

Beat the AI:Investigating Adversarial Human Annotation for Reading Comprehension论文阅读笔记
来源:TACL2020
使用到的数据集:SQuAD1.1、DROP、NaturalQuestions,以及自己构造的数据集
Abstract
注释方法的创新已经成为阅读理解 (RC) 数据集和模型的催化剂。挑战当前RC 模型的一个趋势是在注释过程中使用模型:人类以对抗方式创建问题,使得模型无法正确回答这些问题。在这项工作中,我们研究了这种注释方法并将其应用于三种不同的设置,在注释循环中使用逐渐增强的模型(progressively stronger models)收集了总共 36,000 个样本。这使我们能够探索诸如对抗攻击效果的可重复性、transfer from data collected with varying model-in-the-loop strengths以及generalization to data collected without a model等问题。我们发现对对抗性收集的样本进行训练会导致对非对抗性收集的数据集的强泛化,但随着模型在循环中越来越强大,性能逐渐恶化。此外,我们发现更强的模型仍然可以从使用较弱模型在models-in-the-loop收集的数据集中学习。当在循环中使用 BiDAF 模型收集的数据进行训练时,RoBERTa 在 SQuAD 上训练时无法回答的问题上达到了 39.9F1——仅略低于使用 RoBERTa 本身收集的数据进行训练时 (41.0F1)。
1.Introduction
数据收集是基于机器学习的自然语言处理 (NLP) 方法的基本先决条件。数据采集方法的创新,例如众包,在可扩展性方面取得了重大突破,并在“深度学习革命”之前,对机器学习任务有重要的影响。注释方法包括专家注释例如依靠训练有素的语言学家、非专家的众包、远程监督、以及利用文档结构。选择的具体数据收集范式决定了可扩展性的程度、注释成本、精确的任务结构(通常是上述问题的折衷方案)和难度、领域覆盖率,以及由此产生的数据集偏差和模型盲点。
NLP 数据集创建中最近出现的一个趋势是在组成样本时使用model-in-the-loop:现代模型用作过滤器或直接在注释过程中使用,用于识别模型错误预测的样本。 这种方法的示例在Build It Break It、The Language Edition、HotpotQA、SWAG、Mechanical Turker Descent、DROP、CODAH、Quoref和 AdversarialNLI 中都有使用(model-in-the-loop的思想最早可以追溯到2013年,但是最近广为使用)。这种方法探测模型的稳健性并确保生成的数据集对当前模型构成挑战,从而推动研究以解决新的问题。
我们在阅读理解的背景下研究这种方法,并研究其面向不断学习的模型时的鲁棒性——对抗攻击构建的数据集是否会随着模型能力逐渐增强而很快变得过时失去作用?
基于在广泛使用的 SQuAD 数据集上训练的模型,并遵循相同的注释协议,我们研究了注释设置,其中注释器必须编写能让模型预测错误答案的问题。 因此,只有模型未能正确预测的样本才会保留在数据集中——示例见图 1。

图一:循环中带有模型的人工注释,显示:i) “Beat the AI”注释设置,其中仅接受模型未正确回答的问题,ii) 以这种方式生成的问题,注释循环中的模型逐渐增强。
