍

业界中,比较有名的就是使用 ELK 来作为日志方案,当然也是整套解决方案。采集模块主要是 beats 作为采集端,logstash 作为日志收集总入口,elasticsearch 作为存储,kibana 作为展示层。
Erda的架构方案
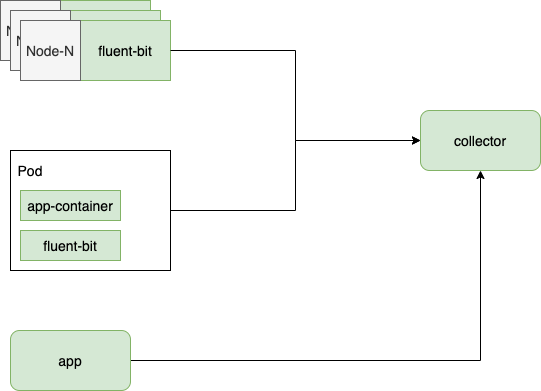
在 Erda 中,我们使用了 fluent-bit 作为日志采集器:
- 针对容器日志:我们采用 Daemonset 的方案进行采集;
- 针对 ECI 等无法部署 Daemonset 的场景:我们采用 Sidecar 的方案采集;
- 针对第三方的日志:我们在 collector 端支持用户的自定义主动上报。
小结
不难看出,无论是指标还是日志,其数据采集方案还是比较简单清晰的,我们可以根据实际场景随意搭配。
然而随着集群规模的增长以及用户自定义需求的增加,往往会出现如下难点:
- 数据洪流问题:如何保障监控数据的时效性以及降低数据传输与存储成本;
- 配置管理问题:如何管理大量的自定义配置,例如自定义指标采集规则、日志多行规则、日志分析规则等等
对于这些问题,我们也在不断探索实践中,并会在后续的文章中进行分享。
参考链接 & 延伸阅读
- https://kubernetes.io/docs/concepts/cluster-administration/logging/
- https://www.elastic.co/cn/what-is/elk-stack
- https://prometheus.io/docs/introduction/overview/#architecture
更多技术干货请关注【尔达 Erda】公众号,与众多开源爱好者共同成长~
文中部分图片源自网络,侵删

 浙公网安备 33010602011771号
浙公网安备 33010602011771号