
正则表达式
来源:http://www.bjsxt.com/
一、正则表达式01_介绍、标准字符集合、自定义字符集合
Regular Expression或Regex 


RegexBuddy 
语法(1) 
语法(2) 
语法(3) 
二、正则表达式02_量词、贪婪和非贪婪模式
语法(4) 
几个常用的非贪婪匹配Pattern*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复
三、正则表达式03_字符边界、匹配模式(单行和多行模式)
语法(5) 
正则表达式的匹配模式 
四、正则表达式04_分支结构、捕获组、非捕获组、反向引用
语法(6) 
五、正则表达式05_预搜索、零宽断言(4个语法结构)
语法(7) 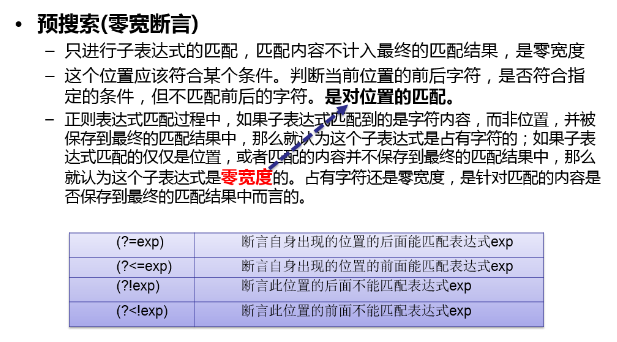
六、正则表达式06_电话号码、手机号码、邮箱、常用表达式
练习1 
格式:010-88889999 0373-8888858 13508888888
(0\d{2,3}-\d{7,9})|(1[35-9]\d{9})
练习2 
[\w\-]+@[a-z0-9A-Z]+(\.[a-zA-Z]{2,4}){1,2}
网络上的 
七、正则表达式07_正则表达式、开发环境、文本编辑器中使用

