
BERT相关变体原理理解
具体顺序不是按照模型出现的顺序,而是按照我在组会上讲的顺序。会在每个模型的一开头列出参考的博客以及论文。
主要写的是自己的理解,但是推荐一个有趣的博客:BERT and it's family
RNN结构,双向LSTM,Transformer, BERT对比分析
RoBERTa
论文:RoBERTa: A Robustly Optimized BERT Pretraining Approach
参考博客
https://wmathor.com/index.php/archives/1504/
概述
RoBERTa相较于BERT最大的三点改进:
- 动态Masking
- 取消NSP任务
- 扩大Batch size
Dynamic Masking
静态masking:在数据预处理期间 Mask 矩阵就已生成好,每个样本只会进行一次随机 Mask,每个 Epoch 都是相同的
修改版静态masking:在预处理的时候将数据拷贝 10 份,每一份拷贝都采用不同的 Mask,也就说,同样的一句话有 10 种不同的 mask 方式,然后每份数据都训练 N/10 个 Epoch。
动态masking:每次向模型输入一个序列时,都会生成一种新的 Maks 方式。即不在预处理的时候进行 Mask,而是在向模型提供输入时动态生成 Mask。
取消NSP任务
RoBERTa 实验了 4 种方法:
- SEGMENT-PAIR + NSP:输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个 segment 的 token 总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法
- SENTENCE-PAIR + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的 token 总数少于 512 。由于这些输入明显少于 512 个 tokens,因此增加 batch size 的大小,以使 tokens 总数保持与 SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务
- FULL-SENTENCES:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加标志文档边界的 token 。预训练不包含 NSP 任务
- DOC-SENTENCES:输入只有一部分(而不是两部分),输入的构造类似于 FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512 个 tokens, 因此在这些情况下动态增加 batch size 大小以达到与 FULL-SENTENCES 相同的 tokens 总数。预训练不包含 NSP 任务
扩大batch size
采用大的 Batch Size 有助于提高性能
ALBERT
