

FairytaleQA阅读笔记
原文地址
ACL 2022主会长文
Abstract
动机:现有QA数据集较少考察细粒度的阅读技能,such as the understanding of varying narrative elements.(核心就在narrative elements,七种)
文本领域:教育领域,文本来源于幼儿园至八年级学生的narrative comprehension,由教育学专家进行标注。
数据量:问题数10580,来自278篇童话故事,覆盖七种narrative elements.
本数据集既可以用于QA任务,进行细粒度评测;也可以用于QG任务(Question Generation),在本数据集上训练出来的QG模型能够提出更高质量更复杂的问题。
github地址:pengwei-iie/FairytaleQAData: A dataset of over 10000 question and answer pairs written for storybooks. (github.com)(原文中列出的那个地址已经失效)
huggingface中可以直接调用:GEM/FairytaleQA · Datasets at Hugging Face
Introduction
动机:
- 对于QA任务:在QA中,问题的质量也很关键,保证模型应依赖理解能力而非特定的技巧来回答问题。(Comprehension questions should be valid and reliable, meaning that all items are designed to cohesively assess comprehension rather than some other skills. )。教育领域数据的问题正好需要对学生的各项能力进行考察。
- 对于QG任务:由于数据集的构建成本问题,采用QG模型生成问题或者QA对的研究一直在进行。现有的数据集不适于训练QG模型,因为现有数据集不围绕特定的阅读技能从而无法验证所测试的技能到底是什么。所以需要设计一个将各项阅读技能分开考察的数据集。
本数据集围绕narrative,两个原因:
- 本身很重要。narrative comprehension is a high-level comprehension skill. 而且现实应用场景丰富。
- 结构清晰。narrative stories have a clear structure of specific elements and relations among these elements.
本数据集的特点:
- 教育学专家生成。10580个问答对,来源于278个童话故事。
- 问题集中于narrative elements and relations,有可读性和可靠性。
- 问题分为两类:显式和隐式。显式问题的答案可以在文本中直接找到,隐式问题的答案需要高层次的归纳总结能力。对不同难度的问题进行相对平衡的评测(a relatively balanced assessment with questions of varying difficulty)。
- 专家具有专业领域知识,而且数据经过学生认证,真实有效。
本数据集的应用:
- 对于QA任务:一方面,对于现有SOTA的QA模型来说,这个数据集是challenging的(也就是训练表现还有待提高)。另一方面,可用于对模型进行细粒度理解能力的评估。同时提出,现有模型对于因果关系和预测事情走向的推理能力具有较大提升空间。
- 对于QG任务:可作为QG任务的训练集训练模型,使得模型提出更多样复杂的问题。
Related work
QA Datasets Focusing on Narratives
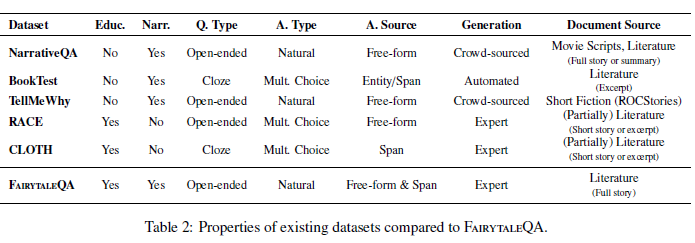
- 最具代表性的是NarrativeQA数据集。
- 特点:crowd workers生成,根据书或者电影的summaries生成QA对,问题主要是事件相关(event-related)
- 缺点:1. workers对于testing students可能经验缺乏。2. reading sub-skills标注不清晰。
- BookTest
- 特点:完形填空式。问题通过从文本中去除名词或者实体来自动生成。
- 缺点:自动生成+完形填空,无法准确考察模型各项阅读能力。
- TellMeWhy
- 特点:集中于因果关系(问题全部由why开头),需要外部知识
- 缺点:文本不完整(comprehension on incomplete story exerpts)
QA Datasets for Reading Education
- RACE数据集
- 特点:多项选择、来源于中学英语考试
- 缺点:
- a mixture of narrative and informational paragraphs,种类标注不清晰,不利于对理解能力的评测
- 文本很短+多项选择->不够challenging
- CLOTH
- 特点:从英语多项选择试题中构建的完形填空式数据集,对educational QG有利
- 缺点:certain limitations inherent to multiple-choice formats
Non-QA Datasets for Narrative Comprehension
这些数据集可用于评估对描述的理解能力。NovelChapters、BookSum等。
存在的问题:
- 理解能力是否能仅仅被总结摘要的水平评估?(评估读或者评估写)
- 只集中于特定的narrative elements,人物或者事件,不够综合全面
FairytaleQA数据集的详细说明
文本来源
- 获取文本:古登堡计划网站上的童话故事,根据下载量决定质量,通过单词替换处理(替换非传统用法及一些引号用法,应该是通过词库),进行阅读难度评级(python包textstat),基于评级结果剔除过难的(太长的或是实在不常用的)。
- 长文本分块:把文本根据语义内容进行分块(sections),每一块是相对完整的由100-300个词组成的故事片段。每个故事平均15个段,每一段平均150个词。这说明本数据集是一个短文本上的任务,文本长度在100-300个词之间。
对问题进行标注的要点:核心在于Narrative Elements or Relations
根据narrative elements划分七种类型:
- Character人物角色(who)
- Setting场景,也就是时间地点(when/where)
- Action行为(应该是what/how)
- Feeling感受,问题中一定包括feel(how did/does/do...feel)
- Causal relations因果关系,强调原因(why or what made/makes)
- Outcome resolution,强调结果(what happened/happens/has happened ... after...),注意:文本中已出现
- Prediction预测,文本中未出现,根据现有文本进行推断
这些类型的存在不是为了让模型学会区分问题类型(分类任务),而是为了generate the variety。
根据答案的来源分为两类:
- Explicit显式,答案可以直接从文本中找到
- Implicit隐式,需要总结摘要,考察推理能力
Using a combination of explicit and implicit questions yields an assessment with more balanced difficulty.
标注过程
专家标注,生成不能用yesno回答的开放式问题,问题的类别(显式隐式以及7种elements)在生成时一并标注。
答案生成:显式的找最短span,隐式的写至少两个答案,同时标记相关section号
数据统计
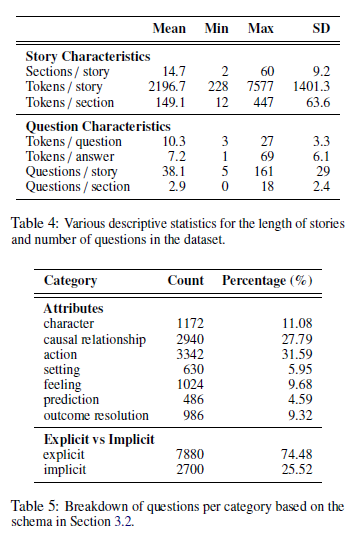
更多见论文
Baseline Benchmark:Question Answering
评估指标:Rouge-L F1 score
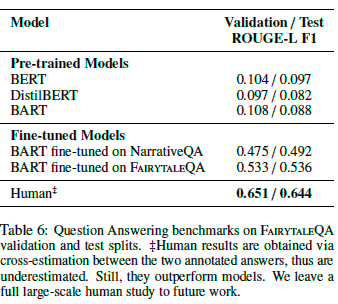
分析待自己复现一下再看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号