

What do Models Learn from Question Answering Datasets?论文阅读笔记
论文原文链接:2004.03490.pdf (arxiv.org)
来源:EMNLP2020,亚马逊的一篇工作
使用的数据集:SQuAD2.0、TriviaQA、Natural Questions、QuAC、NewsQA
Abstract
目标:investigate if models are learning reading comprehension from QA datasets,也就是BERT-based的模型是否从QA数据集中学到了阅读理解的能力。
具体考察指标:(1)generalizability to out-of-domain examples,泛化能力
(2)responses to missing or incorrect data,删除和替换的干扰
(3)question variations,不同类型的问题
结论:现有的数据集和评价方法存在不足。给未来的QA数据集构建提了些建议。将不同数据集的数据格式统一为SQuAD形式。
代码:https://github.com/amazon-research/qa-dataset-converter
Introduction
动机
基于强大的预训练模型,现有的模型在SQuAD1.1、SQuAD2.0上的表现超过了人类,但是这不意味着达到阅读理解任务需要的效果,当面对不连续的答案或是对抗攻击时,表现效果不好,除了在数据集的测试集上打榜,阅读理解模型应该掌握到数据集蕴含的阅读理解能力。本文提出三个问题:(1)在单个QA数据集上的效果能否泛化到新的数据集?(2)模型从QA数据集中是否学会了阅读理解?(3)QA模型能否应对问题的变体(对问题进行一些改变)?
实验方法
在五个QA数据集上进行泛化和鲁棒性的实验。
实验结果
(1)在启发式规则修改的question-context对上,模型泛化效果不好
(2)对数据进行删改不一定总是降低模型的性能,模型能够通过一些简单的方法来获得答案,这说明模型回答答案不一定是通过阅读理解。模型很有可能只学习到了一些启发式规则,例如question-context的重叠程度或是特殊的命名实体。
(3)没有一个数据集能够让模型学会应对问题的复杂变体。
Related Work
- 关于泛化:之前有工作在SQuAD1.1数据集上训练,在另外的四个数据集上泛化。以及MRQA 2019 shared task
- 在数据集中引入不可回答的问题,通过分析question-context overlap来分析泛化的效果
- probing what models learn from datasets:不完整的输入,对于重要的词语的依赖程度,启发式规则的依赖程度等等
由此决定的实验方法:exploring what models learn by comprehensively testing multiple QA datasets against a variety of simple but informative probes
Datasets
主要选择了五个数据集:SQuAD2.0、TriviaQA、Natural Questions、QuAC、NewsQA,都是篇章抽取式的阅读理解数据集。