我们将此注释策略应用于循环中的三个不同模型,每个产生具有 12,000 个样本的数据集。然后,我们研究了使用相同数据重新训练模型时对抗效应的再现性,以及使用有和没有对抗模型生成的数据集训练的模型的泛化能力。模型可以在相当大的程度上学习泛化到更具挑战性的问题,基于循环中的强模型或是弱模型收集的训练集都成立。与 SQuAD数据集上的训练相比,在对抗收集问题产生的数据集上的训练在 SQuAD 和 NaturalQuestions 的非对抗性书面问题的泛化程度相似。此外,它还导致我们收集的model-in-the-loop数据集的总体改进,BERT 和 RoBERTa 在 DROP(另一个基于对抗性构造的数据集) 的提取子集上的改进超过 20.0 F1。在对不同模型无法正确回答的具体问题和非对抗性组成的问题时进行系统分析时,我们看到由此产生的问题的性质发生了变化:由循环中的模型构造的问题总体上更加多样化,使用更多的释义、多跳推理、比较和背景知识,并且通常不太容易通过从字面上匹配所需信息的明确陈述来回答。鉴于我们的观察,我们相信model-in-the-loop注释方法显示出前景,并且在创建未来的 RC 数据集时应予以考虑。
总而言之,我们的贡献如下:首先,基于三个逐渐强大的模型对 RC 数据收集的model-in-the-loop方法进行调查,以及在由不同强度的对抗构建的数据集上训练时的经验性能比较 . 其次,对由一系列逐渐强大的模型组成的无法解决的问题的性质进行比较研究。 第三,研究对抗效果的可重复性和在各种环境设置中训练的模型的泛化能力。
2. Related Work
构建有挑战性的数据集
最近在数据集构建方面的努力推动RC(reading comprehension阅读理解)取得了相当大的进步,但数据集结构多样,注释方法也各不相同。 SQuAD1.1因其庞大的规模和自由形式的问题、篇章抽取型的答案,已成为一个既定的基准,它激发了一系列类似结构的数据集构建。然而,越来越多的证据表明,模型仅仅依靠表面线索就可以实现强大的泛化性能——例如词汇重叠、术语频率或实体类型匹配。因此,构建模型认为具有挑战性的数据集已成为越来越重要的考虑因素,而且自然语言理解是泛化的必要条件。实现这一重要目标的尝试通常围绕对 SQuAD 数据集注释方法的扩展展开。它们包括无法回答的问题,添加了“是”或“否”答案选项,需要对多个句子或文档进行推理的问题 ,需要规则解释或上下文意识的问题,先通过寻找问题来限制注释器段落的曝光(limiting annotator passage exposure by sourcing questions first),通过包含日期、数字或问题范围的选项来控制答案类型,以及具有自由形式答案的问题。
对抗性注释
最近采用的一种构建具有挑战性的数据集的方法涉及使用对抗模型来选择它表现不佳的示例,这种方法从表面上看类似于主动学习。在这里,我们区分了对抗性注释的两个子类:i)对抗性过滤,其中对抗性模型作为一个单独阶段应用,通常在数据生成之后,示例包括 SWAG、ReCoRD、HotpotQA和 HellaSWAG; ii)model-in-the-loop对抗性注释,其中注释器可以在注释过程中直接与对抗模型交互,并使用反馈进一步调整生成过程;示例包括 CODAH、Quoref、DROP、FEVER2.0、AdversarialNLI、以及用于 Quizbowl 任务的工作。
我们主要对后一类(model-in-the-loop对抗性注释)感兴趣,因为这个反馈循环创造了一个环境,在这个环境中,注释器可以直接调整模型以探索其弱点并制定有针对性的对抗性攻击。 尽管之前也有研究对 RC 使用对抗性注释,但他们的注释设置都限制了model-in-the-loop的范围:在 DROP 中,主要是由于强加了特定的答案类型,而在 Quoref 中,则侧重于共指问题,共指问题已经是一个已知的 RC 模型弱点。
相比之下,我们研究了一个场景,其中注释器在其原始任务设置中与模型交互——因此,注释器必须探索一系列自然对抗性攻击,而不是在注释过程中过滤掉“简单”的样本。
3. Annotation Methodology
3.1 注释原则
数据标注协议基于SQuAD1.1,循环中有一个模型,额外说明一下问题应该在文章中只有一个答案,这直接反映了这些模型的训练环境。
形式上,提供段落 p,人类注释者生成问题 q 并突出显示由段落中的相应跨度得到的(人类)答案ah。 然后将输入 (p,q) 提供给模型,该模型返回预测的(模型)答案 am。 为了比较两者,计算 ah 和 am之间的词重叠指数 F1; F1高于阈值为40%的被认为是模型的“胜利”(阈值的设置基于预实验)。重复此过程,直到人类“获胜”; 图 2 给出了该过程的示意图。 然后保留所有人类成功的 (p,q,ah) 三元组,即模型无法正确回答的三元组,以供进一步验证。