论文:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations(ICLR,2020)
参考博客
https://wmathor.com/index.php/archives/1480/
概述
基于Bert做出的提高:
- 减少模型参数,加快训练速度
- 增加对语言连贯性的训练
主要的改进:
- Embedding层矩阵分解
- 跨层参数共享
- 将NSP任务换成了SOP(Sentence Order Prediction)任务
Embedding层矩阵分解
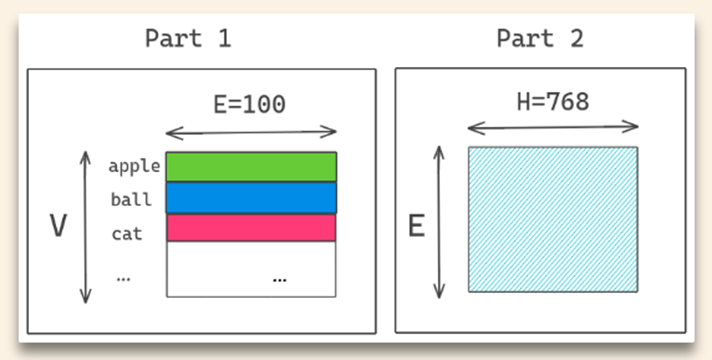
BERT:E=H,矩阵V*H(30000*768=23,000,000)
ALBERT:V*E+E*H(30000*256+256*768=7,800,000)
跨层参数共享
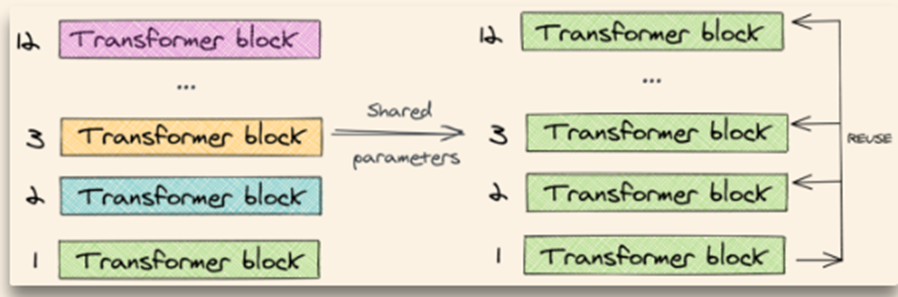
之前有工作试过单独将 self-attention 或者全连接层进行共享,都取得了一些效果。ALBERT 作者尝试将所有层的参数进行共享,相当于只学习第一层的参数,并在剩下的所有层中重用该层的参数,而不是每个层都学习不同的参数
效果:提升模型稳定性(模型稳定性是通过L2范数来衡量的,详见论文)
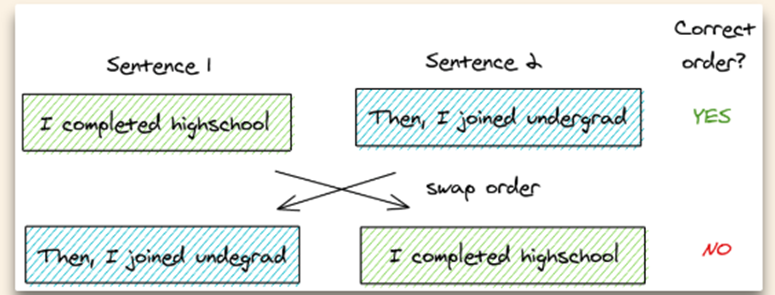
SOP任务
NSP:A与B是否是一个句子(主体预测+连贯性预测)
SOP:着力于连贯性预测
关键思想:
- 从同一个文档中取两个连续的句子作为一个正样本
- 交换这两个句子的顺序,并使用它作为一个负样本
其他措施:增加输入&去除dropout
以上 ALBERT 都是使用跟 BERT 相同的训练数据。但是增加训练数据或许可以提升模型的表现,于是 ALBERT 加上 STORIES Dataset 后总共训练了 157G 的数据。另外,训练到 1M 步的时候,模型还没有对训练集 Overfit,所以作者直接把 Dropout 移除,最终在 MLM 验证集上的效果得到了大幅提升
ELECTRA
论文:ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generator
ELECTRA的缩写来源:
ELECTRA:Efficiently Learning an Encoder that Classifies Token Replacements Accurately
与BERT相比所做的改变:
- 替换MLM为RSD任务
- 权重共享
- smaller Generator
ELECTRA的特点:小模型表现优良,节省计算量
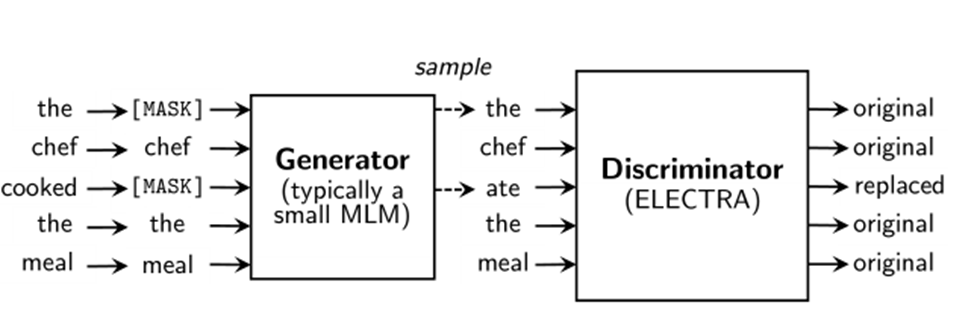
RSD(Replaced Token detection)
模型由两个部分组成,generator、discriminator。
generator负责随机MASK一部分输入,然后将输入中的MASK填上。