数据集格式:参考SQuAD 2.0的JSON格式
数据集的比较:
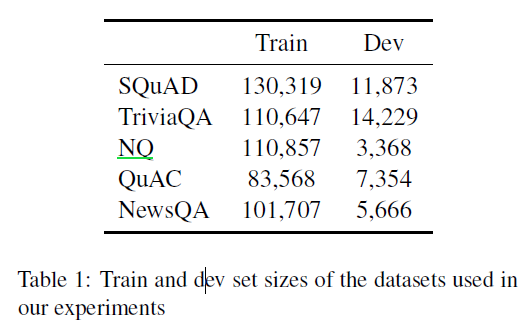
表1:数据量的比较
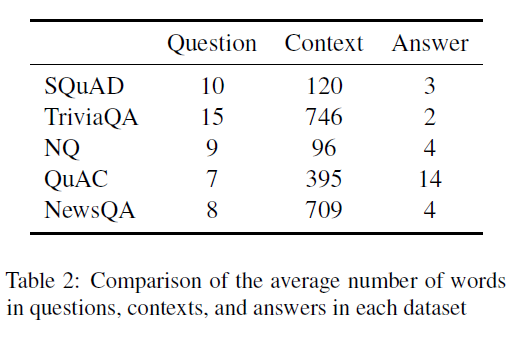
表2:数据长度的比较
以下是每个数据集单独的说明:
SQuAD 2.0
SQuAD2.0是阅读理解的经典数据集了,来源是维基百科+人工标注生成问题,数据量在十五万左右。其中包含大概五万个无法回答的问题。
TriviaQA
2017年提出的数据集,来源是trivia websites的问题-答案对,数据量在九万五左右,本文中主要使用了文档来源是维基百科的部分数据。
Natural Questions(NQ)
2019年提出的数据集,来源是谷歌的搜索记录,数据量为三十万,数据格式包括一个long answer和一个short answer。本文中主要使用了文本数据(排除表格数据等)
QuAC
2018年提出的数据集,来源是维基百科+人工标注,数据量为十万,we do not model contextual information, but we include QuAC to see how models trained without context handle context-dependent questions
NewsQA
2017年提出的数据集,来源是一万篇CNN文章+人工标注,数据量为十万,本文中额外引入了不可回答的问题。
Model
模型选择:BERT-Base uncased,参数量为110M。评测脚本参照SQuAD2.0官方的评测脚本,把验证集当作测试集来验证结果。
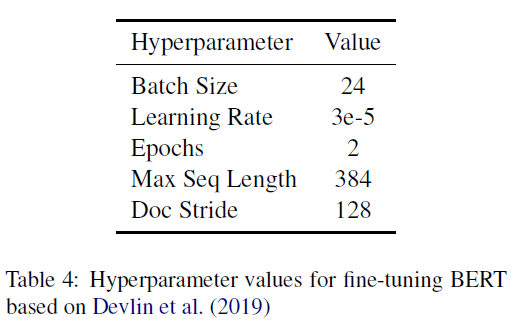
超参数的设置如下:
本文的Baseine结果与已公布的结果的比较:
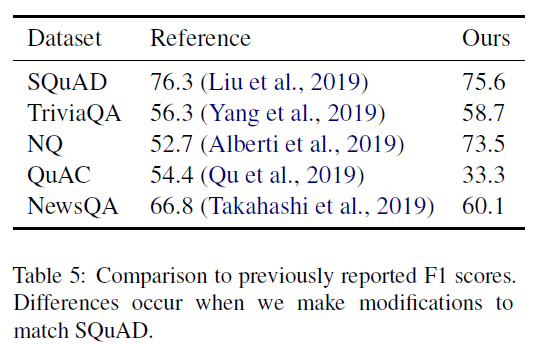
NQ数据集的处理中,去除了long answer的验证,只关注SQuAD格式的short answer task。
QuAC中,去除了上下文相关的。ignored all context-related fields and treated each example as an independent question,所以低了
NewsQA中,引入了不可回答的问题,所以低了
We accept these drops in performance since we are interested in comparing changes to a baseline rather than achieving state-of-the-art results.(科研狗:hhh)
Experiments
5.1 单个QA数据集上的效果能否泛化到新的数据集上?
实验方法:在每个数据集上训练模型,在剩余的其他数据集上evaluate。
实验结果如下:
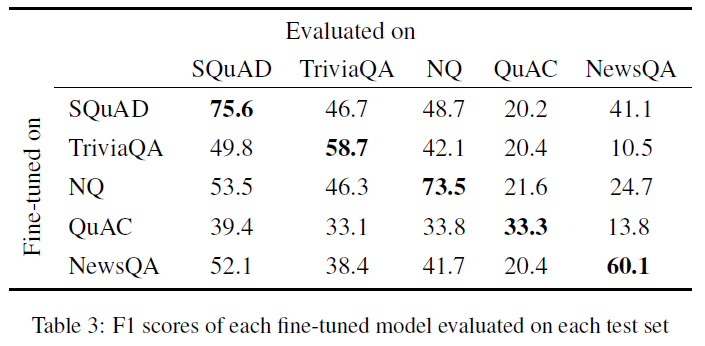
无论是用什么数据集训练的模型,在out-of-domain的测试集上evaluated的时候性能都有下降。这也显示了不同数据集的难度不同。