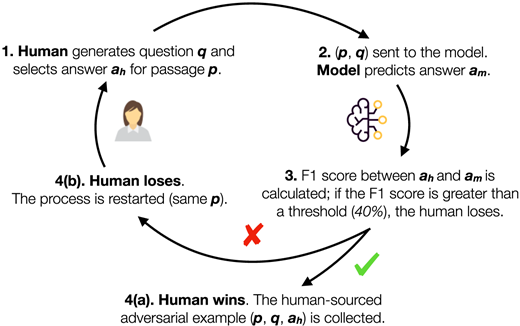
图2:使用model-in-the-loop收集人类写的对抗性书面问题的注释过程概述。
3.2 注释细节
循环过程中的模型
我们首先训练三个不同的模型,它们在数据注释期间用作对抗模型。作为用于训练模型的种子数据集,我们选择了广泛使用的 SQuAD1.1数据集,这是一个大规模资源,各种成熟且性能良好的模型随时可用。此外,与基于完形填空的数据集不同,SQuAD 对仅通过/问题的对抗性攻击具有鲁棒性。我们将数据集注释与一系列三个逐渐增强的模型作为循环中的对抗模型进行比较,三个模型即 BiDAF、BERTLARGE 和 RoBERTaLARGE。这些中的每一个都将在单独的注释实验中充当对抗模型,并产生三个不同的数据集;我们将它们分别称为 DBiDAF、DBERT 和 DRoBERTa。每个验证集的示例如表 1 所示。我们依赖于 AllenNLP和 Transformers模型实现,我们的BiDAF、BERT 和 RoBERTa 在 SQuAD1.1 验证集上分别为65.5%/77.5%、82.7%/90.3% 和 86.9%/93.6%,与其他工作报告的结果一致。
(表格1见原文第5页)
我们对模型的选择既反映了从基于 LSTM 的模型过渡到基于预训练Transformer 的模型,也反映了后者的提升; 我们的研究注释循环中使用这些不同模型收集的数据集也反映这一点。 对于每个模型,我们收集 10,000 个训练数据、1,000 个验证数据和 1,000 个测试示例。 数据集的大小受到基于 Transformer 的预训练模型的数据效率的推动,这提高了用于调查和分析目的的小规模数据收集工作的可行性。
为了记录held-out测试集的所有结果来确保实验完整性,我们将现有的 SQuAD1.1 验证集(因为官方测试集不公开)分成两半(按文档标题分层)。 我们在所有数据集的训练、验证和测试集之间保持段落一致性,以实现同类比较。 最后,我们使用多数投票的答案作为 数据集的ground truth,以确保我们的所有数据集每个问题都有一个有效答案,使我们能够公平地进行直接比较。 为清楚起见,我们在下文中将 SQuAD1.1 的这个修改版本称为 DSQuAD。
Crowdsourcing众筹
我们使用通过 Amazon Mechanical Turk (AMT) 提供的定制设计的Human Intelligence Tasks (HIT) 进行所有注释工作。 员工必须在加拿大、英国或美国工作,HIT 批准率大于 98%,并且之前已成功完成至少 1,000 个 HIT。 我们在有和没有 AMT Master要求的情况下进行了实验,发现质量没有显著差异,但观察到吞吐量降低了近 90%。 我们为每个问题生成 HIT 支付 2.00 美元,在此期间,工作人员需要编写最多五个问题来“击败”循环中的模型(参见图 3)。 BiDAF、BERT 和 RoBERTa 的平均 HIT 完成时间为 551.8s、722.4s 和 686.4s。 此外,我们发现人类工作者能够生成问题,在 BiDAF 的 59.4% 的时间内成功“击败”循环中的模型,BERT 为 47.1%,RoBERTa 为 44.0%。 这些指标广泛地反映了模型的相对能力。
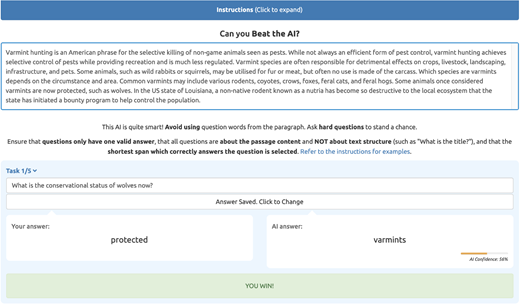
图3:“Beat the AI”问题生成界面。人类标注者的任务是根据提供的文段提出使模型无法正确回答的问题。
3.3 Quality Control
Training and Qualification