八、正则表达式08_正则表达式、JAVA编程中使用、查找、替换、分割

1 package com.test.regularExpression; 2 3 import java.util.regex.Matcher; 4 import java.util.regex.Pattern; 5 6 /** 7 * 测试正则表达式对象的基本用法 8 */ 9 public class Demo01 { 10 public static void main(String[] args) { 11 //在这个字符串:ssf9798,是否符合指定的正则表达式:\w+ 12 13 //表达式对象 14 Pattern p = Pattern.compile("\\w+"); 15 16 //创建Matcher对象 17 // Matcher m = p.matcher("ssf99798"); //尝试将整个字符序列与该模式匹配 18 Matcher m = p.matcher("ssss9&&oou433"); 19 20 boolean yesorno = m.matches(); 21 System.out.println(yesorno); //ssf99798为true,ssss9&&oou433为false 22 23 boolean yesorno2 = m.find(); //扫描输入的序列,查找与该模式匹配的下一个子序列 24 //m.matches()为true,匹配完了,则m.find()从字符序列最后位置匹配,为false 25 //m.matches()为false,则m.find()从字符序列开始位置匹配,为true 26 System.out.println(yesorno2); //当前为true 27 28 System.out.println("=====单单测试find()======================================"); 29 Pattern p2 = Pattern.compile("\\w+"); 30 Matcher m2 = p2.matcher("ssss9&&oou433"); 31 // System.out.println(m2.find()); //true 32 // System.out.println(m2.find()); //true 33 // System.out.println(m2.find()); //false 34 35 while(m2.find()){ 36 //group()和group(0)都是匹配整个表达式的子字符串,所以打印内容一样 37 //第一次打印ssss9,第二次打印oou433 38 System.out.println(m2.group()); 39 System.out.println(m2.group(0)); 40 } 41 } 42 }
1 package com.test.regularExpression; 2 3 import java.util.regex.Matcher; 4 import java.util.regex.Pattern; 5 6 /** 7 * 测试正则表达式对象中分组的处理 8 */ 9 public class Demo02 { 10 public static void main(String[] args) { 11 Pattern p = Pattern.compile("([a-z]+)([0-9]+)"); //有两个分组:([a-z]+) 与 ([0-9]+) 12 Matcher m = p.matcher("df43**dfdf545**fdg99"); 13 14 while(m.find()){ 15 System.out.println("====整个子序列============="); 16 System.out.println(m.group()); 17 System.out.println("========子序列的分组==================="); 18 System.out.println(m.group(1)); //([a-z]+) 19 System.out.println(m.group(2)); //([0-9]+) 20 } 21 } 22 }
1 package com.test.regularExpression; 2 3 import java.util.regex.Matcher; 4 import java.util.regex.Pattern; 5 6 /** 7 * 测试正则表达式对象的替换字符串操作 8 */ 9 public class Demo03 { 10 public static void main(String[] args) { 11 Pattern p = Pattern.compile("[0-9]"); 12 Matcher m = p.matcher("aa33**dfd89*dfd87"); 13 14 //替换 15 String newStr = m.replaceAll("#"); 16 System.out.println(newStr); //aa##**dfd##*dfd## 17 } 18 }
1 package com.test.regularExpression; 2 3 import java.util.Arrays; 4 5 /** 6 * 测试正则表达式对象的分割字符串操作 7 */ 8 public class Demo04 { 9 public static void main(String[] args) { 10 String str = "a,b,c"; 11 String[] arrs = str.split(","); 12 System.out.println(Arrays.toString(arrs)); //[a, b, c] 13 14 String str2 = "a9879b8978c9768"; 15 String[] arrs2 = str2.split("\\d+"); 16 System.out.println(Arrays.toString(arrs2)); //[a, b, c] 17 } 18 }
九、正则表达式09_正则表达式、手写网络爬虫、基本原理、乱码处理
1 package com.test.regularExpression; 2 3 import java.io.BufferedReader; 4 import java.io.IOException; 5 import java.io.InputStreamReader; 6 import java.io.UnsupportedEncodingException; 7 import java.net.MalformedURLException; 8 import java.net.URL; 9 import java.nio.charset.Charset; 10 import java.util.ArrayList; 11 import java.util.List; 12 import java.util.regex.Matcher; 13 import java.util.regex.Pattern; 14 15 /** 16 * 网络爬虫取链接(可以不用自己写,已有相关产品,如wget) 17 */ 18 public class WebSpider { 19 public static void main(String[] args) { 20 String destResult = getURLContent("http://www.163.com","gbk"); 21 22 List<String> result = getMatcherSubStr(destResult, "href=\"([\\w\\s./:]+?)\""); 23 24 for (String temp : result) { 25 System.out.println(temp); 26 } 27 } 28 29 /** 30 * 获得urlStr对应网页的源码内容 31 * @param urlStr 32 * @return 33 */ 34 public static String getURLContent(String urlStr,String charset){ 35 StringBuilder sb = new StringBuilder(); 36 try { 37 URL url = new URL(urlStr); 38 39 BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream(),Charset.forName(charset))); 40 41 String temp = ""; 42 while((temp=reader.readLine())!=null){ 43 // System.out.println(temp); 44 sb.append(temp); 45 sb.append("\n"); 46 } 47 } catch (MalformedURLException e) { 48 e.printStackTrace(); 49 } catch (UnsupportedEncodingException e) { 50 e.printStackTrace(); 51 } catch (IOException e) { 52 e.printStackTrace(); 53 } 54 return sb.toString(); 55 } 56 57 public static List<String> getMatcherSubStr(String destStr,String regexStr){ 58 Pattern p = Pattern.compile(regexStr); //取到的超链接的地址 59 60 Matcher m = p.matcher(destStr); 61 List<String> result = new ArrayList<String>(); 62 while(m.find()){ 63 result.add(m.group(1)); //正则表达式中使用了()分组,所以是1 64 } 65 return result; 66 } 67 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号