为了量化数据集的难度,计算了一个比例值,what proportion of each test set can be correctly answered by how many models.用一个柱状图显示。每一个柱子代表一个数据集。柱状图如下:
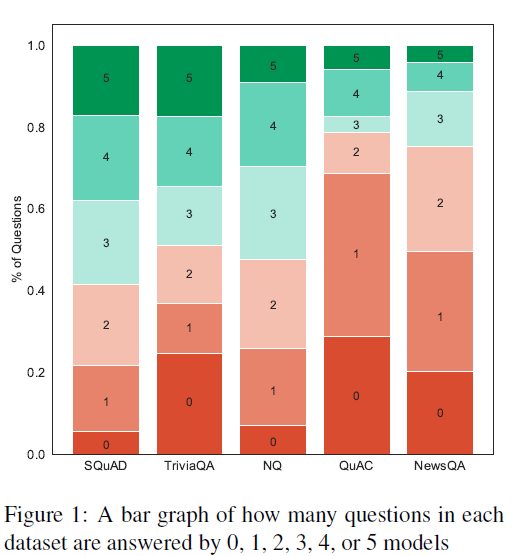
如果正确回答的模型多,把这个问题看作是简单的。
由此看出,五个数据集中NewsQA和QuAC更具有挑战性。
接下来分析问题难度和问题与文本重叠程度的趋势关系。
对于可回答的问题,当higher overlap的时候,更多模型返回正确的答案。

对于无法回答的问题,重叠度越高,越少的模型能够正确做出判断。
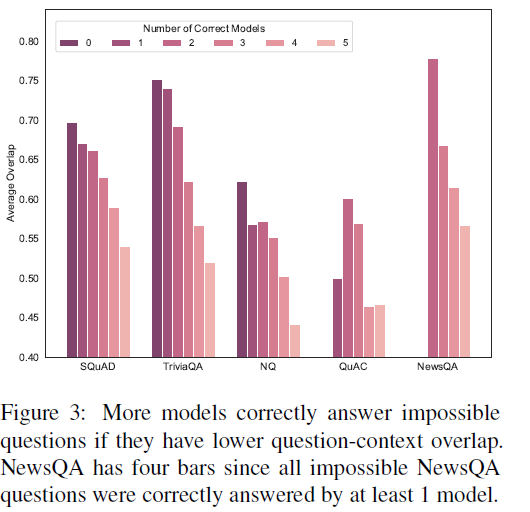
由此得出结论,模型很有可能利用question-context overlap来判别答案,甚至过于依赖这个策略。
构造更有挑战性的数据集:减少question-context overlap
5.2 模型能从QA数据集中学会阅读理解吗?
关键点:模型是否通过捷径而达到了QA数据集上的表现效果,数据集消融实验
三种干扰方式:random labels,shuffled contexts,incomplete questions
样例如下:
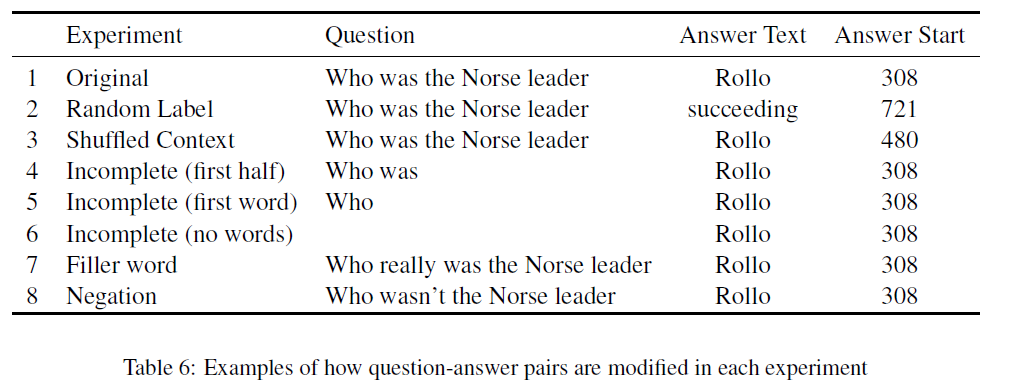
- Random Labels
动机:high level of noise下仍然表现得好,说明学到的有问题。we evaluated how various amounts of noise at training time affected model performance
实验方法:分别随机选择了训练集中可回答数据的10%、50%、90%,把答案换成相同文本中相同长度的一个随机的string。保证随机生成的答案和原始的答案没有任何重叠。在新生成的训练集上训练,在原始的测试集上测试。结果如下:
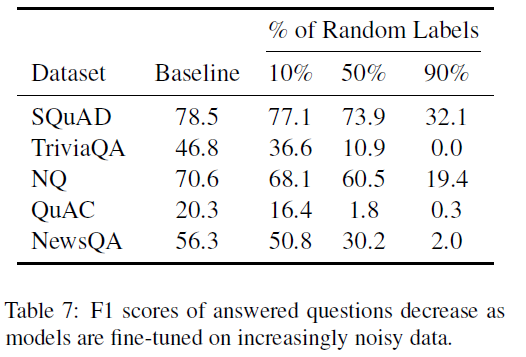
结果分析:当比例为10%的时候,SQuAD、NQ、NewsQA达到了baseline的90%,说明了模型对于合理范围内的噪声具有鲁棒性。TriviaQA和QuAC F1下降的较多,说明在这两个数据集上训练后对于噪声的鲁棒性较差。随着噪声比例提高,F1下降至0.当几乎处于随机状态时,SQuAD达到了baseline的41%,NQ达到了baseline的27%,这说明数据集中有的问题无需阅读理解的能力就可以回答。
- shuffled context
动机:回答问题可能通过理解逻辑或是文章的结构,而不是阅读理解的能力。we investigate how much of model performance can be accounted for without understanding the full passage
实验方法:对于测试集中的数据,把文本按照句子划分,然后随机打乱句子顺序,重组为新的段落,answer的文本不变,但是要更新start token的位置。在原始的训练集上训练,在打乱重组的数据集上evaluate。结果如下:
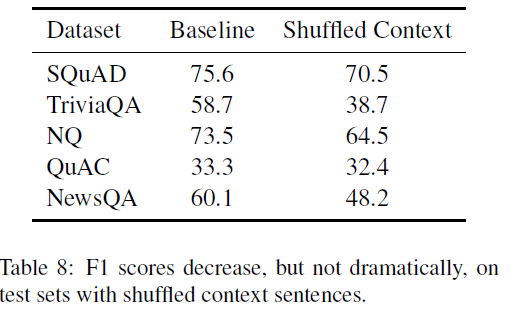
结果分析:TriviaQA掉的更多,其次是NewsQA,SQuAD和QuAC保持的较好。这可能与TriviaQA和NewsQA的文本长度更长有关。
While these results show that models do not rely on naive approaches, like position, they do show that for many questions, models do not need to understand a paragraph’s structure to correctly predict the answer.
- Incomplete Input
动机:模型是否完整的使用了问题?之前的研究显示,在不完整的问题上性能会下降。
实验方法:对测试集的问题进行三种修改——only the first half, first word, or no words from each question。在原始的数据集上训练,在不完整的数据集上evaluate。结果如下:
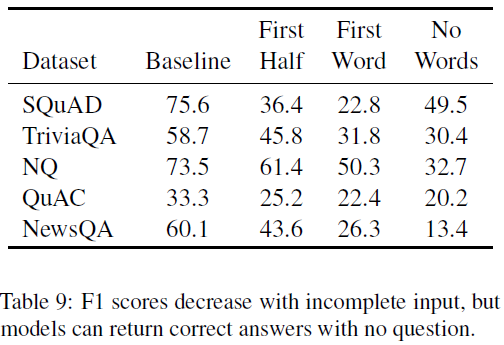
结果分析:在不完整的数据集上测试F1值下降,但没有问题给出时模型仍然能返回正确的答案。在SQuAD数据集上,No Words比First Word高的原因可能是因为在无法回答的问题上的较高成功率。结果显示,并不是所有的样本都需要对问题做出理解后才能正确回答。
基于此,为了探索模型怎样在没有完整问题的情况下做出回答,我们创建了两个NER的baseline,使用spaCy工具,用于检测模型对命名实体的依赖程度。
- First Word NER baseline,使用问题的第一个词来选择实体作为答案。例如:If a question started with “who”, we returned the first person entity in the context, for “when”, the first date, for “where”, the first location, and for “what”, the first organization, event, or work of art.结果如下,除了NewsQA外,能达到40%的baseline。
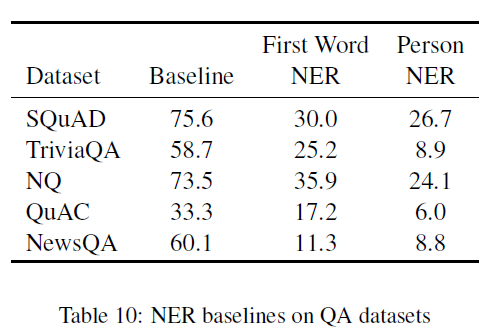
- Person NER baseline,返回文本中的第一个person entity。NQ和SQuAD达到baseline的33%~35%,TriviaQA掉的更多,说明TriviaQA测试集中有更多的命名实体类别。
这说明一些问题可以通过提取命名实体来回答,无需大部分甚至全部的问题文本。
5.3 QA模型能应对问题的变体吗?handle variations in question
模型能否对引入到数据集的噪音保持鲁棒性?主要进行了两个实验:对测试集中的问题加上filler words和negation
- Filler Words