我们提供了一个由两部分组成的工作人员培训界面,以便 i) 让工作人员熟悉流程,以及 ii) 根据工作人员的产出进行第一次筛选。 该界面使工作人员熟悉构造问题,并通过篇章抽取来回答这些问题。 工作人员被要求为两个给定的答案生成问题,突出显示两个给定问题的答案,生成一个完整的问答对,最后以 BiDAF 作为循环中的模型完成一个问题生成 HIT的过程。 然后(由作者)手动审查每个工作人员的输出; 通过筛选的人将被添加到合格的注释者池中。
Manual Worker Validation
在第二个注释阶段,合格的工作人员为“Beat the AI”问题生成任务生成数据。 每个工作人员生成的 HIT 样本需要根据他们完成的任务总数 n 手动审查的,由 ⌊5⋅log10(n)+1⌋ 确定,该函数是为了方便而选择。 这是在每个annotation batch之后完成的; 如果工作人员在任何时候低于 80% 的成功阈值,他们的资格将被撤销,他们的工作将被完全丢弃。
Question Answerability
随着注释任务中使用的模型变得更强大,由此产生的问题往往变得更加复杂。然而,这也意味着将数据集质量的度量与原有的问题难度分开变得更具挑战性。因此,我们对带注释的问答对加入人类可回答性的考量,如下所示:如果三个另外的非专家人类验证者中的至少一个可以提供与原始答案匹配的答案,则它是可回答的。我们对验证集和测试集进行了可回答性检查,DBiDAF、DBERT 和 DRoBERTa 的可回答性得分分别为 87.95%、85.41% 和 82.63%。我们从验证和测试集中丢弃所有被认为无法回答的问题,并进一步丢弃来自任何被认为可以回答的问题少于一半的工人的所有数据。应该强调的是,这个过程的主要目的是为不同对抗模型构建的数据集之间的比较创造一个公平的竞争环境,并且不可避免地导致有效问题被丢弃。工作人员的培训和资格认证、数据集构建和验证的总成本约为 27,000 美元。
Human Performance
我们随机选择一个验证者对每个问题的回答来计算与原始的精确匹配 (EM) 和单词重叠 F1 指数,以计算非专家人类的表现; 结果如表2所示。 我们观察到一个明显的趋势:用于构建数据集的model-in-the-loop中的模型越强,由此产生的问题对人类来说就越难。
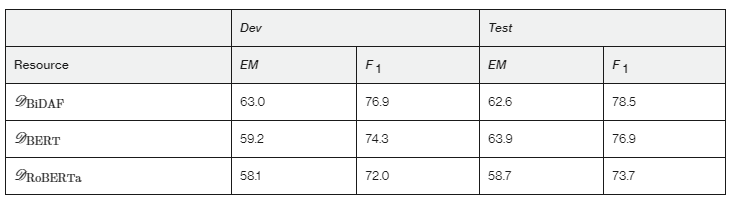
表2:随机选择的非专家人类在数据集上的表现。
3.4 Data Statistics
表 3 提供了不同数据集拆分中使用的段落和问答对数量的一般详细信息。 问题和答案中的平均单词数,以及段落和问题之间平均最长的 n-gram 重叠如表 4 所示。
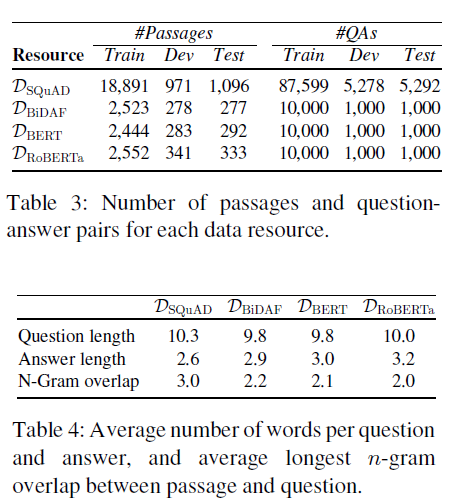
我们可以再次观察到两个明显的趋势:注释循环中使用的模型从弱到强,答案的平均长度增加,最大的 n-gram 重叠从 3 个标记下降到 2 个标记。 也就是说,平均而言,DSQuAD 的段落和问题之间有一个三元组重叠,但 DRoBERTa 只有一个二元组重叠(图 4)。 这与先前发现的可以作为 SQuAD 中的预测线索的对词汇重叠的观察一致; 对于三个模型中的任何一个,重叠较少的问题都更难回答。
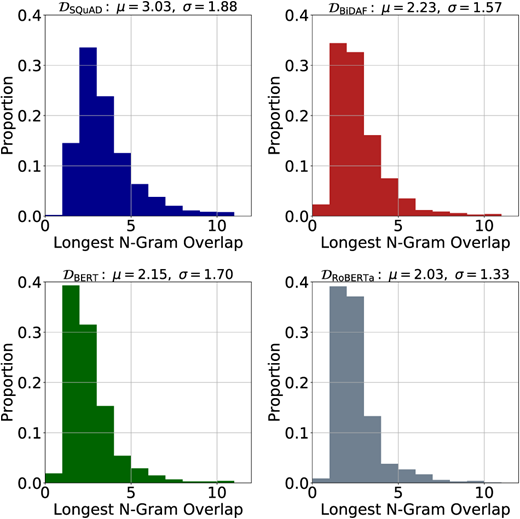
图4:不同数据集段落和问题之间最长的n-gram重叠分布。μ表示均值,σ表示标准差。
我们进一步根据以wh-word开头的问题分析问题类型。 我们发现——与 DSQuAD 相比——在注释循环中使用模型收集的数据集中when、how和in问题较少,而更多的是which、where和why问题,以及other类别中的问题,这表明问题的多样性增加。 在答案类型方面,我们观察到比 DSQuAD 中更常见的名词和动词短语从句,以及更少的日期、名字和数字答案。 这反映了当代 RC 模型强大的答案类型匹配能力。 此分析中使用的训练和验证集(DBiDAF、DBERT 和 DRoBERTa)将公开发布。
4. Experiments
4.1 Consistency of the Model in the Loop
