

Retrospective Reader论文及原理
论文:Retrospective Reader for Machine Reading Comprehension,是上海交大的一篇论文
阅读及复现这篇论文的契机是因为它是SQuAD2.0榜单前几名中唯一一个有论文的。
摘要
机器阅读理解(MRC)要求机器基于给定的文段提取出问题的答案,不仅需要找到正确的答案的位置还需要机智地判断出没有答案的情况。当MRC中包含了无法回答的问题时,除了基本的encoder-decoder结构还需要加上一个verification模块,一般都用一个强大的预训练模型作为encoder来完成阅读的任务。这篇论文为MRC中无法回答的问题设计了更好的verifier。论文的核心思想来源于人类解决阅读理解问题的逻辑,基于此提出了Retro-Reader的模型,这个模型包含两阶段的阅读和verification策略:(1)粗读阶段,先整体阅读文段和问题,得到一个基本的判断。(2)细读阶段再次验证答案并给出最终的预测。这个模型在SQuAD2.0和NewsQA数据集上达到了新的SOTA。
核心思想
借鉴了人类阅读模式:先粗读一遍,做出初步判断,再细读寻找答案范围。
之前的工作
针对包含无法回答的问题的MRC,之前的模型有以下几种解决思路。
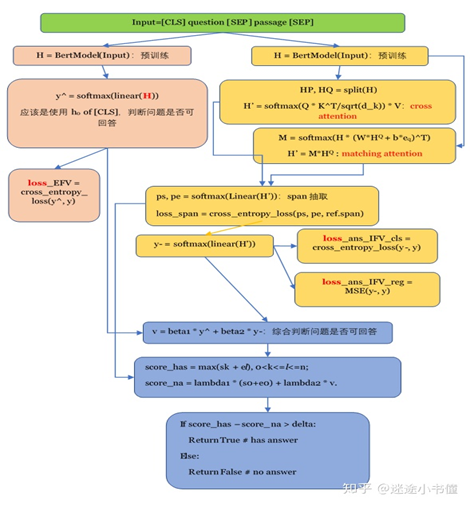
基本模型:Encoder+decoder,encoder是一个强大的预训练模型,decoder负责文章与问题的交换,生成span。
对于无答案,之前的解决思路:
- 将encoder和decoder直接相连,用CLS判断是否有答案,相当于二分类问题。最终的loss值是span的loss和二分类的loss相加。(对应下图中的a)
- 在encoder或decoder后面加上verifier层,一般也是全连接层,判断是否有答案。(对应下图中的b和c)
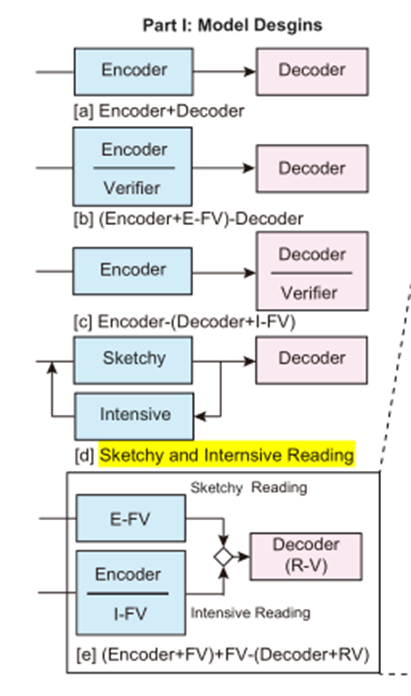
上图中的d是本文提出的模型,e是对d的细化。
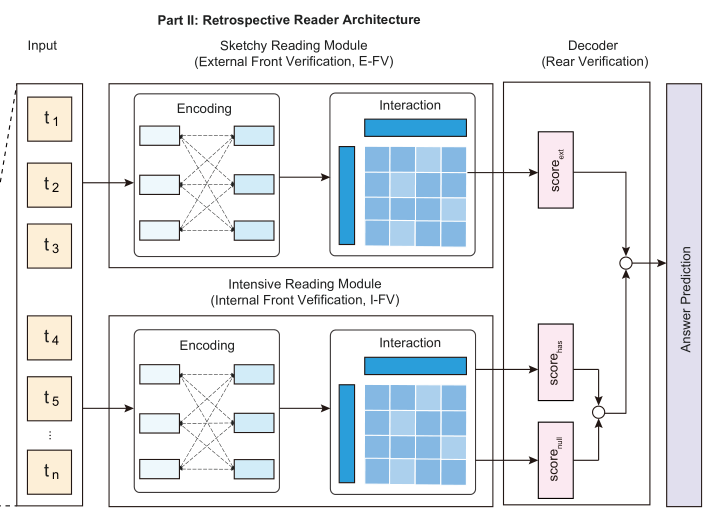
Retro-Reader由三个模块组成:粗读阶段、精读阶段和decoder
- 粗读阶段由一个External front verification,简称E-FV组成
- 精读阶段由一个encoder和一个Internal front verification(简称I-FV)组成,encoder还是一个强大的预训练模型
- decoder阶段除了原来的负责预测span的decoder外,还加上了一个Rear verification(简称R-V)模块。
Sketchy Reading Module(粗读模块)
粗读模块相当于用一个多层Transformer做分类,由以下三个部分组成:
- Embedding,把问题和文段拼接在一起作为输入,类似BERT的处理,要加上position embedding、token-type embedding
- Interaction,类似BERT的处理,只取最后一层的hidden state做最后的处理。
- E-FV:用CLS过一个全连接层做二分类,损失函数如下:
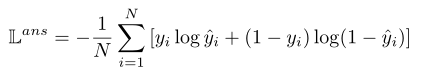
同时计算一个score值,表示答案是否存在的分值。
Intensive Reading Module