动机:如果QA模型理解一个问题,那么也能够应该理解语义上相同的另一个问题。
实验方法:对于测试集中的每个问题,在主要的动词前随机添加三个filler words(really、definitely、actually)中的一个。在原始数据集上训练,在新的数据集上evaluate。结果如下:
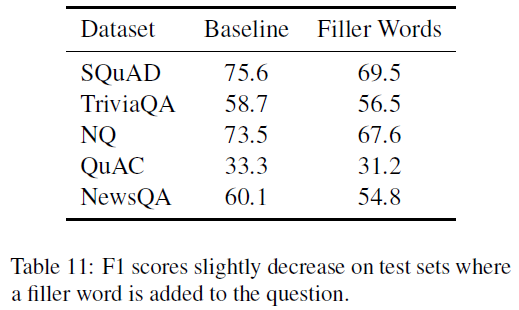
虽然下降的不多,但是这说明简单的干扰就可以使性能下降。
- Negation
动机:negation是QA系统需要理解的重要语法规则,加上简单的negation后问题答案会改变。
实验方法:对于测试集中的每一个问题,把主要的动词加上换成反义的版本,或者在主要的动词前加上never,问题答案保持不变,F1下降的最多说明模型的性能越好。在原始数据集上训练,在新构造的数据集上测试。结果如下:
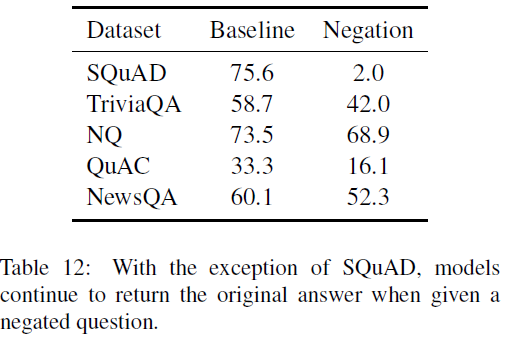
结果分析:结果显示了how often each model continued to return the original answer given a negative question.除了SQuAD,其他数据集训练的模型很大程度上忽视negation。
对SQuAD数据集进一步分析,SQuAD数据集上训练的模型是能够理解negation,还是有bias,对训练集数据的否定词进行统计。
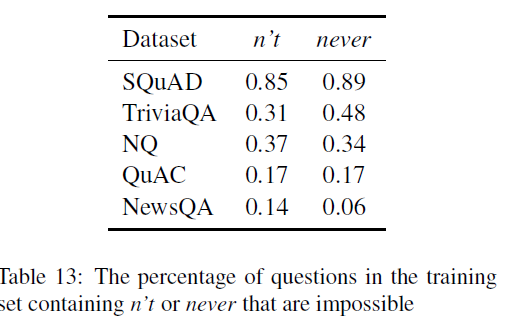
由此得出,SQuAD中存在偏向:否定词更多出现在无法回答的问题中,在可回答的问题中出现较少。SQuAD’s performance is due to an annotation artifact。结论:没有哪个数据集能够使模型学会理解negation
Conclusions
我们在六个任务中使用五个数据集分别进行了实验,由此发现现有的模型did not learn to generalize well, remained suspiciously robust to incorrect or missing data, and failed to handle variations in questions.模型可能通过简单的启发性规则例如question-context overlap或是命名实体或是数据集底部蕴含的模式来提高鲁棒性,but not to valid variations。数据集本身以及评价方法的缺陷使得无法辨别模型是否学会阅读理解。
为以后的QA数据集提一些建议:
- Test for generalizability:新的QA模型应该在几个相关的数据集上都测试结果。
- Challenge the models:问题应该更有难度。去除overlap高的以及提取第一个命名实体的简单问题。
- Be wary of cheating:模型应该能够应对问题的各种形式,包括filler words或是negation
- Standardize dataset formats:统一的数据格式能够使数据集间的迁移更加方便。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号