我们从一个关于注释循环中模型对抗性的稳定一致性的实验开始。 我们的注释管道旨在拒绝模型正确预测答案的所有样本。 使用相同的训练数据重新训练模型时,这种重现性如何? 为了衡量这一点,我们评估了 BiDAF、BERT 和 RoBERTa 的性能,它们与注释期间使用的模型仅在训练期间的随机初始化和小批量样本的顺序(order of mini-batch samples)上有所不同。 这些结果如表 5 所示。

表5:当用相同的数据和不同的随机数种子再次训练模型时对抗效果的稳定一致性,我们记录了10次不同初始化运行的平均值和标准差(在下标)。
首先,我们观察到:正如我们的注释约束所预期的那样,在注释循环中使用相同的相应模型创建的数据集上的模型性能为 0.0EM。 然而,我们观察到,重新训练的模型在这些样本上的表现并不可靠。 例如,BERT 达到了 19.7EM,而注释期间使用的原始模型没有提供正确答案是0.0EM。 这表明随机模型组件可以显著影响对抗性注释过程。 这个结果还可以作为后续模型评估的基线:仅通过重新训练相同的模型就可以学习到大部分性能范围。 正如 Grefenstette 等人所调查的那样,未来使用model-in-the-loop注释策略的一个可能的收获是依赖于对抗模型的ensemble并减少对一个特定模型实例的依赖。
4.2 Adversarial Generalization
关注具有挑战性的问题的一个潜在问题是它们可能彼此非常不同,导致难以learning to generalize to and from them。 我们进行了一系列实验,在这些实验中我们在 DBiDAF、DBERT 和 DRoBERTa 进行了训练,并观察模型如何能够很好地学习泛化到这些数据集的各个测试部分。 表6显示了结果,并且有大量的观察结果。
(表6见原文第8页)
首先,我们在所有训练数据设置中观察到的一个明显趋势是,当针对循环中使用更强模型构建的数据集进行评估时,性能会出现负增长。 除了 BiDAF 模型之外,这种趋势适用于每个训练配置和每个评估数据集。 例如,在 DRoBERTa 上训练的 RoBERTa 分别在 DSQuAD、DBiDAF、DBERT 和 DRoBERTa 上进行评估时达到 72.1、57.1、49.5 和 41.0F1。
其次,我们观察到 BiDAF 模型不能很好地泛化到由循环中的模型构建的数据集,这与其训练设置无关。 特别是,它无法从DBiDAF中学习,因此无法通过对抗性训练克服自己的一些盲点。 无论训练数据集如何,BiDAF 在对抗性收集的评估数据集上始终表现不佳,我们还注意到在 DBiDAF、DBERT 或 DRoBERTa 上训练并在 DSQuAD 上评估时性能大幅下降(根据上下文,应该只是BiDAF数据集)。
相比之下,BERT 和 RoBERTa 能够通过对循环中模型收集的数据进行训练来部分克服它们的盲点,其程度远远超过随机再训练的预期(参见表 5)。 例如,在 DBERT 上训练和评估时,BERT 达到 47.9F1,而在 DRoBERTa 上训练的 RoBERTa 在 DRoBERTa 上达到 41.0F1,都比随机再训练或在非对抗性收集的 DSQuAD(10K) 上训练好得多,涨幅显示BERT为 20.6F1,RoBERTa 为 18.9F1。 这些观察结果表明,在一些更难的问题中存在可学习的结构,某些模型可以选择出这些问题,但并非全部都这样,因为 BiDAF 无法实现这一点。 与 BERT 和 RoBERTa 相比,即使是 BERT 也可以泛化推广到 DRoBERTa,但 BiDAF 不能泛化推广到 DBERT,这表明 BiDAF 可以从这些新样本中学到的东西存在固有的局限性。
更一般地说,我们观察到在 DS 上的训练,其中 S 是一个更强的 RC 模型,有助于泛化推广到 DW,其中 W 是一个较弱的模型——例如,在 DRoBERTa 上训练和在 DBERT 上测试。 另一方面,在DW上训练会导致对 DS 的泛化。 例如,在 10,000 个 SQuAD 样本上训练的 RoBERTa 在 DRoBERTa (DS) 上达到 22.1F1,而在 DBiDAF 和 DBERT (DW) 上训练的 RoBERTa 将这个数字分别提高到 39.9F1 和 38.8F1。
