

Sentence-selector:Efficient and Robust Question Answering from Minimal Context over Documents论文阅读笔记
论文原文链接:[1805.08092] Efficient and Robust Question Answering from Minimal Context over Documents (arxiv.org)
来源:ACL2018
动机
以前的阅读理解模型在文档长度比较长的时候运算复杂度高,而且对于对抗性的输入敏感,鲁棒性差,所以作者提出了一个最小上下文的概念,是用sentence-selector只将回答问题所需的最少的句子输入到阅读理解模型中,一方面提高速度,一方面提高模型鲁棒性。
数据分析
数据集自身
分析主要用了两个数据集,SQuAD数据集和TriviaQA数据集。
从SQuAD验证集中随机选取了50个样本数据,分析回答问题所需要的最少句子的数目。其中98%的数据可以基于文本进行回答,2%的无法进行回答。在可以回答的数据中,92%的只用一个句子就可以回答,6%的需要两个句子,2%的需要三个及以上的句子来回答。
从TriviaQA数据集中也是进行同样的处理,TriviaQA数据集的文本长度要显著长于SQuAD数据集(平均每篇文章有488个句子,SQuAD平均每篇文章5个句子)。TriviaQA数据集中88%的数据是可以基于文本回答的,这其中95%的数据只用一两个句子就可回答。
具体表格和例子如下:

之前模型的bad case分析
使用的数据集变成了SQuAD和NewsQA。
模型使用的是DCN+,当时的SOTA模型。对比在整个文档上训练和评测的模型和在oracle sentence上训练量和评测的模型,前者的F1值为83.1,后者的F1值为85.1。从第一个模型表现不如第二个模型的数据中随机选取了50个数据进行分析,发现错误分为4种类型,表格和例子如下图:

同时对比了用整篇文档训练和用oracle sentence训练的预测准确性情况。ORACLE is able to answer 93% and 86% of the questions correctly answered by FULL on SQuAD and NewsQA, respectively.(这句话英文比中文翻译简洁好理解)。图表如下:

模型方法
阅读理解模型使用的是DCN+,不是本文的重点。主要说明Sentence Selector的结构。
Sentence Selector的核心:根据问题并行的给文档中每个句子打分,分数表明问题是否能用这个句子回答。
模型的组成:encoder+decoder,encoder部分用于将问题和文档编码,与阅读理解模型共享。
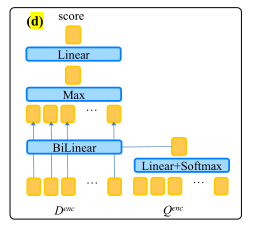
第一步:
embedding部分需要计算的三个量如下:
(i)sentence embedding,用二维矩阵D表示(维度是词向量维度h×文档长度)。
(ii)question embedding,用二维矩阵Q表示(维度是词向量维度h×问题长度)。
(iii)question-aware-sentence-embeddings,用二维矩阵Dq表示(维度是词向量维度h×文档长度),目的主要是把问题的信息加入到文档的表示中。计算方法如下:
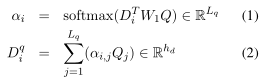
公式(1)中,Di是sentence embedding中第i个词的hidden state,是一个一维向量,维度是词向量的维度h(也就是h×1)。W1是要训练的二维权重矩阵之一,维度是词向量的维度h×h,Q是(ii)中的question embedding。计算结果αi是一维向量,维度是问题长度(也就是1×问题长度),作为一个权重。
公式(2)中使用公式(1)的结果,遍历问题的长度求和计算第i个词的影响程度,得到的向量是1×词向量维度h。
第二步:
encoder部分要得到sentence encodings和question encodings,通过双向LSTM来获得。
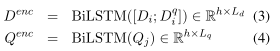
公式(3)中的‘;’表示两个向量的拼接,公式此时的h与词向量维度不一样,是另一个可以设置的超参数。
第三步:
decoder部分,核心部分,通过计算sentence encodings和question encodings之间的bilinear similarities来得到分数。
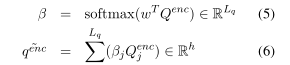
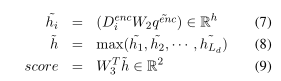
公式中的w和W都是可训练的权重矩阵。
公式(5)中w的维度是h×1,Qenc是h×问题长度。β是一个权重,一维向量,维度是1×问题长度。
公式(6)中,求和得到的矩阵是h×1。
公式(7)中,第一个矩阵是1×h,W2是h×h×h,用到了(6)的结果,最后得到1×h×1,相当于一维矩阵,维度为h。
公式(8)中,从句子的每个词中选一个值最高的。
公式(9)中,得到最后的分数。
阈值决定分数的取舍,不同的问题会选出不同长度的句子。然后送入阅读理解模型。
训练模型时使用的技巧:
1. encoder权重共享,使用了在oracle sentence上训练得到的权重。
2. modify the training data by treating a sentence as a wrong sentence if the QA model gets 0 F1, even if the sentence is the oracle sentence.(不太好翻译,就是数据的处理方面)
3. 获得每个句子的分数后,归一化处理。we normalize scores across sentences from the same paragraph
实验
sentence selector实验了两种版本,由阈值控制选择句子数量的动态版本Dyn,固定句子数量选择分数高的版本top-k。
实验中使用了五个数据集SQuAD、NewsQA、TriviaQA、SQuAD-Open、SQuAD-Adversarial,实验具有两个任务,sentence selection的评价指标是accuracy(Acc)和mean average precision(MAP),阅读理解的评价指标是EM和F1,同时测量了训练速度和inference speed(应该是预测的速度)
阅读理解任务:对于每个QA模型,三种输入,整个文档,the oracle sentence containing the groundtruth answer span,以及用sentence selector选出的句子(两种版本Dyn和top-k都要进行实验)。
句子选择任务:文中提出的sentence selection的方法与TF-IDF方法对比。TF-IDF方法:用n-gram TF-IDF 距离衡量。
每个任务下还实验了三个技巧的作用。
实验的思路如上,具体实验的结果见原文第四部分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号