discriminator负责检测哪些是generator替换的,哪些是原本的。
动机:MLM只替换15%的token
类似于GAN的结构,但是不同。
- 如果generator产生的token和original token一样,discriminator认为这个token是real的
- generator按照最大似然训练,和discriminator没有交互,discriminator的梯度不会反向传播到generator
- generator的输入是真实文本,而不是随机噪声
- Fine-tune阶段只使用discriminator的部分
权重共享(weight sharing)
generator的embedding和discriminator共享
smaller generator
generator的size只是discriminator的1/4到1/2
如果 BERT 效果太好,直接就输出了和原来一摸一样的单词,这也不是我们期望的。
WWM(whole word masking)

随机地 mask 掉某个 token 效果是否真的好呢?对于中文来说,词是由多个字组成的,一个字就是一个 token。如果我们随机 mask 掉某个 token,模型可能不需要学到很多语义依赖,就可以很容易地通过前面的字或后面的字来预测这个 token。为此我们需要把难度提升一点,盖住的不是某个 token,而是某个词(span),模型需要学到更多语义去把遮住的 span 预测出来,这便是 BERT-wwm。同理,我们可以把词的 span 再延长一些,拓展成短语级别、实体级别(ERNIE)
MacBert
论文:Revisiting Pre-trained Models for Chinese Natural Language Processing
相较于BERT做出的改进:
- WWM & N-gram Masking,从单字符到4字符的掩蔽百分比为40%、30%、20%、10%
- 去除[MASK],采取同义词替换,使用Synonyms库,Masking的比例为15%,80%同义词替换,10%随机替换,10%保持
- SOP任务,同Albert一样。

SpanBERT
论文:SpanBERT:Improving Pre-training by Representing and Predicting Spans
与BERT相比做出的改进:
- MLM策略改变,span-level
- 提出了新的预训练任务SBO(Span Boundary Objective)
- 去除NSP任务,直接用连续一长句训练效果更好
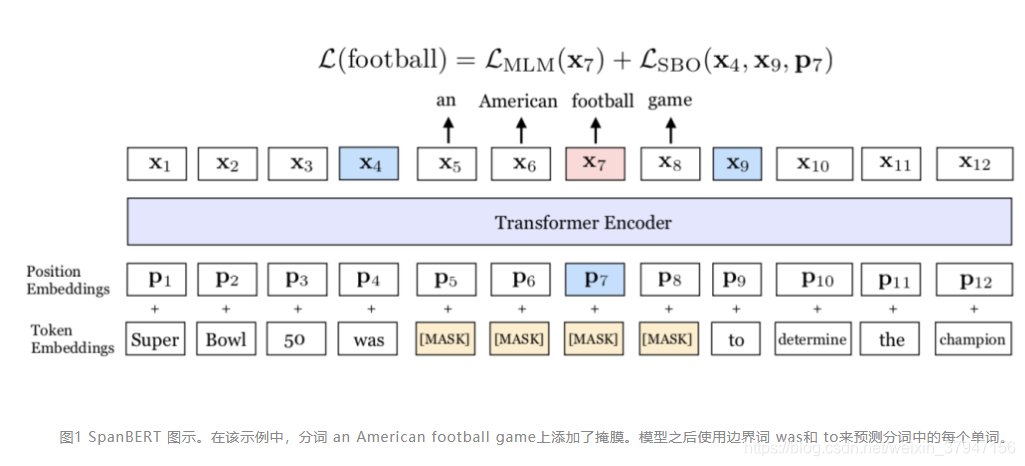
参考博客:https://blog.csdn.net/weixin_37947156/article/details/99210514
Span Masking
简单来说,就是每次mask的时候,先从几何分布 中采样出一个span长度,然后从均匀分布中采样span的起始位置。将整个span中的每一个token都换成[MASK]或是用随机单词替换,并不是将整个span替换为一个[MASK]。