第三,当使用循环中越来越强大的模型收集的数据进行训练时,我们在 DSQuAD 上观察到 BERT 和 RoBERTa 相似的性能下降模式。 例如,在 DSQuAD 上评估的 RoBERTa 分别在 DSQuAD(10K)、DBiDAF、DBERT 和 DRoBERTa 上训练时达到 82.8、80.0、75.1 和 72.1的F1。 这可能表明随着循环中的模型变得更强大,组合问题的分布逐渐发生变化。
这些观察结果表明model-in-the-loop注释范式的一个令人鼓舞的结论:即使可能会选择在某些时候落后于最新的最先进模型的特定模型作为注释循环中的对抗模型 ,这些未来的模型仍然可以从使用较弱模型收集的数据中受益,并且还可以在循环中由较强模型组成的样本上更好地泛化。
我们进一步展示了相同模型和训练数据集上的实验结果,但现在将 SQuAD 作为额外的训练数据包含在表 7 中。在此训练设置中,我们通常看到越来越强的在 DBiDAF、DBERT 和 DRoBERTa 上的泛化。 有趣的是,当与 SQuAD 结合使用时训练集 DBiDAF、DBERT 和 DRoBERTa 之间的相对差异大大减少,尤其是在作为(部分)训练集的 DRoBERTa 上训练的现在泛化得更好。 我们看到 BERT 和 RoBERTa 在添加原始 SQuAD1.1 训练数据后都表现出一致的性能提升,但与表 6 不同的是,这在 DSQuAD 上没有任何明显的性能下降,表明对抗性构建的数据集暴露了原有模型的弱点。
(表7见原文第9页)
此外,RoBERTa 在对抗性收集的评估集上取得了最强的结果,尤其是在 DSQuAD+DRoBERTa 上训练时。 这与表 6 中的结果形成对比,表 6 中的 DBiDAF 训练在几种情况下比 DRoBERTa 训练产生更好的泛化效果。 一种可能的解释是,在 DRoBERTa 上的训练比在 DBiDAF 上的训练使得对 DRoBERTa 中特定对抗性示例的过拟合程度更大,并且包含大量标准 SQuAD 训练样本可以减轻这种影响。
表8显示了在所有数据集上训练的结果(DSQuAD、DBiDAF、DBERT 和 DRoBERTa )。这些结果不仅与之前的观察相符,而且提供了额外的性能提升。例如,RoBERTa在DSQuAD得分为 86.9,DBiDAF 得分为 74.1,DBERT 得分为 65.1,DRoBERTa 得分为 52.7,超过了之前在所有对抗性数据集上的最佳表现。
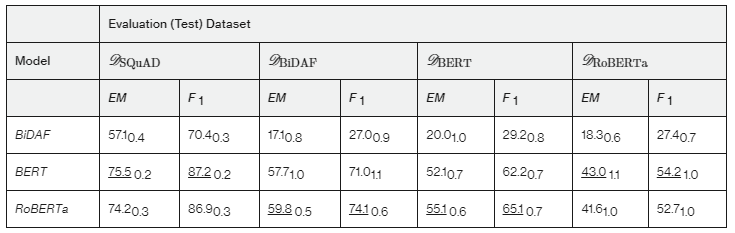
表8:在SQuAD 与所有对抗性创建的数据集 DBiDAF、DBERT 和 DRoBERTa 相结合的数据集上训练模型。 下划线的结果表示每个模型的最佳结果。 我们报告了使用不同随机种子运行 10 次的平均值和标准差(下标)。
最后,我们确定了循环中使用较弱模型构建的数据集过时的风险。 例如,RoBERTa 在 DBiDAF 上达到 58.2EM/73.2F1,而 BiDAF 为 0.0EM/5.5F1——这与 62.6EM/78.5F1 的非专家人类表现相去不远(参见表 2)。
值得注意的是,即使在对所有组合数据进行训练时(参见表 8),BERT 在 DRoBERTa 上的表现也优于 RoBERTa,反之亦然,这表明每个模型类可能存在固有的弱点。
4.3 Generalization to Non-Adversarial Data
与标准注释相比,model-in-the-loop方法通常会产生新的问题分布。 因此,在对抗性问题上训练的模型可能无法推广到标准(“easy”)问题,从而限制了结果数据的实际用途。 与在标准(“easy”)问题上训练的模型相比,在model-in-the-loop问题上训练的模型在多大程度上不同于标准(“easy”)问题?