精读模块相当于用一个encoder进行阅读理解任务,生成span,同时多任务训练(multi-tast),同时计算一个问题的可回答性。
Question-aware Matching
论文中提到了Question-aware Matching的概念,增强问题和文段的匹配。这是加在encoder后面的。
首先把最后一层的hidden state H按照问题和文本分开,HQ对应着问题的表示,HP对应着文本的表示。将这两个序列都填充到minibatch的最大长度。
有两种question-aware的matching策略:(1)Transformer式的多头cross attention机制,简称CA(2)传统的matching attention,简称MA
- Transformer式的CA,多头的self-attention中Q=K=V,把H作为Q的输入,HQ作为K、V的输入,由此获得了question-aware的上下文表示H’。相当于在encoder的输出后面加一个self-attention。
- 传统的MA,把H和HQ作为输入喂给一个传统的matching attention layer,把HQ作为H的attention,计算公式如下:
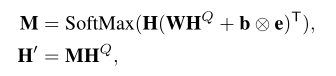
W和b是matching attention layer的参数,e是全1的向量,用于广播。M是两个相关序列不同的hidden state的权重(就是attention),得到的结果H'是所有hidden state的加权和,它表示了H的向量是怎样分配给HQ的每个hidden state的。用H‘用于接下来的预测。
span prediction
在最后加一个线性层,用softmax获取概率。计算交叉熵损失函数。
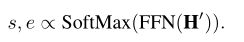
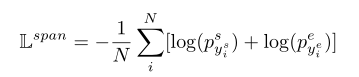
Internal Front Verification(I-FV)
同样用encoder的CLS过一个全连接层进行二分类。可以用交叉熵作为损失函数,也可以用均方误差作为损失函数。
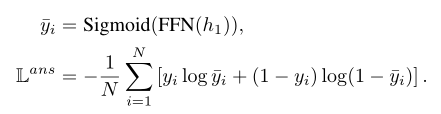
精读模块encoder的损失函数是把span loss和cls loss带权加起来,
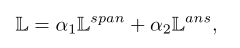
Threshold-based Answerable Verification(TAV)
这是一个启发性规则,根据最后得出的start和end来预测这个问题是否可以回答,由此判断模型的输出到底是答案的span还是null。
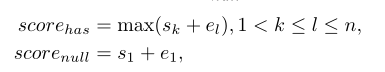
得出一个差异性的分值:

用这个差异性分值与阈值进行比较,大于阈值说明模型给出的是答案的span,否则是null。
decoder模块
这个模块只有一个RV需要说明。
Rear Verification
这个模块就是把粗读阶段的存在性分值和精度模块的差异性分值加权求和,作为最终的判断。如果结果大于阈值,就说明有答案,否则问题没有答案。
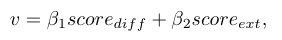
结构图
计算传播图如下:(从上到下的看)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号