具体来说,按照大佬的解释:
对于每一个单词序列 X = (x1, ..., xn),作者通过迭代地采样文本的分词选择单词,直到达到掩膜要求的大小(例如 X 的 15%),并形成 X 的子集 Y。在每次迭代中,作者首先从几何分布 l ~ Geo(p) 中采样得到分词的长度,该几何分布是偏态分布,偏向于较短的分词。之后,作者随机(均匀地)选择分词的起点。
根据几何分布,先随机选择一段(span)的长度,之后再根据均匀分布随机选择这一段的起始位置,最后按照长度遮盖。作者设定几何分布取 p=0.2,并裁剪最大长度只能是 10(不应当是长度 10 以上修剪,而应当为丢弃),利用此方案获得平均采样长度分布。因此分词的平均长度为 3.8 。作者还测量了词语(word)中的分词程度,使得添加掩膜的分词更长。图2展示了分词掩膜长度的分布情况。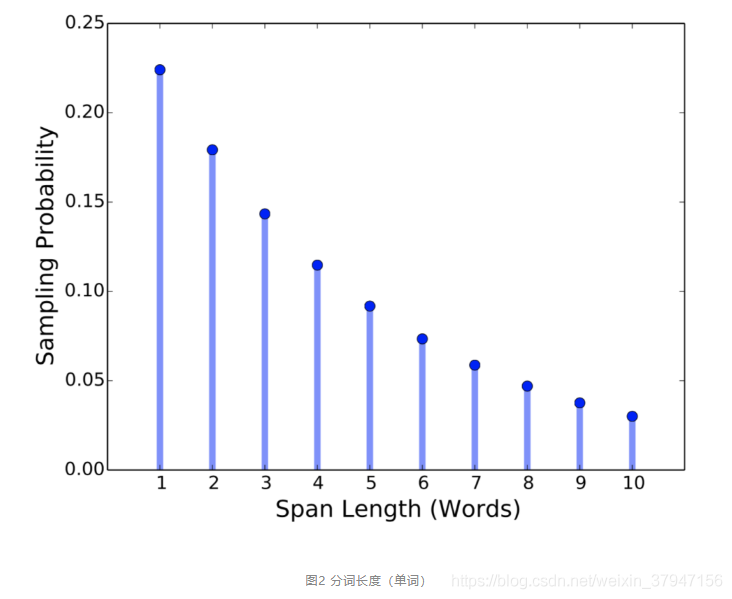
和在 BERT 中一样,作者将 Y 的规模设定为 X 的15%,其中 80% 使用 [MASK] 进行替换,10% 使用随机单词替换,10%保持不变。与之不同的是,作者是在分词级别进行的这一替换,而非将每个单词单独替换。
SBO任务(Span Boundary Objective)
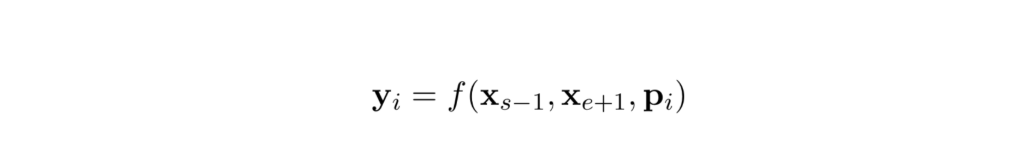

简单来说,也就是把边界的token的表示和位置向量一起过两层的激活函数为GeLU的FC前馈网络,再加上layer normalization。
具体来说,希望通过被盖住范围的左右两边的输出,去预测被盖住的范围内有什么样的东西。在训练时取 Span 前后边界的两个词,值得指出,这两个词不在 Span 内,然后用这两个词向量加上 Span 中被遮盖掉词的位置向量,来预测原词。
损失函数
损失函数是交叉熵类型,把MLM阶段的和SBO阶段的加在一起。
也就是每个词有两个过程的预测,第一个过程是基于span-MLM上下文预测,第二个过程是位置和span的boundary来进行预测
单序列训练
根本不加入 NSP 任务来判断是否两句是上下句,直接用一句来训练。作者推测其可能原因如下:(a)更长的语境对模型更有利,模型可以获得更长上下文(类似 XLNet 的一部分效果;(b)加入另一个文本的语境信息会给MLM 语言模型带来噪音。
因此,SpanBERT 就没采用 NSP 任务,仅采样一个单独的邻接片段,该片段长度最多为512个单词,其长度与 BERT 使用的两片段的最大长度总和相同,然后 MLM 加上 SBO 任务来进行预训练。
其他细节
- 训练时用了 Dynamic Masking 而不是像 BERT 在预处理时做 Mask;
- 取消 BERT 中随机采样短句的策略;
- 还有对 Adam 优化器中一些参数改变。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号