为了衡量这一点,我们进一步在 DBiDAF、DBERT 或 DRoBERTa 上训练我们的三个模型中的每一个,并在 DSQuAD 上进行测试,结果在表 6 的 DSQuAD 列中。为了进行比较,这些模型也在SQuAD1.1数据集中10,000从与对抗性数据集相同的段落中选择的样本(称为 DSQuAD(10K))上进行了训练,从而消除了作为潜在混淆因素的数据集规模大小和段落选择。 这些模型在held-out的 DSQuAD 验证集上针对 EM 进行了微调。 请注意,尽管多数投票 DSQuAD 数据集的性能值低于原始数据,但由于前面描述的原因,这可以在所有数据集上直接比较。
值得注意的是,与在 SQuAD 数据上训练相比,在 DBiDAF 上训练时 BERT 和 RoBERTa 都没有显着下降(-2.1F1 和 -2.8F1):在循环中使用较弱模型的数据集训练这些模型仍然导致强泛化,即使是与来自原始 SQuAD 分布的循环中的所有模型都对其进行训练的数据相比。 另一方面,BiDAF 无法从对抗性收集的数据中学习到此类信息,与 SQuAD 上的训练相比,每个新训练集都下降了大于30F1。
我们还观察到,在 DBiDAF 上训练到 DRoBERTa 上训练时,对 SQuAD 的泛化逐渐降低。 这表明模型越强,产生结果数据分布与原始 SQuAD 分布的差异越大。 我们后来在定性分析中找到了对这种解释的进一步支持(第 5 节)。 然而,这也可能是由于 BERT 和 RoBERTa(类似于 BiDAF)在从旨在击败这些模型的数据分布中学习时存在局限性; 更强大的模型可能会从例如 DRoBERTa 中学到更多。
4.4 Generalization to DROP and NaturalQuestions
最后,我们调查模型可以在多大程度上将使用model-in-the-loop创建的数据集上学到的技能转移到两个最近引入的数据集:DROP和 NaturalQuestions。在本实验中,我们选择与 SQuAD 的结构约束一致的 DROP 和 NaturalQuestions 子集,以确保进行同类分析。具体来说,我们只在 DROP 中考虑答案是段落中的一个跨度并且只有一个候选答案的问题。对于 NaturalQuestions,我们将所有非表格长答案视为段落,删除 HTML 标签并使用简短答案作为提取的跨度。我们对两个数据集的验证集应用此过滤措施。接下来,我们将它们分开,按文档分层(就像我们对 DSQuAD 所做的那样),这导致 DROP 的验证和测试集示例分别为 1409/1418 ,NaturalQuestions 的验证和测试集示例分别为964/982。我们将这些数据集表示为 DDROP 和 DNQ,以便与未过滤版本的区别。我们考虑与以前相同的模型和训练数据集,但会在 DDROP 和 DNQ 的验证集上进行微调。表 6 显示了这些实验在 DDROP 和 DNQ 数据集中的结果。
首先,在 DBiDAF、DBERT 或 DRoBERTa 中的任何一个上进行训练时,与 DSQuAD(10K) 上的训练相比,我们观察到所有模型对 DDROP 有明显泛化性能提升。 也就是说,在训练数据集的循环中包含一个模型可以改善向 DDROP 的知识转移。 请注意,DROP 在注释期间也在循环中使用了 BiDAF 模型; 这些结果与我们之前在 DSQuAD(10K)上训练在 DBiDAF、DBERT 和 DRoBERTa 上相同设置测试时的观察结果一致。
其次,我们观察到对 DNQ 整体强大的转移效果,在 DBiDAF 上训练的 BERT 模型高达 69.8的F1。 请注意,此结果类似于使用相同大小的 SQuAD 数据进行模型训练,甚至略有改进。 也就是说,相对于对 SQuAD 数据的训练,对对抗收集的数据 DBiDAF 的训练不会妨碍对 DNQ 数据集的泛化,DNQ是在注释循环中没有模型的情况下创建的。 然而,我们随后在 DSQuAD 上测试时看到了与之前观察到的类似的负面性能进展:构造训练数据集时注释循环中的模型越强,来自没有model-in-the-loop的数据分布组成的测试数据的测试准确度就越低。
5. Qualitative Analysis
在将通用model-in-the-loop方法应用于不同能力的模型后,我们接下来对产生问题的性质进行定性比较。 作为参考点,我们还包括原始 SQuAD 问题,以及 DROP 和 NaturalQuestions问题,在此比较中:这些数据集的构建都是为了克服 SQuAD 中的限制,并且具有与 SQuAD 结构相似的子集,使分析成为可能。 具体来说,我们试图了解每个数据集中的问题在阅读理解挑战方面的本质差异。
5.1 Comprehension Requirements
有多种先前的工作试图了解基于文本回答问题所需的知识类型、理解能力或推理类型; 然而,我们不知道有任何普遍接受的形式主义。 我们从这些中汲取灵感,但开发了我们自己的适合分析数据集的理解要求分类法。 我们的分类法包含 13 个标签,其中大部分在其他工作中常用。 然而,以下三点值得进一步澄清:i)明确的——答案在文章中几乎是逐字逐句地陈述的,就像在问题中一样,ii)过滤——一组答案以某些特定的显著特征被缩小以选择一个答案,iii) 隐含的——答案建立在文章所暗示的信息之上,并且不需要任何其他类型的推理。
我们用这个目录中的标签以一种既不相互排斥也不完全全面的方式对问题进行注释; 开发这样一个目录本身就非常具有挑战性。 相反,我们专注于捕捉每个给定问题的最显著特征,并将其分配给我们目录中的三个标签。 我们总共分析了每个数据集验证集中的 100 个样本; 图 5 显示了结果。
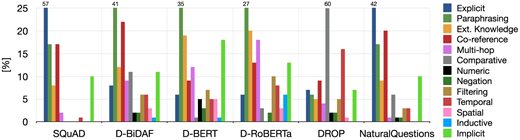
图5:不同数据集中问题的理解类型比较。 标签类型既不相互排斥也不全面。 列上方的值表示超出轴范围。
5.2 Observations
初步观察结果是,SQuAD 问题的大多数 (57%) 答案都是明确陈述的,没有超出字面水平的理解要求。对于从 SQuAD 派生的任何model-in-the-loop数据集这个数字都显著下降(例如,DBiDAF 的 8%和),DDROP 的任何model-in-the-loop数据集也下降,但 DNQ 中 42% 的问题共享此属性)。与 SQuAD 相比,model-in-the-loop问题通常会涉及更多的释义。它们还需要更多的外部知识和多跳推理(超出co-reference resolution),并且越来越倾向于在注释循环中使用更强大的模型。Model-in-the-loop问题进一步扩展为理解所需的更具体类型推理的各种小但不可忽略的比例,例如,空间或时间推理(均超出明确说明的空间或时间信息) ——SQuAD 问题很少需要这些。这些更特殊的推理类型中的一些是其他两个数据集的共同特征,特别是 DROP (60%) 的比较问题,NaturalQuestions在小范围内也是 。有趣的是,DBiDAF 在我们的model-in*the-loop数据集中拥有最多的比较问题 (11%),而 DBERT 和 DRoBERTa 分别只有 1% 和 3%。这为我们之前在表 6 中的观察提供了解释,其中 BERT 和 RoBERTa 在 DBiDAF 上训练时在 DDROP 上的表现比在 DBERT 或 DRoBERTa 上训练时表现更好。 BiDAF 作为循环中的模型很可能在比较问题上比 BERT 和 RoBERTa 差,如表 6 中的结果所示,在 DSQuAD(10K) 上训练时,BiDAF 达到 8.6F1,BERT 达到 28.9F1,RoBERTa 在 DDROP 上达到 39.4F1。
NaturalQuestions 的分布包含 SQuAD 和 DBiDAF 中分布的元素,这为在 DSQuAD(10K) 和 DBiDAF 上训练的模型在 DNQ 上的强大性能提供了一个潜在的解释。 最后,随着model-in-the-loop中模型强度的增加,分布逐渐远离 SQuAD 和 NaturalQuestions 反映了我们之前对在循环中模型逐渐增强的数据集上训练的模型在 SQuAD 和 NaturalQuestions 上的性能下降的观察。
6. Discussion and Conclusions
我们研究了一个 RC 注释范式,它要求循环中的模型被注释器“击败”。 将此方法与循环中逐渐增强的模型(BiDAF、BERT 和 RoBERTa)一起应用,我们生成了三个独立的数据集。 使用这些数据集,我们研究了关于注释范式的几个问题,特别是这些数据集是否随着更强模型的出现而变得过时,以及它们对标准(非对抗性收集)问题的泛化。 我们发现,更强的模型仍然可以从循环中弱对抗模型收集的数据中学习,即使在由更强对抗模型收集的数据集上,它们的泛化能力也有所提高。 使用循环中的模型收集的数据训练的模型进一步泛化到非对抗性收集的数据,无论是在 SQuAD 上还是在 NaturalQuestions 上,但我们观察到随着对抗模型逐渐强大,性能逐渐下降。
我们将我们的工作视为对model-in-the-loop注释的新兴范式的贡献。尽管本文关注的是 RC,使用 SQuAD 作为用于训练对抗模型的原始数据集,我们从原则上看不出为什么使用相同注释范式的其他任务的结果不相似,当使用模型中的模型众包具有挑战性的样本时环形。我们希望传达model-in*the-loop注释的见解和好处在模型超过人类性能的成熟数据集上是最大的:这里的结果数据提供了模型性能的放大镜,尤其是使模型错误的样本在。另一方面,将该方法应用于性能尚未稳定的数据集可能会导致与原始数据更相似的分布,这对先验建模具有挑战性。我们希望关于可复制性的一系列实验、对使用不同强度模型收集的数据集之间转移的观察,以及我们对非对抗性收集的数据的泛化的发现,可以支持并为使用这种范式的未来研究和注释工作提供信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号